MultiClaimNet: A Massively Multilingual Dataset of Fact-Checked Claim Clusters
作者: Rrubaa Panchendrarajan, Rubén Míguez, Arkaitz Zubiaga
分类: cs.CL
发布日期: 2025-03-28
💡 一句话要点
提出MultiClaimNet,一个大规模多语种事实核查声明聚类数据集,促进高效事实核查。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事实核查 声明聚类 多语种数据集 自然语言处理 大型语言模型
📋 核心要点
- 现有事实核查面临海量重复声明,传统检索方法效率低下,亟需更高效的解决方案。
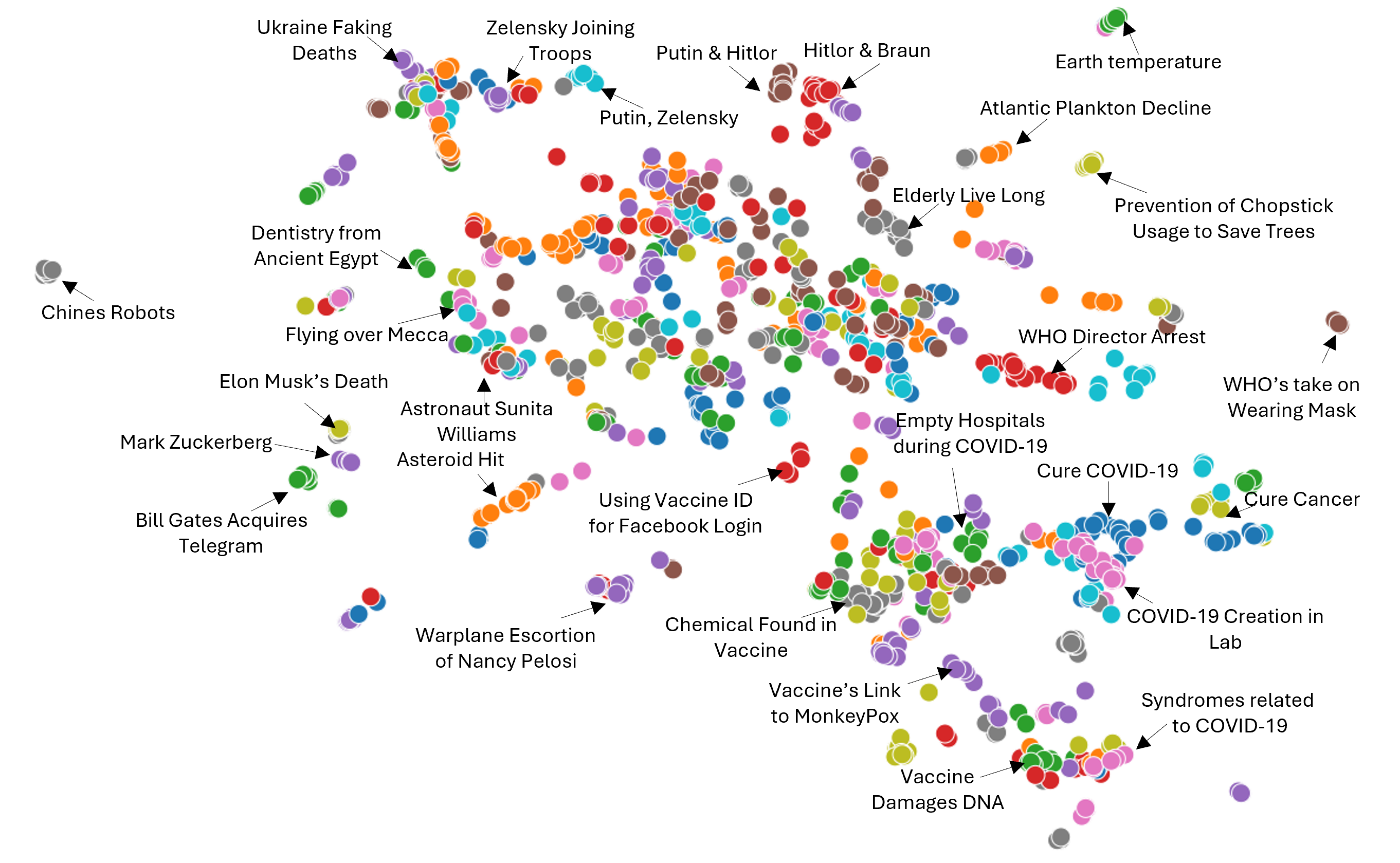
- MultiClaimNet通过聚类讨论相同事实的声明,减少冗余,提升声明检索和验证效率。
- 该数据集包含86种语言的声明,规模庞大,并提供了基线性能,为声明聚类研究奠定基础。
📝 摘要(中文)
在事实核查的背景下,声明经常在不同平台和语言中重复出现,这可以通过减少冗余的过程来获益。虽然检索先前经过事实核查的声明已被研究作为一种解决方案,但未经验证的声明数量不断增长以及事实核查数据库的规模扩大,需要替代的、更有效的解决方案。一个有希望的解决方案是将讨论相同底层事实的声明分组到集群中,以改进声明检索和验证。然而,由于缺乏合适的数据集,对声明聚类的研究受到阻碍。为了弥合这一差距,我们引入了 extit{MultiClaimNet},这是一个包含三个多语种声明聚类数据集的集合,其中包含86种语言的各种主题的声明。声明集群由声明匹配对自动形成,人工干预有限。我们利用两个现有的声明匹配数据集来形成 extit{MultiClaimNet}中较小的数据集。为了构建更大的数据集,我们提出并验证了一种方法,该方法涉及检索近似最近邻以形成候选声明对,并使用大型语言模型自动注释声明相似性。这个更大的数据集包含85.3K个用78种语言编写的经过事实核查的声明。我们进一步使用各种聚类技术和句子嵌入模型进行广泛的实验,以建立基线性能。我们的数据集和发现为可扩展的声明聚类提供了坚实的基础,有助于高效的事实核查流程。
🔬 方法详解
问题定义:论文旨在解决大规模多语言环境下事实核查中声明冗余的问题。现有方法,如直接检索已核查声明,在大规模数据面前效率低下,无法满足日益增长的需求。因此,需要一种更高效的方法来组织和处理这些声明。
核心思路:论文的核心思路是将讨论相同底层事实的声明进行聚类。通过将相似的声明归为一类,可以减少冗余,提高检索效率,并为事实核查提供更全面的信息。这种聚类方法能够有效地组织大规模的声明数据,从而加速事实核查过程。
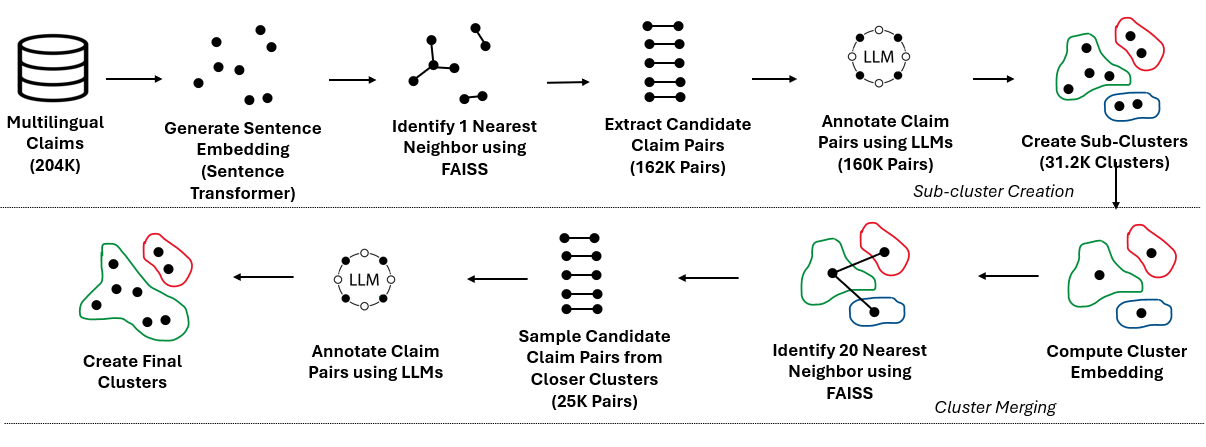
技术框架:MultiClaimNet的构建主要包含以下几个阶段:1) 利用现有的声明匹配数据集构建较小规模的数据集。2) 提出一种基于近似最近邻检索的方法,用于生成候选声明对。3) 使用大型语言模型自动标注声明的相似性,从而构建更大规模的数据集。整个流程旨在自动化地构建大规模、多语言的声明聚类数据集。
关键创新:该论文的关键创新在于提出了一种利用大型语言模型自动标注声明相似性的方法。这种方法能够有效地处理大规模的声明数据,并生成高质量的声明聚类。此外,该数据集的多语言特性也是一个重要的创新点,使其能够应用于更广泛的场景。
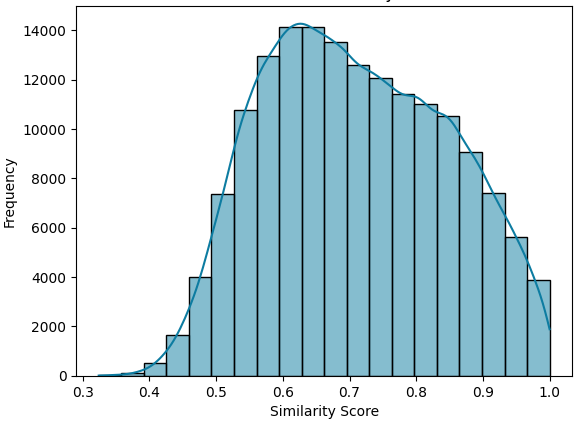
关键设计:在构建大规模数据集时,论文采用了近似最近邻检索来减少计算量,提高效率。同时,利用大型语言模型进行相似性标注,可以充分利用预训练模型的知识,提高标注的准确性。具体的参数设置和模型选择在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
论文构建了一个包含86种语言,超过8.5万条事实核查声明的大规模多语种数据集MultiClaimNet。通过实验,论文使用多种聚类技术和句子嵌入模型建立了基线性能,为后续研究提供了参考。该数据集的发布将极大地促进声明聚类和事实核查领域的研究。
🎯 应用场景
MultiClaimNet数据集可广泛应用于自动化事实核查系统、虚假信息检测、舆情分析等领域。通过对声明进行聚类,可以快速识别和验证重复出现的虚假信息,提高信息传播的透明度和可信度。该数据集的发布将促进相关领域的研究和应用,为构建更健康的网络信息生态做出贡献。
📄 摘要(原文)
In the context of fact-checking, claims are often repeated across various platforms and in different languages, which can benefit from a process that reduces this redundancy. While retrieving previously fact-checked claims has been investigated as a solution, the growing number of unverified claims and expanding size of fact-checked databases calls for alternative, more efficient solutions. A promising solution is to group claims that discuss the same underlying facts into clusters to improve claim retrieval and validation. However, research on claim clustering is hindered by the lack of suitable datasets. To bridge this gap, we introduce \textit{MultiClaimNet}, a collection of three multilingual claim cluster datasets containing claims in 86 languages across diverse topics. Claim clusters are formed automatically from claim-matching pairs with limited manual intervention. We leverage two existing claim-matching datasets to form the smaller datasets within \textit{MultiClaimNet}. To build the larger dataset, we propose and validate an approach involving retrieval of approximate nearest neighbors to form candidate claim pairs and an automated annotation of claim similarity using large language models. This larger dataset contains 85.3K fact-checked claims written in 78 languages. We further conduct extensive experiments using various clustering techniques and sentence embedding models to establish baseline performance. Our datasets and findings provide a strong foundation for scalable claim clustering, contributing to efficient fact-checking pipelines.