Boosting Large Language Models with Mask Fine-Tuning
作者: Mingyuan Zhang, Yue Bai, Huan Wang, Yizhou Wang, Qihua Dong, Yun Fu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-27
💡 一句话要点
提出Mask Fine-Tuning,通过掩码微调显著提升大语言模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 微调 掩码学习 模型优化 参数选择
📋 核心要点
- 现有LLM微调方法通常保持模型完整性,忽略了打破完整性可能带来的性能提升。
- MFT通过学习二元掩码,选择性地更新模型参数,在标准微调目标下优化。
- 实验表明,MFT在多种LLM和任务上均能稳定提升性能,例如编码任务。
📝 摘要(中文)
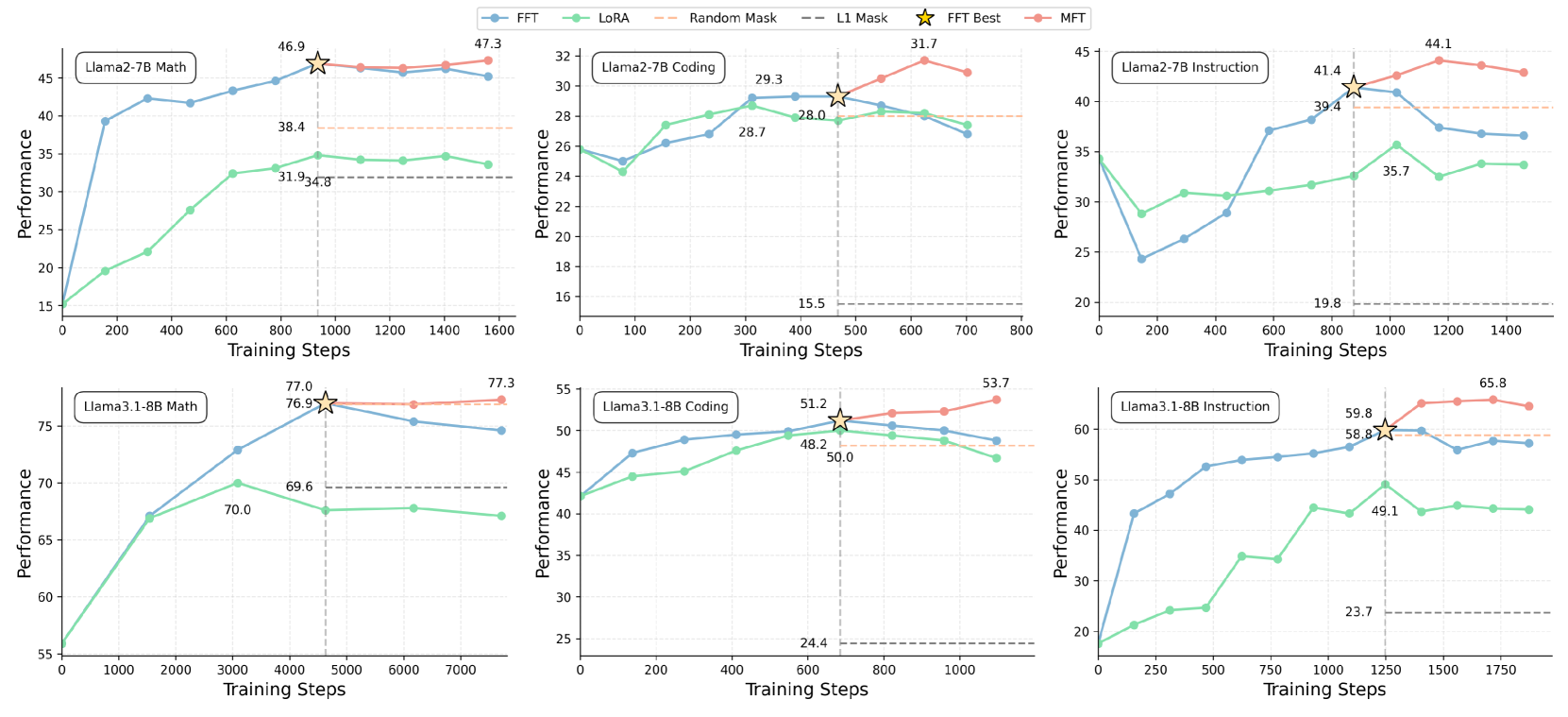
本文提出了一种全新的大语言模型(LLM)微调范式——掩码微调(Mask Fine-Tuning, MFT)。与主流微调方法保持模型完整性不同,MFT通过学习一组二元掩码,并在典型LLM微调目标函数的监督下进行训练,从而打破模型的完整性。大量实验表明,MFT在各种领域和骨干网络上均能获得一致的性能提升(例如,在使用LLaMA2-7B/3.1-8B进行编码任务时,平均增益分别为1.95%/1.88%)。本文还详细研究了不同超参数对MFT的影响,以获得更深入的理解。MFT通过将其部署在完全训练好的模型上,自然地更新了当前的LLM训练协议。这项研究将掩码学习的功能从传统的网络剪枝(用于模型压缩)扩展到更广泛的范围。
🔬 方法详解
问题定义:现有大语言模型微调方法通常保持模型结构的完整性,即所有参数都参与更新。这种方式可能存在冗余,并非所有参数都需要同等程度的调整。论文旨在探索打破模型完整性,选择性地更新参数,是否能提升模型性能。现有方法的痛点在于缺乏对模型参数重要性的区分,可能导致微调效率低下和性能瓶颈。
核心思路:论文的核心思路是通过引入可学习的二元掩码(binary masks),对模型参数进行选择性更新。掩码决定了哪些参数参与梯度更新,哪些参数保持不变。通过在标准LLM微调目标函数的监督下学习这些掩码,模型能够自动识别并优化最重要的参数,从而提高微调效率和最终性能。
技术框架:MFT的整体框架是在预训练好的LLM基础上,为每一层或每一组参数引入一个二元掩码。在微调过程中,只有掩码值为1的参数才参与梯度更新,掩码值为0的参数则保持不变。掩码本身也是可学习的,通过反向传播进行优化。整个训练过程与标准的LLM微调类似,只是在计算梯度时需要考虑掩码的影响。
关键创新:MFT的关键创新在于将掩码学习从传统的模型压缩(网络剪枝)领域扩展到模型微调领域。与剪枝不同,MFT并非直接移除不重要的参数,而是通过掩码控制参数的更新,从而在微调过程中动态地调整模型结构。这种方法允许模型在保持大部分参数不变的情况下,专注于优化关键参数,从而提高微调效率和性能。
关键设计:MFT的关键设计包括:1) 二元掩码的初始化策略(例如,随机初始化或全1初始化);2) 掩码的学习率;3) 掩码的正则化项(例如,L1正则化,鼓励稀疏性);4) 掩码的应用粒度(例如,层级别、参数组级别)。损失函数是标准的LLM微调目标函数,例如交叉熵损失。网络结构与原始LLM保持一致,只是增加了掩码层。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MFT在多个LLM(例如LLaMA2-7B/3.1-8B)和任务上均能获得显著的性能提升。例如,在使用LLaMA2-7B/3.1-8B进行编码任务时,MFT的平均增益分别为1.95%/1.88%。此外,实验还验证了MFT对不同超参数的鲁棒性,并分析了掩码的稀疏性和性能之间的关系。
🎯 应用场景
MFT可应用于各种大语言模型的微调场景,尤其适用于资源受限或需要快速迭代的场景。通过选择性地更新参数,MFT可以降低计算成本和内存需求,提高微调效率。此外,MFT还可以用于模型压缩,通过学习稀疏掩码来减小模型大小。未来,MFT有望成为一种通用的LLM微调方法,广泛应用于自然语言处理、代码生成、对话系统等领域。
📄 摘要(原文)
The model is usually kept integral in the mainstream large language model (LLM) fine-tuning protocols. No works have questioned whether maintaining the integrity of the model is indispensable for performance. In this work, we introduce Mask Fine-Tuning (MFT), a brand-new LLM fine-tuning paradigm to show that properly breaking the integrity of the model can surprisingly lead to improved performance. Specifically, MFT learns a set of binary masks supervised by the typical LLM fine-tuning objective. Extensive experiments show that MFT gains a consistent performance boost across various domains and backbones (e.g., 1.95%/1.88% average gain in coding with LLaMA2-7B/3.1-8B). Detailed procedures are provided to study the proposed MFT from different hyperparameter perspectives for better insight. In particular, MFT naturally updates the current LLM training protocol by deploying it on a complete well-trained model. This study extends the functionality of mask learning from its conventional network pruning context for model compression to a more general scope.