ThinkEdit: Interpretable Weight Editing to Mitigate Overly Short Thinking in Reasoning Models
作者: Chung-En Sun, Ge Yan, Tsui-Wei Weng
分类: cs.CL, cs.LG
发布日期: 2025-03-27 (更新: 2025-09-29)
备注: Accepted to EMNLP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
ThinkEdit:通过可解释的权重编辑缓解推理模型中的过度短推理问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 思维链推理 权重编辑 可解释性 模型干预
📋 核心要点
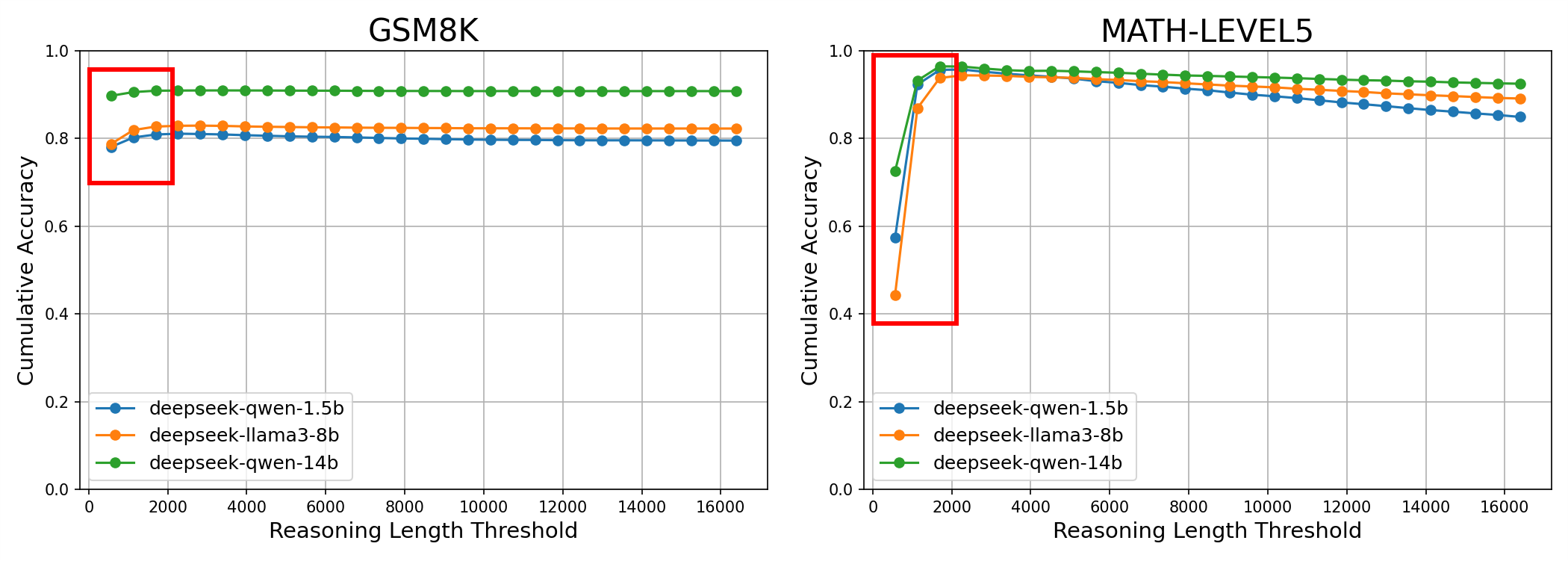
- 大型语言模型在思维链推理中存在过度短推理问题,导致在简单数学问题上性能下降。
- 通过分析模型表示空间,发现推理长度由线性方向控制,并提出ThinkEdit权重编辑方法。
- ThinkEdit通过编辑少量注意力头的权重,有效减少短推理,并在数学基准测试中提升了模型准确性。
📝 摘要(中文)
最近的研究表明,通过思维链(CoT)推理增强的大型语言模型(LLM)展现出令人印象深刻的问题解决能力。然而,本文发现了一个反复出现的问题,即这些模型偶尔会产生过度短的推理,导致即使在简单的数学问题上性能也会下降。具体来说,我们研究了推理长度是如何嵌入到推理模型的隐藏表示中的,以及它对准确性的影响。我们的分析表明,推理长度受表示空间中的线性方向控制,这使得我们能够通过沿着这个方向引导模型来诱导过度短的推理。在此基础上,我们提出了一种简单而有效的权重编辑方法ThinkEdit,以缓解过度短推理的问题。我们首先识别出一小部分主要驱动短推理行为的注意力头(约4%)。然后,我们编辑这些头的输出投影权重,以消除短推理方向。仅更改模型0.2%的参数,ThinkEdit有效地减少了过度短推理,并为短推理输出带来了显著的准确性提升(+6.39%),以及在多个数学基准测试中的整体改进(+3.34%)。我们的发现为推理长度如何在LLM中被控制提供了新的机制性见解,并突出了细粒度模型干预在提高推理质量方面的潜力。我们的代码可在https://github.com/Trustworthy-ML-Lab/ThinkEdit 获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在进行思维链推理时出现的“过度短推理”问题。现有方法在处理需要多步推理的简单数学问题时,由于模型过早停止推理,导致性能显著下降。这种现象表明模型对推理长度的控制存在缺陷,需要进行改进。
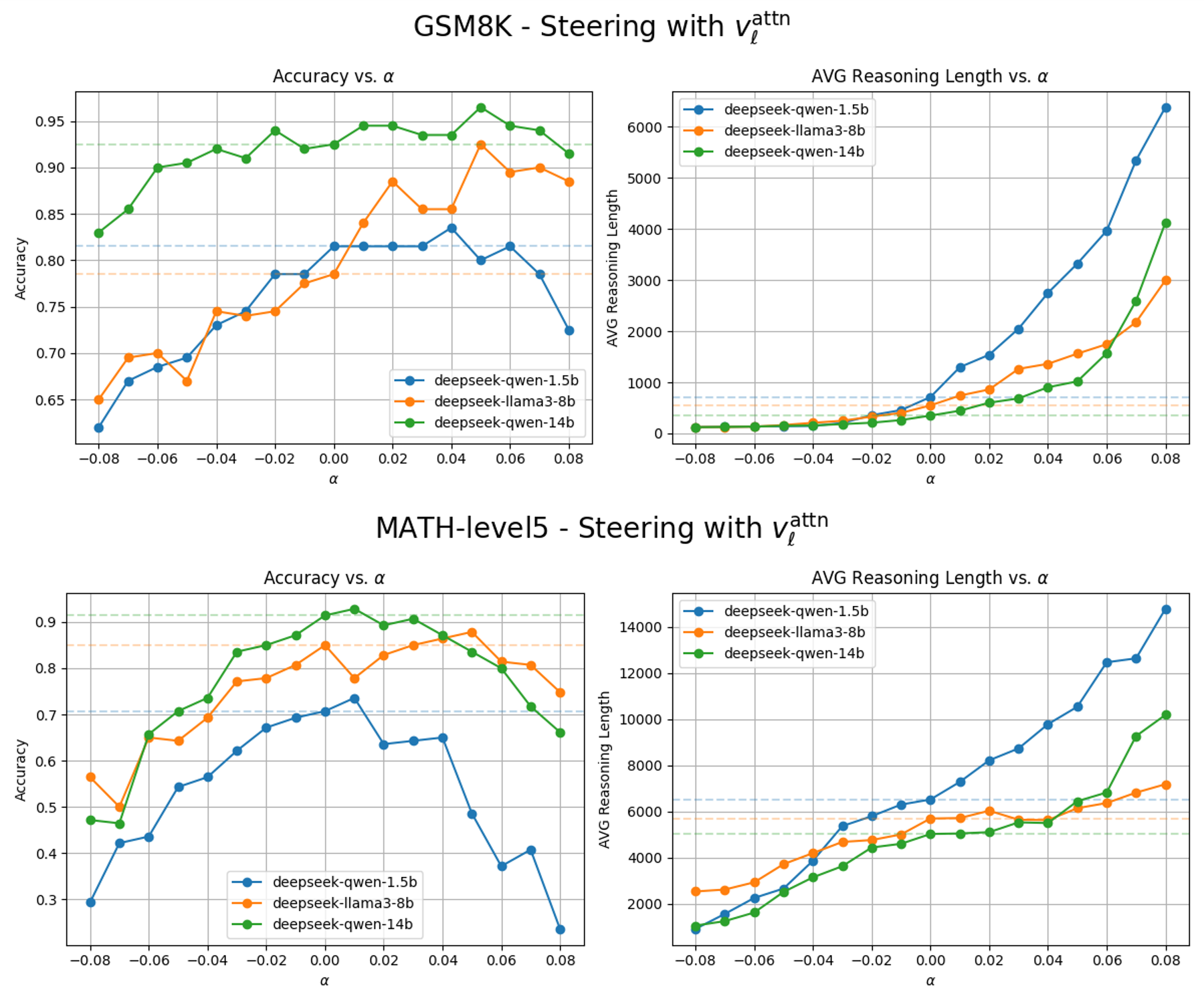
核心思路:论文的核心思路是识别并干预模型内部控制推理长度的关键组件。通过分析模型的隐藏层表示,发现推理长度与表示空间中的一个线性方向相关。因此,可以通过操纵这个方向来控制推理长度,从而缓解过度短推理的问题。
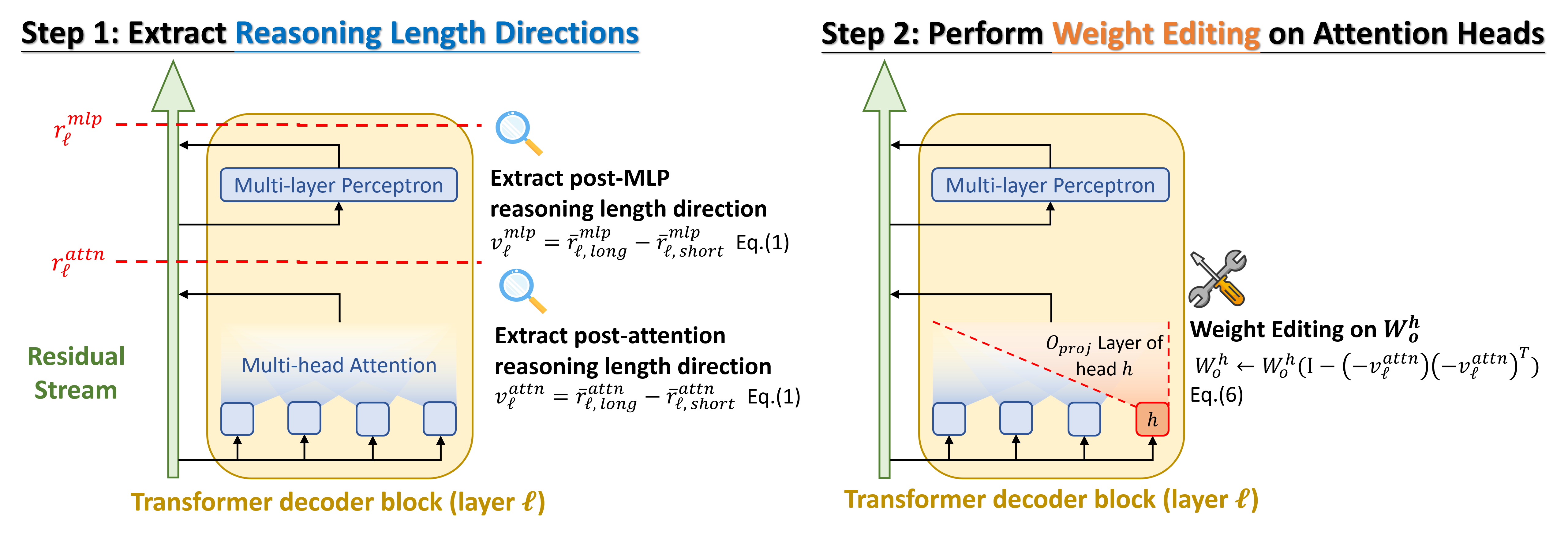
技术框架:ThinkEdit方法主要包含两个阶段:1) 注意力头识别:通过分析模型在生成推理链时的激活模式,识别出对短推理行为贡献最大的少量注意力头。2) 权重编辑:对这些注意力头的输出投影权重进行编辑,以消除或减弱短推理方向的影响。整个过程无需重新训练模型,属于一种轻量级的模型干预方法。
关键创新:ThinkEdit的关键创新在于它提供了一种可解释的权重编辑方法,能够针对性地干预模型内部的推理长度控制机制。与传统的微调方法相比,ThinkEdit只需要修改极少量的模型参数,就能取得显著的性能提升,同时保持了模型的可解释性。
关键设计:论文的关键设计包括:1) 使用线性探针识别推理长度方向;2) 设计指标来评估注意力头对短推理的贡献;3) 使用奇异值分解(SVD)来编辑注意力头的输出投影权重,以消除短推理方向。具体来说,通过SVD分解权重矩阵,然后将与短推理方向相关的奇异值设置为零,从而达到消除短推理方向的目的。
🖼️ 关键图片
📊 实验亮点
ThinkEdit方法通过修改仅0.2%的模型参数,在短推理输出上实现了6.39%的准确率提升,并在多个数学基准测试中取得了3.34%的整体性能提升。实验结果表明,该方法能够有效地减少过度短推理,并显著提高模型在数学问题求解任务上的性能。此外,论文还提供了对LLM内部推理长度控制机制的深入见解。
🎯 应用场景
ThinkEdit方法具有广泛的应用前景,可以应用于各种需要复杂推理的大型语言模型中,例如数学问题求解、代码生成、知识问答等。通过缓解过度短推理问题,可以提高模型在这些任务上的准确性和可靠性。此外,该方法还可以作为一种通用的模型干预技术,用于调试和优化大型语言模型的推理行为。
📄 摘要(原文)
Recent studies have shown that Large Language Models (LLMs) augmented with chain-of-thought (CoT) reasoning demonstrate impressive problem-solving abilities. However, in this work, we identify a recurring issue where these models occasionally generate overly short reasoning, leading to degraded performance on even simple mathematical problems. Specifically, we investigate how reasoning length is embedded in the hidden representations of reasoning models and its impact on accuracy. Our analysis reveals that reasoning length is governed by a linear direction in the representation space, allowing us to induce overly short reasoning by steering the model along this direction. Building on this insight, we introduce ThinkEdit, a simple yet effective weight-editing approach to mitigate the issue of overly short reasoning. We first identify a small subset of attention heads (approximately 4%) that predominantly drive short reasoning behavior. We then edit the output projection weights of these heads to remove the short reasoning direction. With changes to only 0.2% of the model's parameters, ThinkEdit effectively reduces overly short reasoning and yields notable accuracy gains for short reasoning outputs (+6.39%), along with an overall improvement across multiple math benchmarks (+3.34%). Our findings provide new mechanistic insights into how reasoning length is controlled within LLMs and highlight the potential of fine-grained model interventions to improve reasoning quality. Our code is available at: https://github.com/Trustworthy-ML-Lab/ThinkEdit