Debate-Driven Multi-Agent LLMs for Phishing Email Detection
作者: Ngoc Tuong Vy Nguyen, Felix D Childress, Yunting Yin
分类: cs.MA, cs.CL
发布日期: 2025-03-27
备注: Accepted to the 13th International Symposium on Digital Forensics and Security (ISDFS 2025)
期刊: 2025 13th International Symposium on Digital Forensics and Security (ISDFS)
DOI: 10.1109/ISDFS65363.2025.11012014
💡 一句话要点
提出基于辩论驱动的多Agent LLM钓鱼邮件检测方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 钓鱼邮件检测 多Agent系统 大型语言模型 辩论机制 网络安全 自然语言处理
📋 核心要点
- 现有钓鱼邮件检测方法依赖预定义规则或有监督学习,易被绕过且需大量数据,泛化性不足。
- 论文提出一种基于多Agent LLM的辩论框架,通过模拟Agent间的辩论来识别钓鱼邮件。
- 实验表明,该框架在多个数据集上表现出色,混合Agent配置优于同构配置,无需额外提示策略。
📝 摘要(中文)
钓鱼攻击仍然是严重的网络安全威胁。攻击者不断改进方法,使得钓鱼邮件更难检测。传统的检测方法,包括基于规则的系统和监督机器学习模型,要么依赖于预定义的模式(如黑名单),这些模式可以通过细微的修改来绕过,要么需要大型数据集进行训练,并且仍然会产生假阳性和假阴性。本文提出了一种多Agent大型语言模型(LLM)提示技术,该技术模拟Agent之间的辩论,以检测电子邮件上呈现的内容是否为钓鱼内容。我们的方法使用两个LLM Agent来提出支持或反对分类任务的论点,并由一个裁判Agent根据所提供的推理质量来裁决最终结果。这种辩论机制使模型能够批判性地分析文本中的上下文线索和欺骗模式,从而提高分类准确性。所提出的框架在多个钓鱼邮件数据集上进行了评估,结果表明混合Agent配置始终优于同构配置。结果还表明,辩论结构本身足以产生准确的决策,而无需额外的提示策略。
🔬 方法详解
问题定义:钓鱼邮件检测旨在识别具有欺骗性的电子邮件,传统方法如规则引擎和监督学习模型存在局限性。规则引擎依赖人工定义的规则,容易被攻击者绕过;监督学习模型需要大量标注数据,且泛化能力有限,难以应对不断演变的攻击手段。
核心思路:论文的核心思路是利用多Agent LLM模拟辩论过程,让不同的Agent从不同角度分析邮件内容,通过辩论来挖掘隐藏的欺骗模式。这种方法旨在提高模型对上下文信息的理解能力,从而更准确地识别钓鱼邮件。
技术框架:该框架包含三个主要Agent:支持Agent、反对Agent和裁判Agent。支持Agent负责提出邮件是钓鱼邮件的论据;反对Agent负责提出邮件不是钓鱼邮件的论据;裁判Agent负责评估两个Agent的论据,并给出最终的判断结果。整个流程模拟了一个辩论过程,旨在通过多角度分析提高识别准确率。
关键创新:该方法的核心创新在于引入了辩论机制,利用多Agent LLM的推理能力,模拟人类专家对钓鱼邮件的分析过程。与传统的单Agent方法相比,辩论机制可以更全面地考虑各种因素,从而提高识别准确率。此外,混合Agent配置(使用不同类型的LLM)进一步提升了性能。
关键设计:论文的关键设计包括Agent的角色分配、辩论的轮次、以及裁判Agent的决策机制。具体参数设置和损失函数未知,网络结构也未详细说明,但强调了Agent之间的协作和推理能力。
🖼️ 关键图片
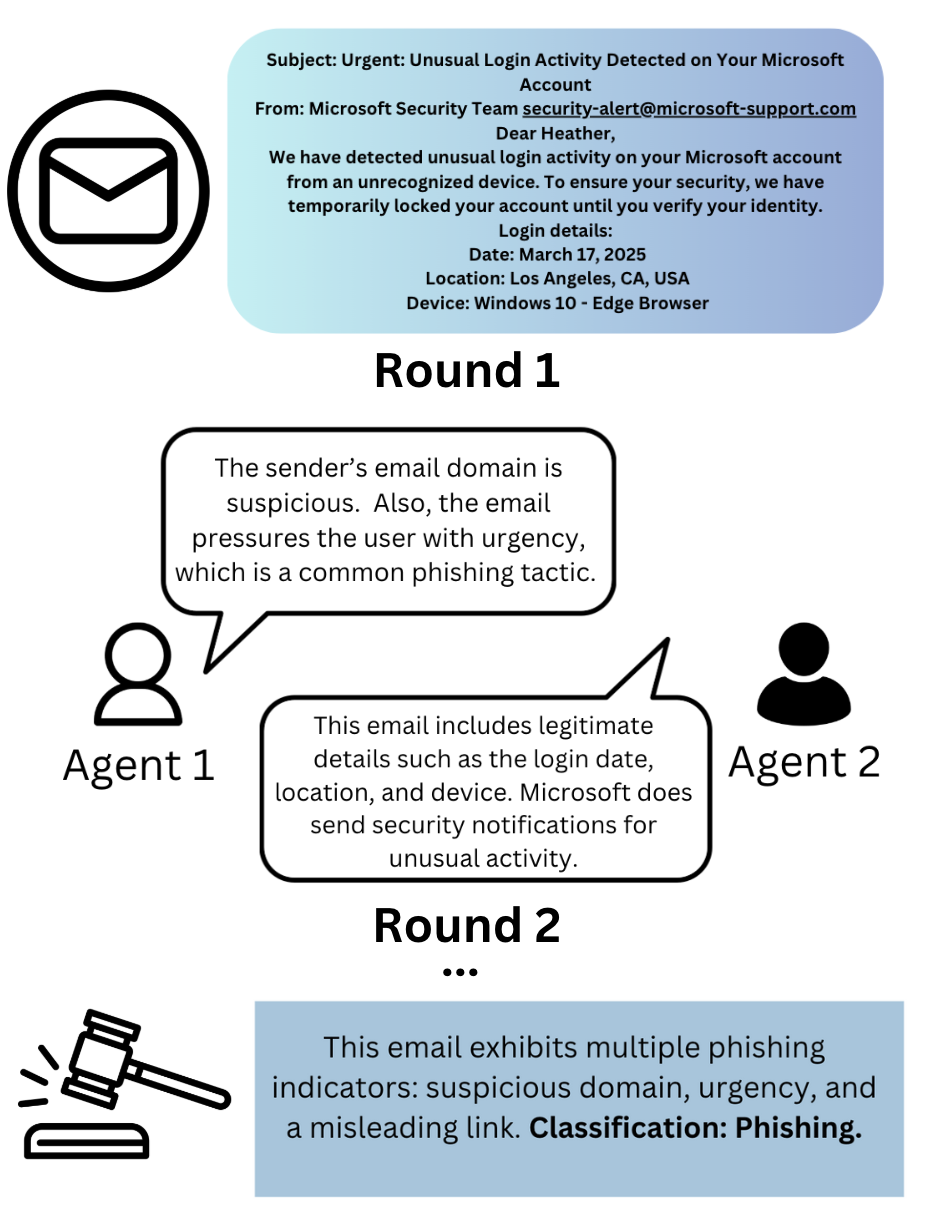
📊 实验亮点
实验结果表明,该方法在多个钓鱼邮件数据集上取得了优异的性能,混合Agent配置始终优于同构配置,证明了辩论机制的有效性。更重要的是,即使没有额外的提示策略,辩论结构本身也足以产生准确的决策。
🎯 应用场景
该研究成果可应用于企业和个人的邮件安全防护系统,提高钓鱼邮件的检测准确率,减少网络安全风险。未来,该方法可以扩展到其他网络安全领域,例如恶意软件检测、虚假信息识别等,具有广阔的应用前景。
📄 摘要(原文)
Phishing attacks remain a critical cybersecurity threat. Attackers constantly refine their methods, making phishing emails harder to detect. Traditional detection methods, including rule-based systems and supervised machine learning models, either rely on predefined patterns like blacklists, which can be bypassed with slight modifications, or require large datasets for training and still can generate false positives and false negatives. In this work, we propose a multi-agent large language model (LLM) prompting technique that simulates debates among agents to detect whether the content presented on an email is phishing. Our approach uses two LLM agents to present arguments for or against the classification task, with a judge agent adjudicating the final verdict based on the quality of reasoning provided. This debate mechanism enables the models to critically analyze contextual cue and deceptive patterns in text, which leads to improved classification accuracy. The proposed framework is evaluated on multiple phishing email datasets and demonstrate that mixed-agent configurations consistently outperform homogeneous configurations. Results also show that the debate structure itself is sufficient to yield accurate decisions without extra prompting strategies.