A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyond
作者: Xiaoye Qu, Yafu Li, Zhao-Chen Su, Weigao Sun, Jianhao Yan, Dongrui Liu, Ganqu Cui, Daizong Liu, Shuxian Liang, Junxian He, Peng Li, Wei Wei, Jing Shao, Chaochao Lu, Yue Zhang, Xian-Sheng Hua, Bowen Zhou, Yu Cheng
分类: cs.CL
发布日期: 2025-03-27 (更新: 2025-12-31)
备注: Update recent RL papers. Project page: https://github.com/XiaoYee/Awesome_Efficient_LRM_Reasoning
💡 一句话要点
综述高效推理:针对大型推理模型中语言、多模态及其他方面的推理效率提升方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型推理模型 推理效率 思维链 知识蒸馏 模型压缩 多模态推理 动态推理 综述
📋 核心要点
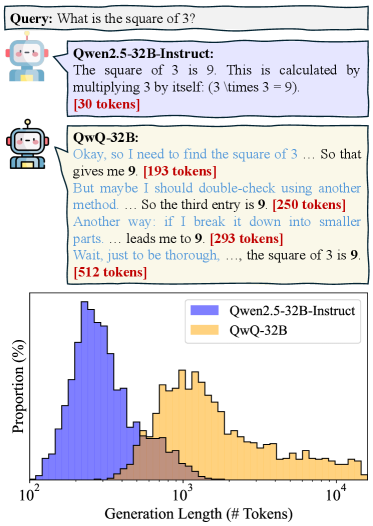
- 现有大型推理模型存在推理过程冗长、效率低下的问题,包含过多重复信息和不必要的分析。
- 该综述旨在全面回顾提升大型推理模型推理效率的方法,涵盖预训练到推理的整个生命周期。
- 论文维护了一个GitHub仓库,实时跟踪该领域最新进展,为后续研究提供基础和灵感。
📝 摘要(中文)
近期的大型推理模型(LRM),如DeepSeek-R1和OpenAI o1,通过扩展推理过程中的思维链(CoT)长度,展现了强大的性能提升。然而,一个日益增长的担忧是它们倾向于产生过长的推理轨迹,其中常常包含冗余内容(例如,重复的定义)、对简单问题的过度分析以及对困难任务的肤浅推理路径探索。这种低效性为训练、推理和实际部署(例如,在基于代理的系统中)带来了重大挑战,在这些场景中,token经济性至关重要。本综述全面概述了近期旨在提高LRM推理效率的工作,特别关注在这种新范式中出现的独特挑战。我们识别了常见的低效模式,考察了在LRM生命周期(即从预训练到推理)中提出的方法,并讨论了有希望的未来研究方向。为了支持正在进行的开发,我们还维护了一个实时的GitHub存储库,跟踪该领域的最新进展。我们希望这篇综述能够为进一步探索奠定基础,并激发这个快速发展领域的创新。
🔬 方法详解
问题定义:论文旨在解决大型推理模型(LRM)在推理过程中效率低下的问题。现有方法,如扩展思维链(CoT)长度,虽然提升了性能,但导致推理轨迹过长,包含冗余信息,对简单问题过度分析,对复杂问题探索不足,造成token浪费,阻碍了训练、推理和实际部署。
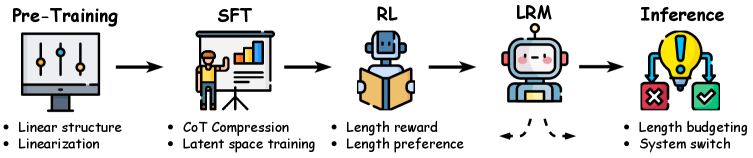
核心思路:核心思路是系统性地分析LRM推理效率低下的原因,并从LRM的整个生命周期(预训练、微调、推理等)寻找提升效率的方法。通过识别低效模式,并针对性地提出解决方案,从而在保证性能的同时,降低计算成本和资源消耗。
技术框架:该综述没有提出新的技术框架,而是对现有方法进行了分类和总结。它将提升推理效率的方法按照LRM的生命周期阶段进行组织,包括:预训练阶段的知识压缩和高效表示学习;微调阶段的针对性训练和奖励塑造;推理阶段的动态推理路径选择和知识检索等。此外,还讨论了多模态推理中的效率问题。
关键创新:该综述的关键创新在于其系统性和全面性。它首次对LRM推理效率问题进行了全面的梳理,识别了常见的低效模式,并从LRM的整个生命周期角度考察了现有方法。这为未来的研究提供了清晰的路线图和有价值的参考。
关键设计:该综述本身没有涉及具体的技术细节,而是对现有方法的关键设计进行了总结和分析。例如,在预训练阶段,关键设计包括知识蒸馏、模型剪枝等;在推理阶段,关键设计包括动态规划、蒙特卡洛树搜索等。
🖼️ 关键图片

📊 实验亮点
该综述论文本身没有实验结果,但它总结了大量现有研究的成果。例如,一些研究表明,通过知识蒸馏可以将大型模型的参数量减少数倍,同时保持甚至提高性能。另一些研究表明,通过动态推理路径选择可以显著减少推理所需的token数量,从而提高效率。
🎯 应用场景
该研究成果可应用于各种需要高效推理的场景,例如智能客服、自动驾驶、机器人控制、智能搜索等。通过提高推理效率,可以降低计算成本,提升响应速度,并使LRM能够在资源受限的环境中部署。此外,该研究还有助于开发更智能、更可靠的AI代理。
📄 摘要(原文)
Recent Large Reasoning Models (LRMs), such as DeepSeek-R1 and OpenAI o1, have demonstrated strong performance gains by scaling up the length of Chain-of-Thought (CoT) reasoning during inference. However, a growing concern lies in their tendency to produce excessively long reasoning traces, which are often filled with redundant content (e.g., repeated definitions), over-analysis of simple problems, and superficial exploration of multiple reasoning paths for harder tasks. This inefficiency introduces significant challenges for training, inference, and real-world deployment (e.g., in agent-based systems), where token economy is critical. In this survey, we provide a comprehensive overview of recent efforts aimed at improving reasoning efficiency in LRMs, with a particular focus on the unique challenges that arise in this new paradigm. We identify common patterns of inefficiency, examine methods proposed across the LRM lifecycle, i.e., from pretraining to inference, and discuss promising future directions for research. To support ongoing development, we also maintain a real-time GitHub repository tracking recent progress in the field. We hope this survey serves as a foundation for further exploration and inspires innovation in this rapidly evolving area.