OpenHuEval: Evaluating Large Language Model on Hungarian Specifics
作者: Haote Yang, Xingjian Wei, Jiang Wu, Noémi Ligeti-Nagy, Jiaxing Sun, Yinfan Wang, Zijian Győző Yang, Junyuan Gao, Jingchao Wang, Bowen Jiang, Shasha Wang, Nanjun Yu, Zihao Zhang, Shixin Hong, Hongwei Liu, Wei Li, Songyang Zhang, Dahua Lin, Lijun Wu, Gábor Prószéky, Conghui He
分类: cs.CL
发布日期: 2025-03-27 (更新: 2025-08-25)
🔗 代码/项目: GITHUB
💡 一句话要点
提出OpenHuEval,首个面向匈牙利语及特定文化的LLM评测基准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM评估 匈牙利语 评测基准 多语言模型 LLM-as-judge
📋 核心要点
- 现有LLM在匈牙利语及文化背景下的性能评估不足,缺乏专门的评测基准。
- 构建OpenHuEval,利用真实用户查询和LLM-as-judge,全面评估LLM的生成能力和多维度性能。
- 实验结果表明,现有LLM在匈牙利语特定任务上表现欠佳,亟需针对性优化,并分析了LRM在非英语语言中的思维模式。
📝 摘要(中文)
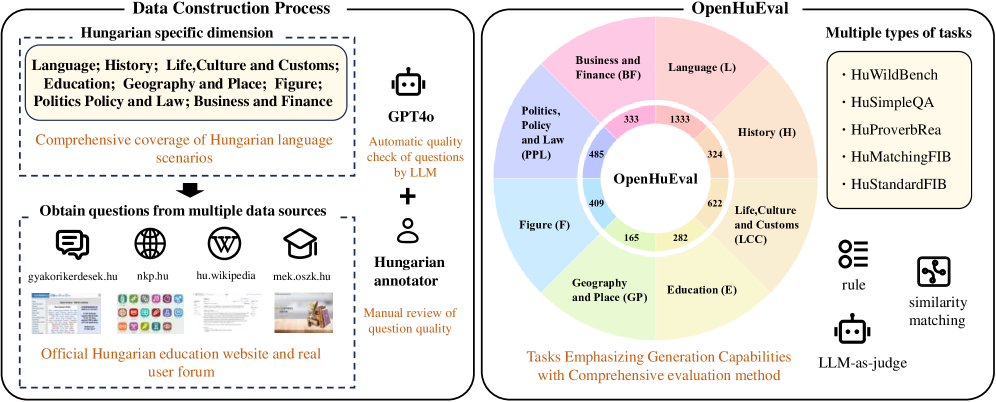
本文介绍了OpenHuEval,这是首个专注于匈牙利语和特定文化的LLM评测基准。OpenHuEval构建于大量源自多个渠道的匈牙利语特定材料之上。在构建过程中,我们融入了最新的LLM评估设计原则,例如使用来自互联网的真实用户查询,强调评估LLM的生成能力,并采用LLM-as-judge来增强评估的多维度和准确性。最终,OpenHuEval包含八个匈牙利语特定的维度,包括五个任务和3953个问题。因此,OpenHuEval提供了对LLM在匈牙利语及其特定文化背景下性能的全面、深入和科学准确的评估。我们评估了当前主流的LLM,包括传统的LLM和最近开发的大型推理模型。结果表明,针对匈牙利语和特定文化的评估和模型优化具有重要意义。我们还建立了使用OpenHuEval分析LRM思维过程的框架,揭示了这些模型在非英语语言中的内在模式和机制,并以匈牙利语作为代表性示例。我们将发布OpenHuEval在https://github.com/opendatalab/OpenHuEval。
🔬 方法详解
问题定义:论文旨在解决缺乏针对匈牙利语及其文化背景的LLM评测基准的问题。现有通用LLM评测基准无法充分评估LLM在处理匈牙利语特定任务时的性能,例如理解匈牙利语的语言习惯、文化典故和历史知识等。这导致无法有效指导LLM在匈牙利语环境下的应用和优化。
核心思路:论文的核心思路是构建一个专门针对匈牙利语和特定文化的LLM评测基准OpenHuEval。该基准通过收集大量的匈牙利语特定材料,并结合最新的LLM评估设计原则,例如使用真实用户查询和LLM-as-judge,来全面评估LLM在匈牙利语环境下的性能。
技术框架:OpenHuEval的整体框架包括数据收集、任务定义、评估指标和实验评估四个主要阶段。数据收集阶段从多个来源收集匈牙利语特定材料,包括互联网、书籍、新闻等。任务定义阶段根据匈牙利语的特点和文化背景,设计了五个任务,涵盖了语言理解、知识问答、文本生成等方面。评估指标阶段采用了多种评估指标,包括准确率、召回率、F1值等,并使用LLM-as-judge来增强评估的多维度和准确性。实验评估阶段使用OpenHuEval对当前主流的LLM进行评估,并分析实验结果。
关键创新:OpenHuEval的关键创新在于它是首个专门针对匈牙利语和特定文化的LLM评测基准。它采用了真实用户查询和LLM-as-judge等最新的LLM评估设计原则,并涵盖了匈牙利语的多个特定维度。与现有通用LLM评测基准相比,OpenHuEval能够更全面、深入和科学准确地评估LLM在匈牙利语环境下的性能。
关键设计:OpenHuEval包含了八个匈牙利语特定的维度,包括五个任务和3953个问题。任务包括:匈牙利语语法纠错、匈牙利语知识问答、匈牙利语文本摘要、匈牙利语情感分析和匈牙利语命名实体识别。LLM-as-judge采用GPT-4等大型语言模型作为评估者,对LLM的生成结果进行多维度评估,例如流畅性、相关性和准确性。
🖼️ 关键图片

📊 实验亮点
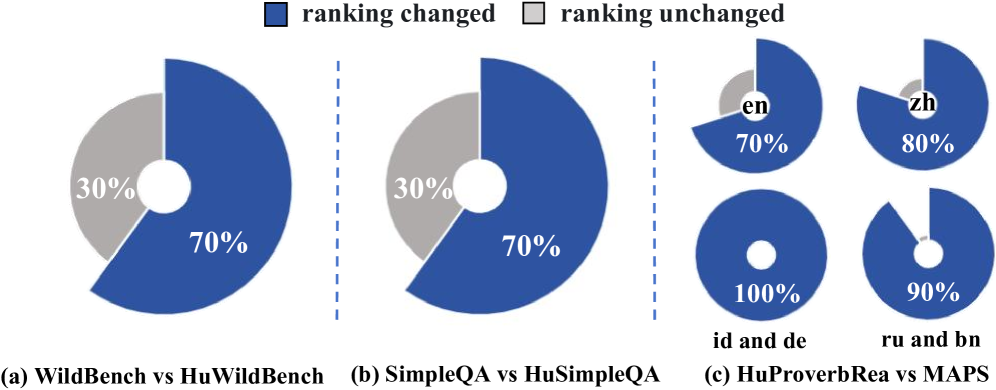
实验结果表明,现有主流LLM在OpenHuEval上的表现与通用基准存在显著差异,表明需要针对匈牙利语进行专门的评估和优化。例如,在匈牙利语知识问答任务上,部分LLM的准确率低于50%,远低于其在英语基准上的表现。
🎯 应用场景
OpenHuEval可用于评估和优化LLM在匈牙利语环境下的性能,促进LLM在匈牙利语信息检索、机器翻译、智能客服等领域的应用。该基准也可作为研究LRM在非英语语言中思维模式的工具,为多语言LLM的发展提供参考。
📄 摘要(原文)
We introduce OpenHuEval, the first benchmark for LLMs focusing on the Hungarian language and specifics. OpenHuEval is constructed from a vast collection of Hungarian-specific materials sourced from multiple origins. In the construction, we incorporated the latest design principles for evaluating LLMs, such as using real user queries from the internet, emphasizing the assessment of LLMs' generative capabilities, and employing LLM-as-judge to enhance the multidimensionality and accuracy of evaluations. Ultimately, OpenHuEval encompasses eight Hungarian-specific dimensions, featuring five tasks and 3953 questions. Consequently, OpenHuEval provides the comprehensive, in-depth, and scientifically accurate assessment of LLM performance in the context of the Hungarian language and its specifics. We evaluated current mainstream LLMs, including both traditional LLMs and recently developed Large Reasoning Models. The results demonstrate the significant necessity for evaluation and model optimization tailored to the Hungarian language and specifics. We also established the framework for analyzing the thinking processes of LRMs with OpenHuEval, revealing intrinsic patterns and mechanisms of these models in non-English languages, with Hungarian serving as a representative example. We will release OpenHuEval at https://github.com/opendatalab/OpenHuEval .