R-PRM: Reasoning-Driven Process Reward Modeling
作者: Shuaijie She, Junxiao Liu, Yifeng Liu, Jiajun Chen, Xin Huang, Shujian Huang
分类: cs.CL
发布日期: 2025-03-27
备注: The project is available at https://github.com/NJUNLP/R-PRM
💡 一句话要点
提出R-PRM:一种推理驱动的过程奖励建模方法,提升数学推理的准确性和效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 过程奖励模型 大型语言模型 数学推理 偏好优化 推理时缩放
📋 核心要点
- 现有过程奖励模型(PRMs)直接输出评估分数,导致学习效率和评估准确性受限,且依赖大量标注数据。
- R-PRM利用更强大的LLMs生成种子数据,引导模型推理能力,并通过偏好优化和推理时缩放提升性能。
- 实验表明,R-PRM在数学推理任务上显著超越现有基线,并在多个数据集上实现了超过8.5个点的准确性提升。
📝 摘要(中文)
大型语言模型(LLMs)在执行逐步数学推理时不可避免地会出错。过程奖励模型(PRMs)通过评估每个推理步骤,成为一种有前景的解决方案。然而,现有的PRMs通常直接输出评估分数,限制了学习效率和评估准确性,而标注数据的稀缺性进一步加剧了这些问题。为了解决这些问题,我们提出了推理驱动的过程奖励建模(R-PRM)。首先,我们利用更强大的LLMs从有限的标注数据中生成种子数据,有效地引导我们模型的推理能力,并实现全面的逐步评估。其次,我们通过偏好优化进一步提高性能,而无需额外的标注数据。第三,我们引入推理时缩放,以充分利用模型的推理潜力。大量的实验表明了R-PRM的有效性:在ProcessBench和PRMBench上,它分别超过了强大的基线11.9和8.5个F1分数。当应用于指导数学推理时,R-PRM在六个具有挑战性的数据集上实现了超过8.5个点的持续准确性提升。进一步的分析表明,R-PRM表现出更全面的评估和更强的泛化能力,从而突出了其巨大的潜力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在逐步数学推理中容易出错的问题,现有过程奖励模型(PRMs)直接输出评估分数,缺乏对推理过程的深入理解,导致学习效率和评估准确性不高,并且严重依赖大量的标注数据。
核心思路:论文的核心思路是利用更强大的LLMs的推理能力,通过生成种子数据来引导PRM的学习,并结合偏好优化和推理时缩放来提升模型的性能。通过这种方式,R-PRM能够更全面地评估推理过程,并提高泛化能力。
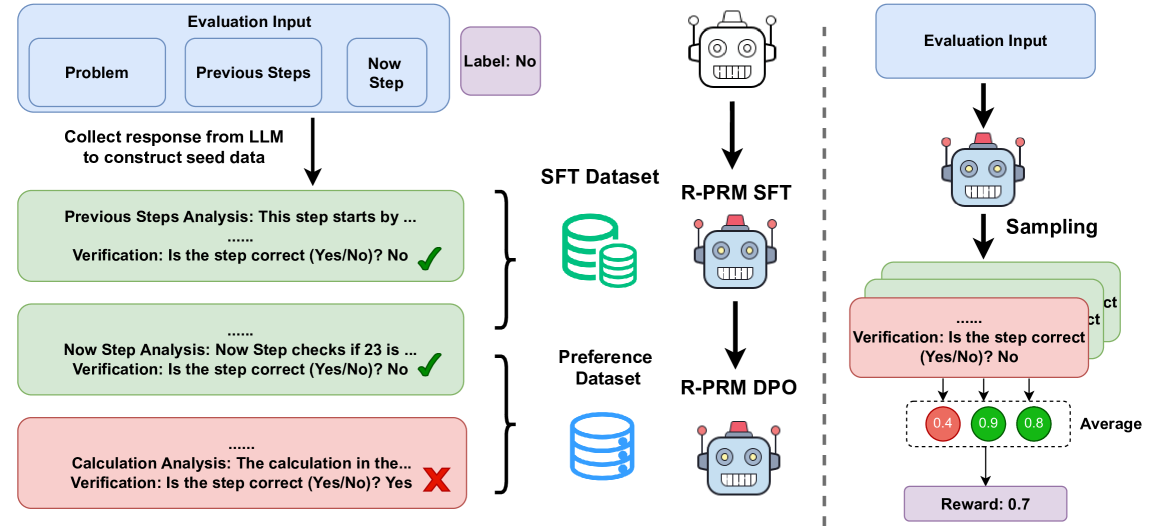
技术框架:R-PRM的整体框架包含以下几个主要阶段:1) 种子数据生成:利用强大的LLMs从有限的标注数据中生成高质量的种子数据,用于初始化PRM的训练。2) 过程奖励建模:训练PRM来评估每个推理步骤的质量。3) 偏好优化:使用偏好优化技术,进一步提升PRM的性能,无需额外的标注数据。4) 推理时缩放:在推理阶段,通过缩放PRM的输出,充分利用模型的推理潜力。
关键创新:R-PRM的关键创新在于:1) 推理驱动的种子数据生成:利用强大的LLMs生成种子数据,有效地引导PRM的学习,克服了标注数据稀缺的问题。2) 偏好优化:通过偏好优化,进一步提升PRM的性能,无需额外的标注数据。3) 推理时缩放:通过缩放PRM的输出,充分利用模型的推理潜力。与现有方法相比,R-PRM能够更全面地评估推理过程,并提高泛化能力。
关键设计:论文中关于关键设计的细节描述较少,但可以推测可能包含以下方面:1) LLM的选择:选择合适的LLM来生成高质量的种子数据至关重要。2) 偏好优化策略:选择合适的偏好优化算法,例如Direct Preference Optimization (DPO) 或 Reinforcement Learning from Human Feedback (RLHF)。3) 推理时缩放系数:需要仔细调整推理时缩放系数,以获得最佳性能。具体的损失函数、网络结构等细节未知。
🖼️ 关键图片


📊 实验亮点
R-PRM在ProcessBench和PRMBench上分别超过了强大的基线11.9和8.5个F1分数。在六个具有挑战性的数学推理数据集上,R-PRM实现了超过8.5个点的持续准确性提升。这些实验结果表明,R-PRM在评估和泛化能力方面都优于现有方法。
🎯 应用场景
R-PRM可应用于各种需要逐步推理的场景,例如数学问题求解、代码生成、逻辑推理等。该研究的实际价值在于提高LLMs在复杂任务中的准确性和可靠性,未来可能促进AI在教育、科研等领域的应用。
📄 摘要(原文)
Large language models (LLMs) inevitably make mistakes when performing step-by-step mathematical reasoning. Process Reward Models (PRMs) have emerged as a promising solution by evaluating each reasoning step. However, existing PRMs typically output evaluation scores directly, limiting both learning efficiency and evaluation accuracy, which is further exacerbated by the scarcity of annotated data. To address these issues, we propose Reasoning-Driven Process Reward Modeling (R-PRM). First, we leverage stronger LLMs to generate seed data from limited annotations, effectively bootstrapping our model's reasoning capabilities and enabling comprehensive step-by-step evaluation. Second, we further enhance performance through preference optimization, without requiring additional annotated data. Third, we introduce inference-time scaling to fully harness the model's reasoning potential. Extensive experiments demonstrate R-PRM's effectiveness: on ProcessBench and PRMBench, it surpasses strong baselines by 11.9 and 8.5 points in F1 scores, respectively. When applied to guide mathematical reasoning, R-PRM achieves consistent accuracy improvements of over 8.5 points across six challenging datasets. Further analysis reveals that R-PRM exhibits more comprehensive evaluation and stronger generalization capabilities, thereby highlighting its significant potential.