ENCORE: Entropy-guided Reward Composition for Multi-head Safety Reward Models
作者: Xiaomin Li, Xupeng Chen, Jingxuan Fan, Eric Hanchen Jiang, Mingye Gao
分类: cs.CL
发布日期: 2025-03-26 (更新: 2025-11-10)
💡 一句话要点
提出ENCORE,通过熵引导的多头奖励组合提升LLM安全对齐效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全对齐 强化学习 人类反馈 多头奖励
📋 核心要点
- 现有RLHF方法在对LLM进行安全对齐时,难以准确评估多维度安全规则的综合质量。
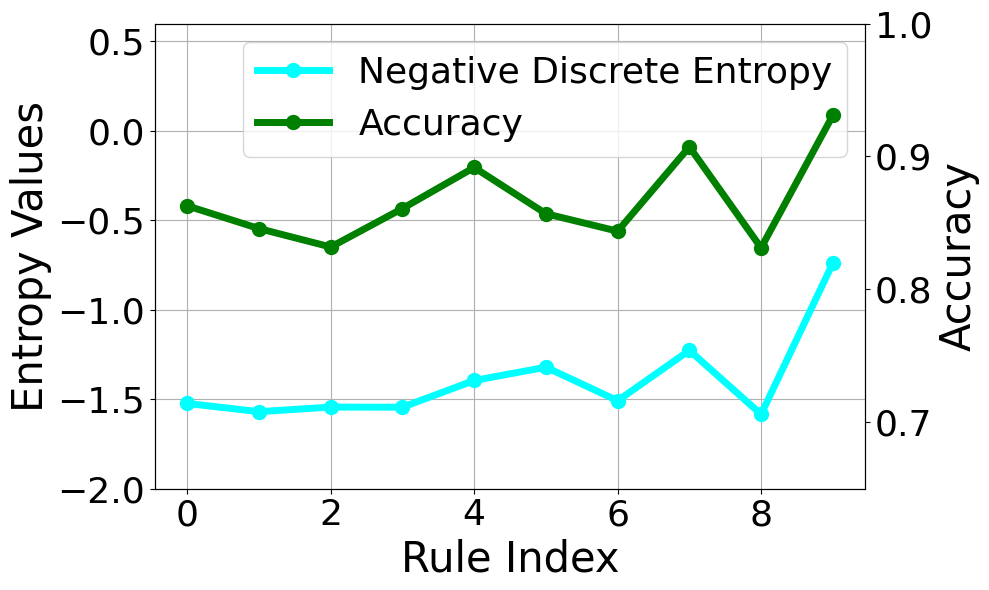
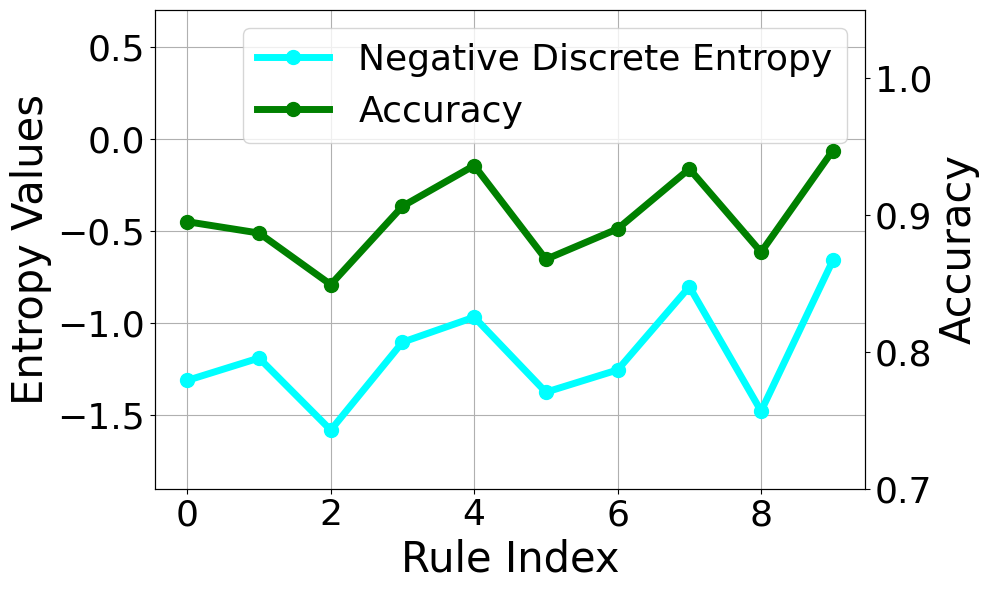
- ENCORE通过熵引导,惩罚评分熵高的规则,从而更准确地组合多头奖励。
- ENCORE在RewardBench上超越多个基线,无需训练,且具有良好的可解释性。
📝 摘要(中文)
大型语言模型(LLM)的安全对齐通常依赖于从人类反馈中进行强化学习(RLHF),这需要人工标注来构建偏好数据集。由于为数据分配整体质量分数存在挑战,最近的工作越来越多地采用基于多个安全规则的细粒度评分。本文发现了一个鲁棒的现象:评分熵较高的规则在区分人类偏好的响应时往往具有较低的准确性。利用这一洞察力,我们提出ENCORE,一种简单的熵引导方法,通过惩罚具有高评分熵的规则来组合多头奖励。从理论上讲,我们证明了这些规则在Bradley-Terry损失下的权重优化过程中会产生可忽略不计的权重,从而自然地证明了对它们的惩罚。在RewardBench安全任务上,ENCORE始终优于强大的基线,包括随机和均匀加权、单头Bradley-Terry和LLM-as-a-judge等。我们的方法是完全免训练的,通常适用于各种数据集,并保留了可解释性,使其成为一种实用且有效的多属性奖励建模方法。
🔬 方法详解
问题定义:现有基于RLHF的安全对齐方法,在构建奖励模型时,通常需要人工对多个安全规则进行评分。然而,如何有效地组合这些多头(multi-head)奖励,以准确反映人类的偏好,是一个挑战。现有的方法,如均匀加权或随机加权,无法充分利用不同规则的区分能力,导致奖励模型不够准确。
核心思路:论文的核心思路是观察到评分熵高的规则,其区分人类偏好响应的准确性较低。因此,通过降低这些高熵规则的权重,可以更有效地组合多头奖励,从而提高奖励模型的准确性。这种方法基于一个假设:人类对某些规则的评分一致性较低,表明这些规则本身可能不够清晰或重要。
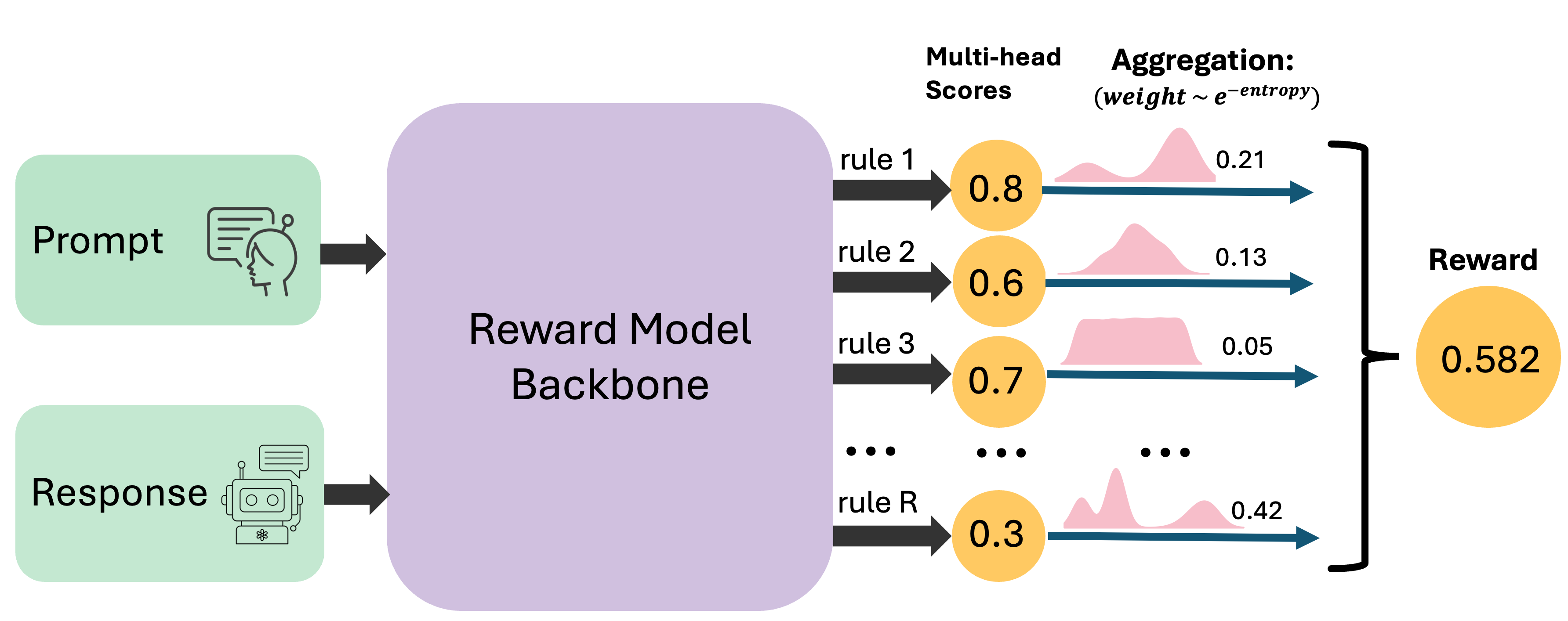
技术框架:ENCORE方法的核心在于对每个规则的评分熵进行计算,并根据熵值对规则的权重进行调整。具体流程如下:1) 收集人类对多个安全规则的评分数据;2) 计算每个规则的评分熵;3) 根据熵值,对每个规则的奖励进行加权,熵越高,权重越低;4) 将加权后的奖励进行组合,得到最终的奖励信号。整个过程无需训练,可以直接应用于现有的RLHF框架。
关键创新:ENCORE的关键创新在于利用评分熵来指导多头奖励的组合。与现有方法相比,ENCORE不需要额外的训练数据或复杂的模型结构,而是通过简单有效的熵引导,实现了更好的奖励建模效果。这种方法的本质区别在于,它能够自适应地调整不同规则的权重,从而更好地反映人类的偏好。
关键设计:ENCORE的关键设计在于如何计算评分熵以及如何根据熵值调整规则的权重。评分熵的计算采用标准的信息熵公式。权重的调整可以采用多种方式,例如,可以将权重设置为与熵值成反比,或者使用一个更复杂的函数来映射熵值到权重。论文中具体使用的权重调整方式未知,但核心思想都是降低高熵规则的权重。
🖼️ 关键图片
📊 实验亮点
ENCORE在RewardBench安全任务上取得了显著的性能提升,超越了包括随机加权、均匀加权、单头Bradley-Terry和LLM-as-a-judge等多个基线方法。具体提升幅度未知,但论文强调ENCORE在多个安全任务上均表现出一致的优越性。ENCORE的免训练特性和可解释性也使其成为一个实用的解决方案。
🎯 应用场景
ENCORE方法可广泛应用于大型语言模型的安全对齐领域,尤其是在需要考虑多个安全规则的场景下。该方法可以帮助构建更准确的奖励模型,从而提高LLM的安全性和可靠性。此外,ENCORE的免训练特性使其易于部署和应用,具有很高的实际价值。未来,该方法可以扩展到其他多属性奖励建模任务中。
📄 摘要(原文)
The safety alignment of large language models (LLMs) often relies on reinforcement learning from human feedback (RLHF), which requires human annotations to construct preference datasets. Given the challenge of assigning overall quality scores to data, recent works increasingly adopt fine-grained ratings based on multiple safety rules. In this paper, we discover a robust phenomenon: Rules with higher rating entropy tend to have lower accuracy in distinguishing human-preferred responses. Exploiting this insight, we propose ENCORE, a simple entropy-guided method to compose multi-head rewards by penalizing rules with high rating entropy. Theoretically, we show that such rules yield negligible weights under the Bradley-Terry loss during weight optimization, naturally justifying their penalization. Empirically, ENCORE consistently outperforms strong baselines, including random and uniform weighting, single-head Bradley-Terry, and LLM-as-a-judge, etc. on RewardBench safety tasks. Our method is completely training-free, generally applicable across datasets, and retains interpretability, making it a practical and effective approach for multi-attribute reward modeling.