From Annotation to Adaptation: Metrics, Synthetic Data, and Aspect Extraction for Aspect-Based Sentiment Analysis with Large Language Models
作者: Nikita Neveditsin, Pawan Lingras, Vijay Mago
分类: cs.CL
发布日期: 2025-03-26
备注: Accepted to NAACL SRW 2025
DOI: 10.18653/v1/2025.naacl-srw.14
💡 一句话要点
针对LLM在ABSA中隐式方面提取的评估,提出新指标并使用合成数据进行适配。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感分析 方面提取 大型语言模型 合成数据 评估指标
📋 核心要点
- 现有ABSA方法在处理隐式方面和新领域数据时存在挑战,缺乏有效的评估指标。
- 论文提出一种基于合成数据的适配方法,并设计了一种新的评估指标来衡量LLM在隐式方面提取中的性能。
- 实验结果展示了LLM在ABSA任务中的能力,同时也揭示了其在特定场景下的局限性,为未来研究提供了方向。
📝 摘要(中文)
本研究考察了大型语言模型(LLMs)在基于方面的情感分析(ABSA)中的性能,重点关注新领域中的隐式方面提取。我们使用合成的体育反馈数据集,评估了开放权重LLMs提取方面-极性对的能力,并提出了一种指标,以促进生成模型方面提取的评估。我们的研究结果突出了LLMs在ABSA任务中的潜力和局限性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在基于方面的情感分析(ABSA)中,尤其是在处理隐式方面和新领域数据时所面临的挑战。现有方法在这些场景下表现不佳,缺乏有效的评估指标来衡量LLM的性能。
核心思路:论文的核心思路是利用合成数据来训练和评估LLMs在ABSA任务中的能力,并提出一种新的评估指标来更准确地衡量LLMs在隐式方面提取方面的性能。通过合成数据,可以控制数据的分布和特征,从而更好地了解LLMs的优势和局限性。
技术框架:整体框架包括以下几个主要阶段:1) 构建合成的体育反馈数据集;2) 使用开放权重的LLMs进行方面-极性对的提取;3) 使用提出的新指标评估LLMs的性能。该框架旨在提供一个可重复和可控的实验环境,以便更深入地研究LLMs在ABSA任务中的行为。
关键创新:论文的关键创新点在于提出了一个用于评估生成模型在方面提取任务中性能的新指标。该指标旨在克服现有评估方法的局限性,更准确地衡量LLMs在隐式方面提取方面的能力。此外,使用合成数据进行训练和评估也是一个重要的创新点,可以更好地控制实验条件并深入了解LLMs的行为。
关键设计:关于合成数据的生成,论文可能采用了某种规则或模板来生成体育反馈数据,并控制了方面和极性的分布。关于新指标的设计,具体的技术细节未知,但可以推测其可能考虑了提取方面与真实方面之间的相似度、极性的准确性以及提取方面的完整性等因素。具体的参数设置、损失函数和网络结构等技术细节在摘要中没有提及,属于未知信息。
🖼️ 关键图片
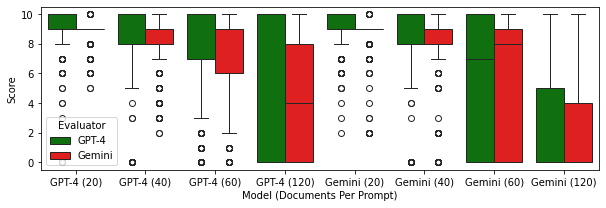
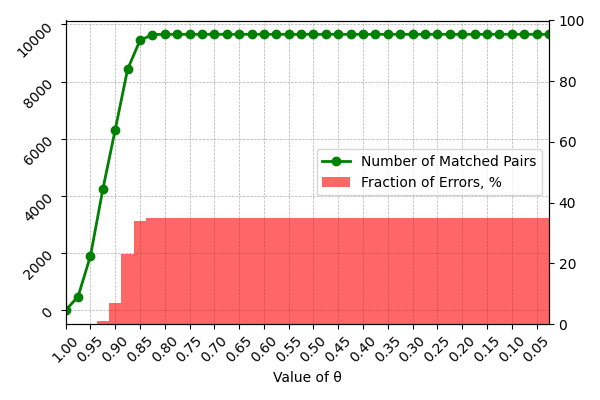
📊 实验亮点
论文的主要实验亮点在于使用合成的体育反馈数据集评估了开放权重LLMs在ABSA任务中的性能。虽然摘要中没有提供具体的性能数据和对比基线,但研究结果强调了LLMs在ABSA任务中的潜力和局限性,为未来的研究提供了有价值的参考。
🎯 应用场景
该研究成果可应用于各种需要情感分析的领域,例如在线评论分析、社交媒体监控、客户反馈分析等。通过利用LLMs和合成数据,可以更有效地提取和分析用户的情感,从而为企业决策提供支持。未来的研究可以进一步探索如何利用LLMs来处理更复杂的ABSA任务,例如多语言情感分析和细粒度情感分析。
📄 摘要(原文)
This study examines the performance of Large Language Models (LLMs) in Aspect-Based Sentiment Analysis (ABSA), with a focus on implicit aspect extraction in a novel domain. Using a synthetic sports feedback dataset, we evaluate open-weight LLMs' ability to extract aspect-polarity pairs and propose a metric to facilitate the evaluation of aspect extraction with generative models. Our findings highlight both the potential and limitations of LLMs in the ABSA task.