Advancements in Natural Language Processing: Exploring Transformer-Based Architectures for Text Understanding
作者: Tianhao Wu, Yu Wang, Ngoc Quach
分类: cs.CL, cs.AI
发布日期: 2025-03-26
备注: This paper has been accepted by the 5th International Conference on Artificial Intelligence and Industrial Technology Applications (AIITA 2025)
💡 一句话要点
探索Transformer架构在文本理解中的应用,提升NLP性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言处理 Transformer模型 文本理解 自注意力机制 BERT GPT 长距离依赖 深度学习
📋 核心要点
- 传统RNN在处理长文本时存在梯度消失问题,难以捕捉长距离依赖关系,限制了文本理解能力。
- 论文探索Transformer架构,利用自注意力机制有效捕捉长距离依赖,提升模型对上下文的理解和适应能力。
- 实验结果表明,Transformer模型在GLUE和SQuAD等基准测试中取得了优异的性能,F1分数超过90%。
📝 摘要(中文)
自然语言处理(NLP)领域因Transformer架构的出现而发生了变革,显著提升了机器理解和生成类人文本的能力。本文探讨了Transformer模型(如BERT和GPT)的进展,重点关注它们在文本理解任务中相对于循环神经网络(RNN)等传统方法的卓越性能。通过可视化表示分析统计特性,包括文本长度分布的概率密度函数和特征空间分类,研究强调了模型在处理长距离依赖、适应条件转移以及提取分类特征方面的能力,即使在类别重叠的情况下也是如此。借鉴2024年的最新研究,包括多跳知识图推理和上下文感知聊天交互的增强,本文概述了一种包括数据准备、模型选择、预训练、微调和评估的方法。结果表明,在GLUE和SQuAD等基准测试中达到了最先进的性能,F1分数超过90%,但高计算成本等挑战依然存在。这项工作强调了Transformer在现代NLP中的关键作用,并提出了未来的方向,包括效率优化和多模态集成,以进一步推进基于语言的AI系统。
🔬 方法详解
问题定义:论文旨在解决自然语言处理中机器对文本理解能力不足的问题。现有方法,如循环神经网络(RNN),在处理长文本时存在梯度消失或梯度爆炸的问题,难以捕捉长距离依赖关系,并且并行化能力较弱,导致训练效率低下。
核心思路:论文的核心思路是利用Transformer架构的自注意力机制来克服RNN的局限性。自注意力机制允许模型在处理每个词时,同时关注文本中的所有其他词,从而有效地捕捉长距离依赖关系,并且可以并行计算,提高训练效率。
技术框架:论文采用了一种标准的Transformer模型训练流程,包括以下几个主要阶段:1) 数据准备:收集和清洗用于训练和评估的文本数据。2) 模型选择:选择合适的Transformer模型,如BERT或GPT。3) 预训练:在大规模无标签文本数据上预训练模型,使其学习通用的语言表示。4) 微调:在特定任务的有标签数据上微调模型,使其适应特定任务的需求。5) 评估:使用基准测试数据集评估模型的性能。
关键创新:论文的关键创新在于应用Transformer架构来解决文本理解问题,并展示了其相对于传统RNN的优越性。自注意力机制是Transformer的核心,它允许模型动态地学习文本中不同词之间的关系,从而更好地理解文本的含义。
关键设计:论文的关键设计包括:1) 使用多层Transformer编码器和解码器来构建模型。2) 采用自注意力机制来计算词之间的关系。3) 使用位置编码来表示词在文本中的位置信息。4) 使用残差连接和层归一化来提高模型的训练稳定性和泛化能力。5) 针对不同的任务,选择合适的损失函数和优化器进行微调。
🖼️ 关键图片
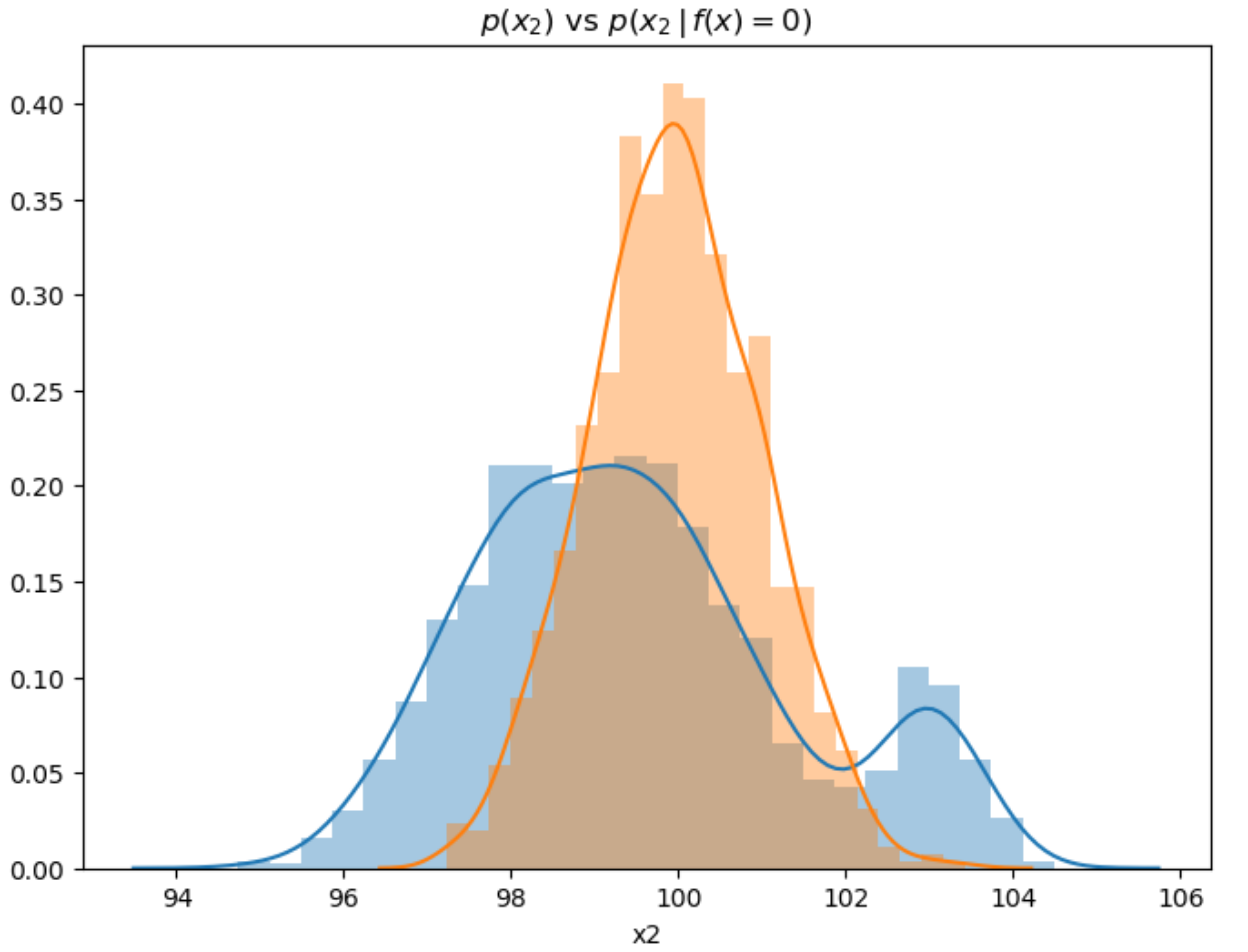
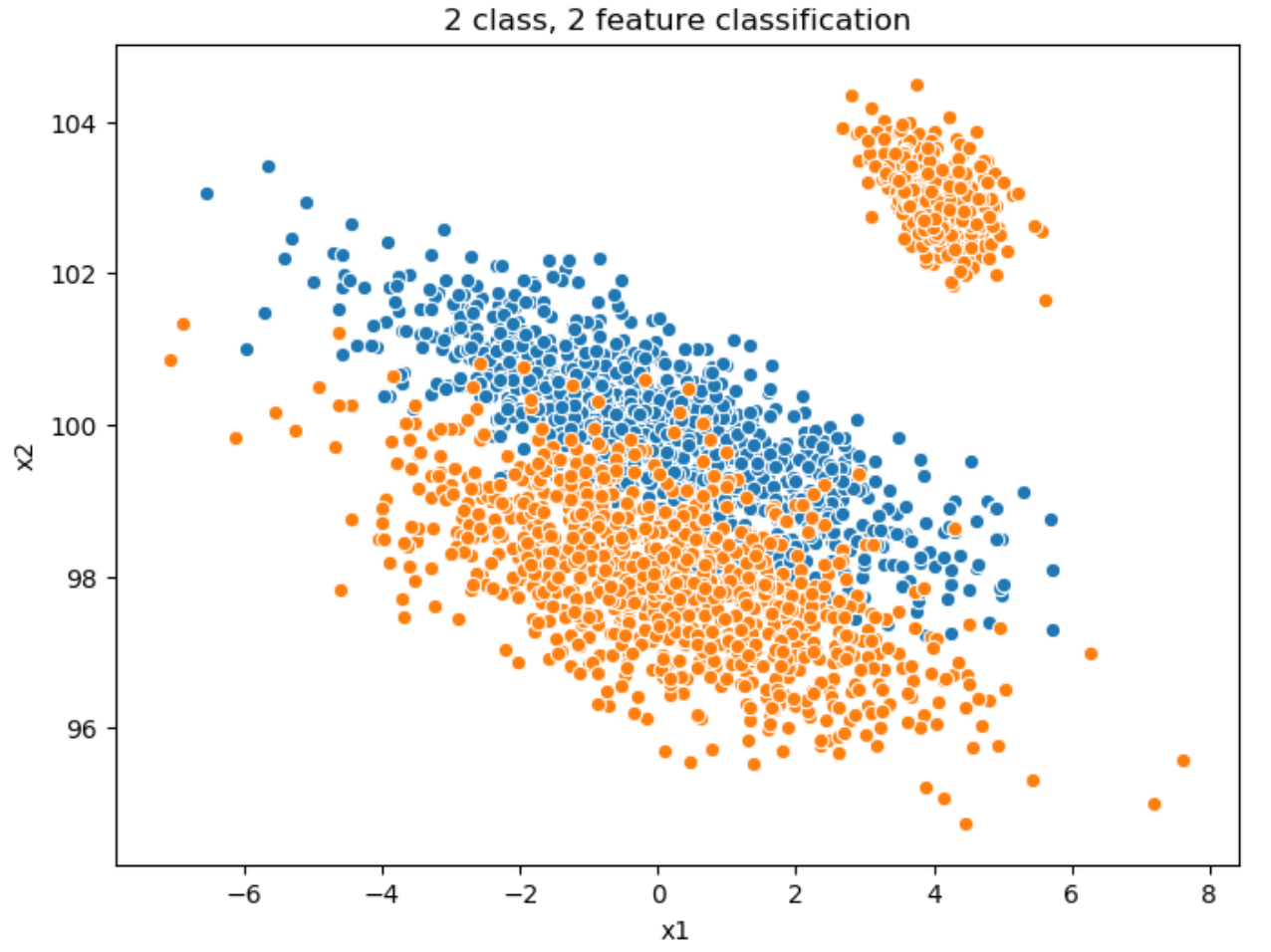
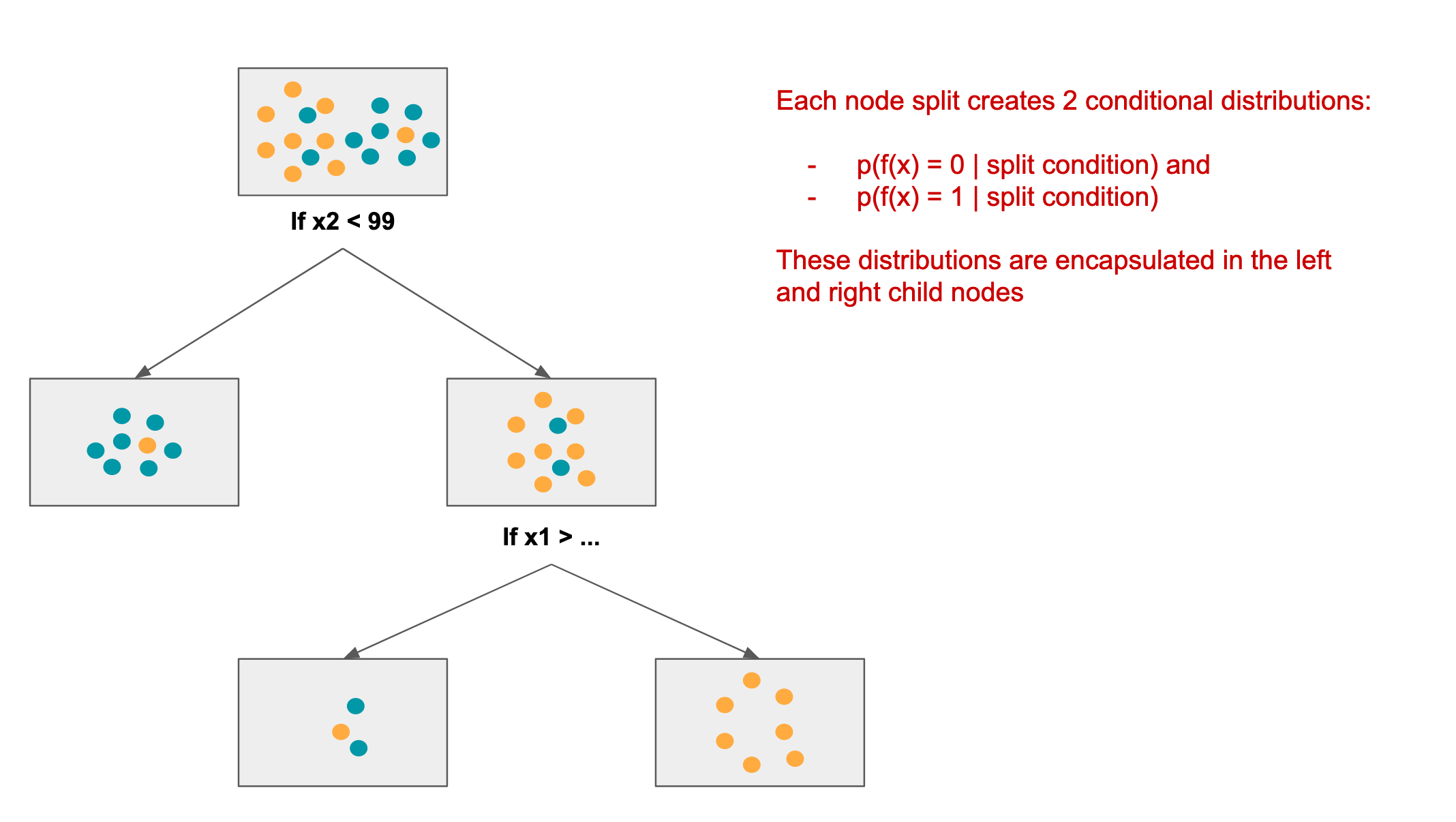
📊 实验亮点
实验结果表明,基于Transformer的模型在GLUE和SQuAD等基准测试中取得了显著的性能提升,F1分数超过90%。与传统的RNN模型相比,Transformer模型能够更好地捕捉长距离依赖关系,从而更准确地理解文本的含义。这些结果证明了Transformer架构在文本理解任务中的有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于机器翻译、文本摘要、问答系统、情感分析、对话系统等自然语言处理任务中。通过提升机器对文本的理解能力,可以改善人机交互体验,提高信息检索效率,并为各种智能应用提供更强大的支持。未来,该技术有望在智能客服、智能写作、舆情监控等领域发挥重要作用。
📄 摘要(原文)
Natural Language Processing (NLP) has witnessed a transformative leap with the advent of transformer-based architectures, which have significantly enhanced the ability of machines to understand and generate human-like text. This paper explores the advancements in transformer models, such as BERT and GPT, focusing on their superior performance in text understanding tasks compared to traditional methods like recurrent neural networks (RNNs). By analyzing statistical properties through visual representations-including probability density functions of text length distributions and feature space classifications-the study highlights the models' proficiency in handling long-range dependencies, adapting to conditional shifts, and extracting features for classification, even with overlapping classes. Drawing on recent 2024 research, including enhancements in multi-hop knowledge graph reasoning and context-aware chat interactions, the paper outlines a methodology involving data preparation, model selection, pretraining, fine-tuning, and evaluation. The results demonstrate state-of-the-art performance on benchmarks like GLUE and SQuAD, with F1 scores exceeding 90%, though challenges such as high computational costs persist. This work underscores the pivotal role of transformers in modern NLP and suggests future directions, including efficiency optimization and multimodal integration, to further advance language-based AI systems.