Universal Cross-Tokenizer Distillation via Approximate Likelihood Matching
作者: Benjamin Minixhofer, Ivan Vulić, Edoardo Maria Ponti
分类: cs.CL
发布日期: 2025-03-25 (更新: 2025-10-24)
备注: NeurIPS 2025
💡 一句话要点
提出一种基于近似似然匹配的通用跨分词器蒸馏方法,扩展LLM蒸馏的应用范围。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨分词器蒸馏 知识蒸馏 大型语言模型 近似似然匹配 分词器迁移
📋 核心要点
- 现有蒸馏方法依赖相似的分词器,限制了教师-学生模型的选择范围,阻碍了知识迁移的灵活性。
- 提出基于近似似然匹配的跨分词器蒸馏方法,允许在具有根本不同分词器的模型间进行知识迁移。
- 实验表明,该方法在分词器迁移、模型蒸馏和嵌入预测等方面均优于现有方法,扩展了蒸馏的应用。
📝 摘要(中文)
蒸馏在将知识从大型语言模型(LLM)教师模型迁移到学生LLM模型方面表现出显著的成功。然而,当前的蒸馏方法要求教师和学生模型之间使用相似的分词器,这限制了它们的应用范围,仅适用于一小部分教师-学生对。在这项工作中,我们开发了一种基于原则的跨分词器蒸馏方法,以解决这一关键缺陷。我们的方法是第一个能够实现跨根本不同的分词器的有效蒸馏的方法,同时在所有其他情况下也大大优于先前的方法。我们在三个不同的用例中验证了我们方法的有效性。首先,我们表明,将分词器迁移视为自蒸馏,可以实现前所未有的有效跨分词器迁移,包括将子词模型快速迁移到字节级别。将不同的模型迁移到同一个分词器也能够通过集成来提高性能。其次,我们将一个大型的数学专业LLM蒸馏成一个具有不同分词器的小型通用模型,实现了具有竞争力的数学问题解决性能。第三,我们使用我们的方法来训练最先进的嵌入预测超网络,用于免训练的分词器迁移。我们的结果为蒸馏解锁了更广泛的教师-学生对,从而能够以新的方式适应和增强LLM之间的交互。
🔬 方法详解
问题定义:现有的大语言模型蒸馏方法通常要求教师模型和学生模型使用相似的分词器。这意味着如果两个模型使用不同的分词策略(例如,一个使用WordPiece,另一个使用Byte-Pair Encoding),则很难有效地将知识从教师模型迁移到学生模型。这极大地限制了蒸馏的应用范围,因为无法充分利用各种预训练模型和分词器的优势。
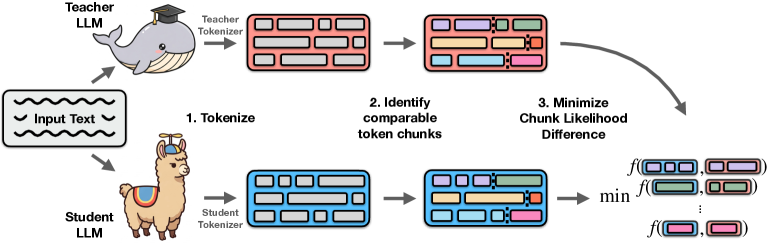
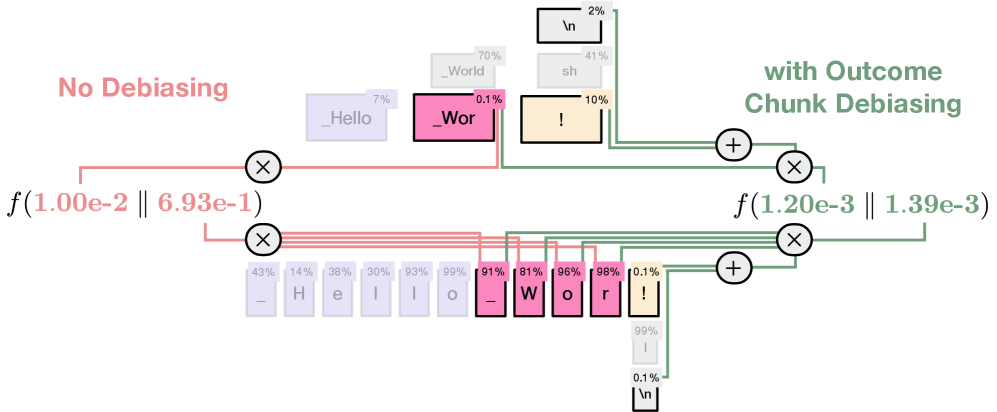
核心思路:论文的核心思路是通过近似似然匹配来实现跨分词器的蒸馏。具体来说,即使教师模型和学生模型使用不同的分词器,它们仍然可以对相同的文本序列生成概率分布。论文的目标是让学生模型的概率分布尽可能地接近教师模型的概率分布,从而实现知识的迁移。为了解决分词器差异带来的问题,论文提出了一种基于近似的似然匹配方法,避免了直接比较不同分词器下的token概率。
技术框架:该方法主要包含以下几个阶段:1)选择一个文本数据集;2)使用教师模型和学生模型分别对文本进行编码,得到各自的概率分布;3)使用近似似然匹配损失函数来训练学生模型,使其概率分布接近教师模型的概率分布。该框架的关键在于近似似然匹配损失函数的设计,它需要能够有效地处理不同分词器带来的差异。
关键创新:该方法最重要的创新点在于提出了近似似然匹配损失函数,该函数能够有效地处理不同分词器带来的差异。与现有方法相比,该方法不需要教师模型和学生模型使用相似的分词器,从而大大扩展了蒸馏的应用范围。此外,该方法还提出了一种将分词器迁移视为自蒸馏的策略,进一步提高了分词器迁移的效率。
关键设计:近似似然匹配损失函数的具体形式未知,但可以推测其设计需要考虑以下几个关键因素:1)如何衡量两个不同分词器下的概率分布的相似度;2)如何避免直接比较不同分词器下的token概率;3)如何保证学生模型能够学习到教师模型的知识,而不是简单地复制教师模型的输出。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在分词器迁移、模型蒸馏和嵌入预测等多个任务上均取得了显著的性能提升。例如,在数学问题解决任务中,将一个大型的数学专业LLM蒸馏成一个具有不同分词器的小型通用模型,实现了具有竞争力的性能。此外,该方法还能够训练出最先进的嵌入预测超网络,用于免训练的分词器迁移。
🎯 应用场景
该研究成果可广泛应用于模型压缩、知识迁移和分词器优化等领域。例如,可以将大型的专业领域模型蒸馏成小型的通用模型,以便在资源受限的设备上部署。此外,该方法还可以用于快速迁移分词器,从而提高模型的训练效率。该研究为不同架构和分词策略的大语言模型之间的协同工作奠定了基础。
📄 摘要(原文)
Distillation has shown remarkable success in transferring knowledge from a Large Language Model (LLM) teacher to a student LLM. However, current distillation methods require similar tokenizers between the teacher and the student, restricting their applicability to only a small subset of teacher-student pairs. In this work, we develop a principled cross-tokenizer distillation method to solve this crucial deficiency. Our method is the first to enable effective distillation across fundamentally different tokenizers, while also substantially outperforming prior methods in all other cases. We verify the efficacy of our method on three distinct use cases. First, we show that viewing tokenizer transfer as self-distillation enables unprecedentedly effective transfer across tokenizers, including rapid transfer of subword models to the byte-level. Transferring different models to the same tokenizer also enables ensembling to boost performance. Secondly, we distil a large maths-specialised LLM into a small general-purpose model with a different tokenizer, achieving competitive maths problem-solving performance. Thirdly, we use our method to train state-of-the-art embedding prediction hypernetworks for training-free tokenizer transfer. Our results unlock an expanded range of teacher-student pairs for distillation, enabling new ways to adapt and enhance interaction between LLMs.