1.4 Million Open-Source Distilled Reasoning Dataset to Empower Large Language Model Training
作者: Han Zhao, Haotian Wang, Yiping Peng, Sitong Zhao, Xiaoyu Tian, Shuaiting Chen, Yunjie Ji, Xiangang Li
分类: cs.CL
发布日期: 2025-03-25
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
提出1.4百万开源蒸馏推理数据集以增强大型语言模型训练
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推理数据集 大型语言模型 模型训练 监督微调 验证机制 开源数据
📋 核心要点
- 现有推理模型在处理复杂推理任务时存在准确性不足和泛化能力差的问题。
- 论文提出了AM-DeepSeek-R1-Distilled数据集,包含经过验证的高质量推理问题,旨在提升模型的推理能力。
- 实验结果显示,使用该数据集训练的模型在多个基准测试中显著超越了现有模型,验证了数据集的有效性。
📝 摘要(中文)
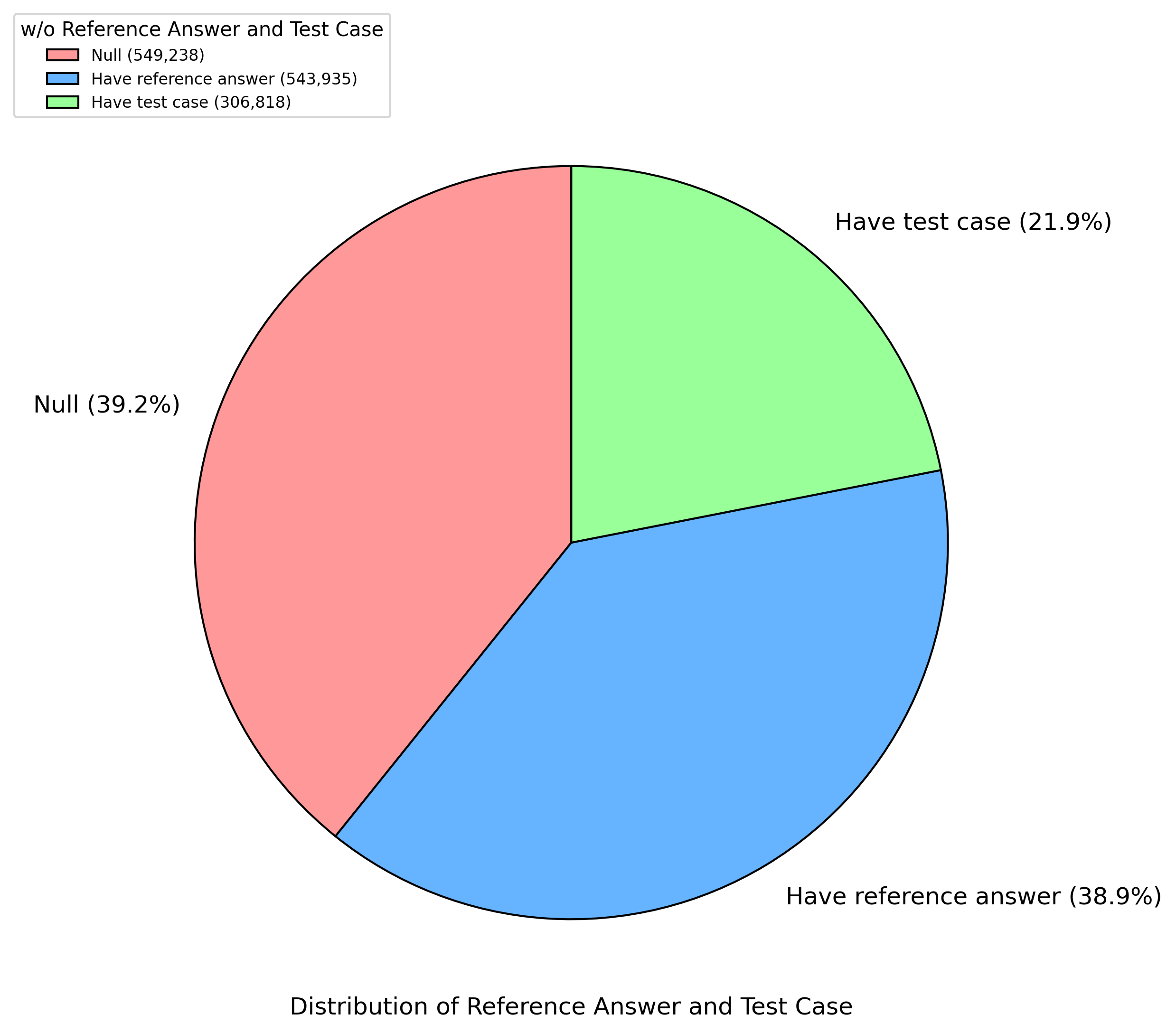
AM-DeepSeek-R1-Distilled是一个大规模的数据集,包含高质量且具有挑战性的推理问题,旨在支持一般推理任务。这些问题来自多个开源数据集,经过语义去重和仔细清理,以消除测试集污染。数据集中的所有响应均源自推理模型(主要是DeepSeek-R1),并经过严格验证。数学问题通过参考答案验证,代码问题通过测试用例验证,其他任务则借助奖励模型进行评估。使用该数据集进行简单的监督微调训练的AM-Distill-Qwen-32B模型在四个基准测试上超越了DeepSeek-R1-Distill-Qwen-32B模型,AM-Distill-Qwen-72B模型在所有基准测试上也超越了DeepSeek-R1-Distill-Llama-70B模型。我们将发布这140万道问题及其对应的响应,以促进强大的推理导向大型语言模型的发展。
🔬 方法详解
问题定义:本论文旨在解决现有推理模型在处理复杂推理任务时的准确性不足和泛化能力差的问题。现有方法往往无法有效应对多样化的推理挑战,导致模型性能不佳。
核心思路:论文提出的核心思路是构建一个大规模的推理数据集AM-DeepSeek-R1-Distilled,该数据集包含经过严格验证的推理问题,旨在为大型语言模型提供高质量的训练数据,从而提升其推理能力。
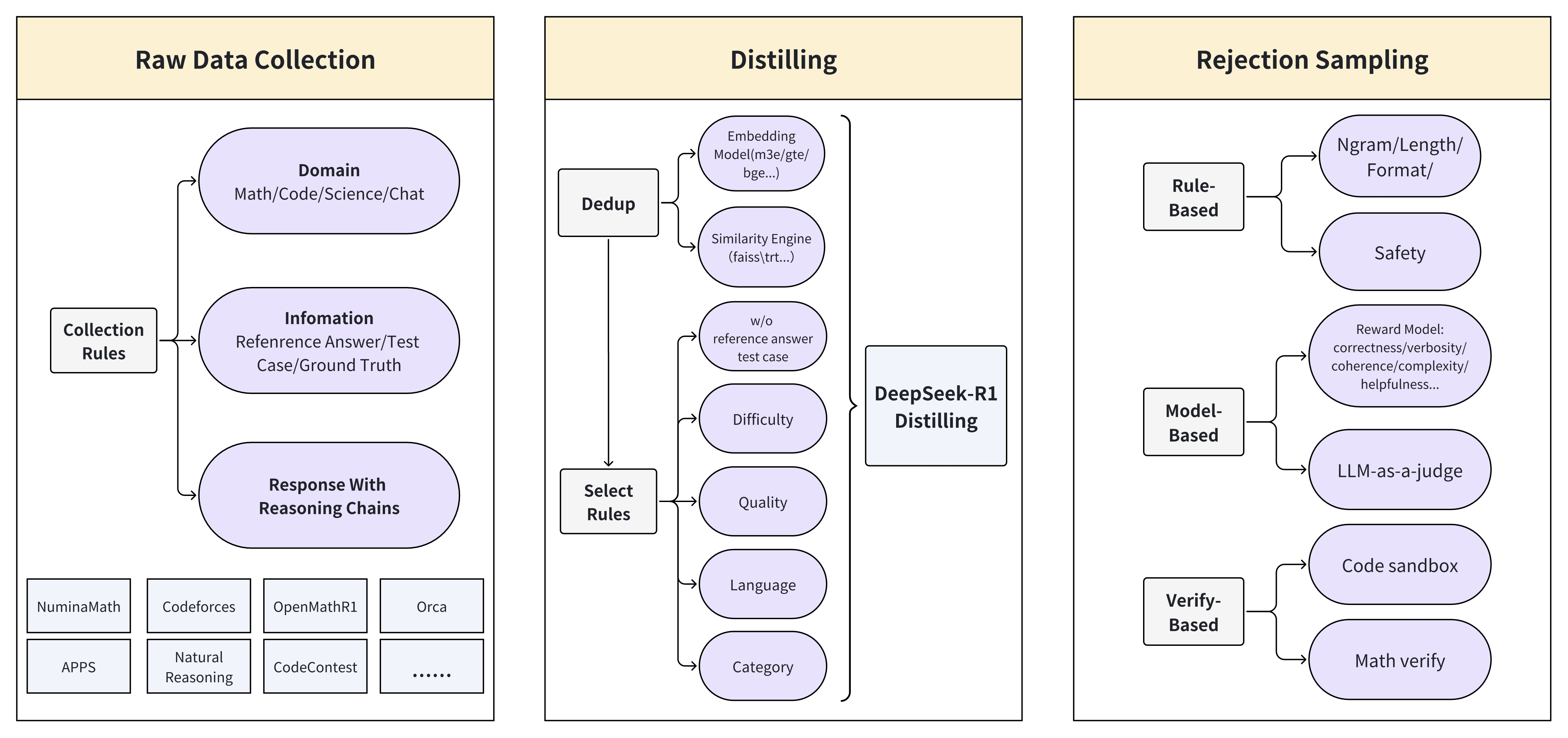
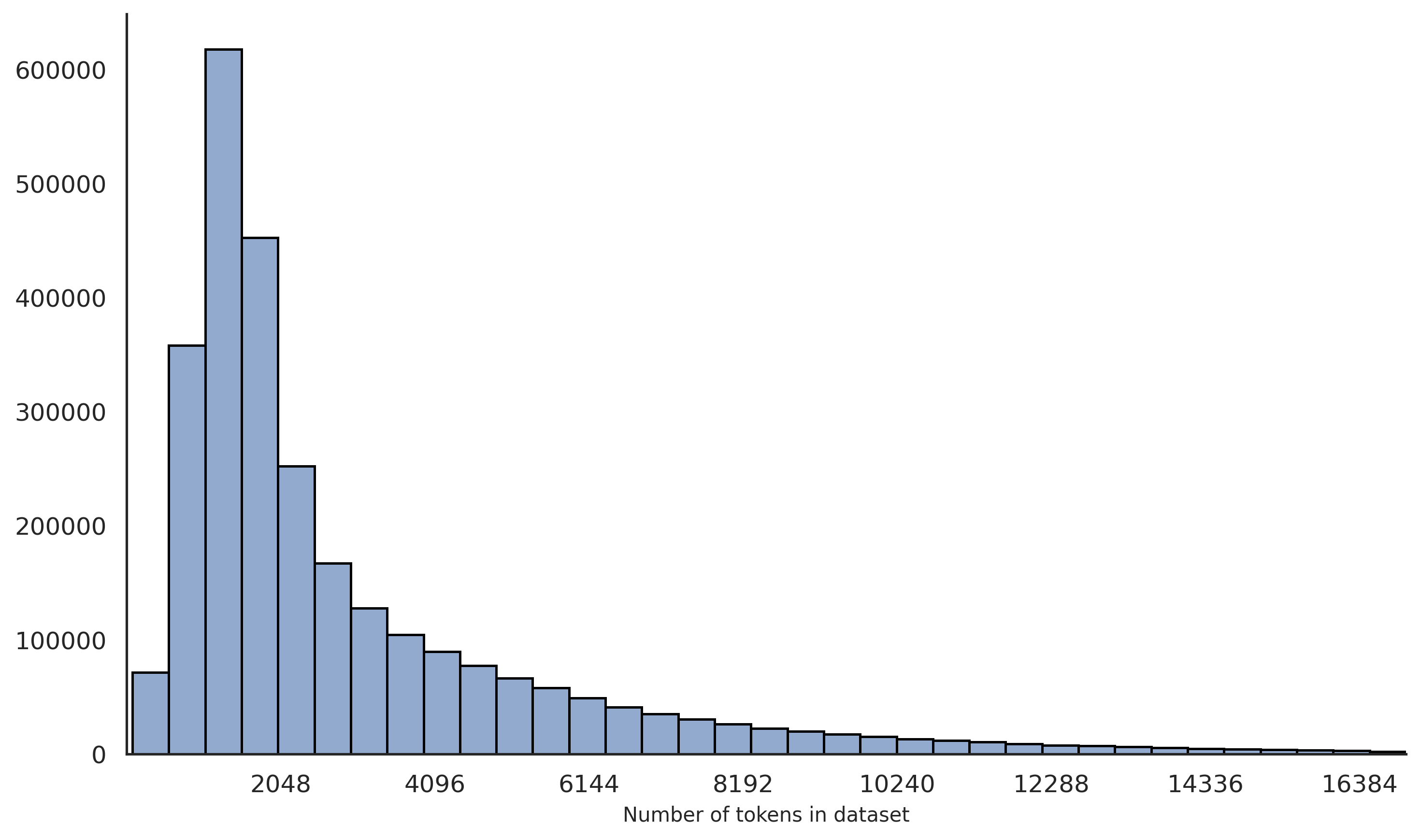
技术框架:整体架构包括数据收集、语义去重、清理、验证和模型训练几个主要阶段。数据集中的问题来自多个开源数据集,经过清理和验证后形成最终的数据集。
关键创新:最重要的技术创新点在于数据集的构建过程,采用了严格的验证机制,包括数学问题的参考答案验证、代码问题的测试用例验证以及其他任务的奖励模型评估。这种方法确保了数据集的高质量和可靠性。
关键设计:在数据集构建中,采用了多种验证手段,确保每个问题的答案都经过严格的验证。此外,模型训练过程中使用了简单的监督微调(SFT)方法,以最大化数据集的利用效率。具体的参数设置和损失函数设计未在摘要中详细说明,需参考原文获取更多技术细节。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用AM-DeepSeek-R1-Distilled数据集训练的AM-Distill-Qwen-32B模型在AIME2024、MATH-500、GPQA-Diamond和LiveCodeBench四个基准测试上均超越了DeepSeek-R1-Distill-Qwen-32B模型。此外,AM-Distill-Qwen-72B模型在所有基准测试上也超越了DeepSeek-R1-Distill-Llama-70B模型,显示出显著的性能提升。
🎯 应用场景
该研究的潜在应用领域包括教育、自动化推理系统和智能助手等。通过提供高质量的推理数据集,研究者和开发者可以训练出更强大的推理导向大型语言模型,从而推动自然语言处理和人工智能的进一步发展。
📄 摘要(原文)
The AM-DeepSeek-R1-Distilled is a large-scale dataset with thinking traces for general reasoning tasks, composed of high-quality and challenging reasoning problems. These problems are collected from a multitude of open-source datasets, subjected to semantic deduplication and meticulous cleaning to eliminate test set contamination. All responses within the dataset are distilled from reasoning models (predominantly DeepSeek-R1) and have undergone rigorous verification procedures. Mathematical problems are validated by checking against reference answers, code problems are verified using test cases, and other tasks are evaluated with the aid of a reward model. The AM-Distill-Qwen-32B model, which was trained through only simple Supervised Fine-Tuning (SFT) using this batch of data, outperformed the DeepSeek-R1-Distill-Qwen-32B model on four benchmarks: AIME2024, MATH-500, GPQA-Diamond, and LiveCodeBench. Additionally, the AM-Distill-Qwen-72B model surpassed the DeepSeek-R1-Distill-Llama-70B model on all benchmarks as well. We are releasing these 1.4 million problems and their corresponding responses to the research community with the objective of fostering the development of powerful reasoning-oriented Large Language Models (LLMs). The dataset was published in \href{https://huggingface.co/datasets/a-m-team/AM-DeepSeek-R1-Distilled-1.4M}{https://huggingface.co/datasets/a-m-team/AM-DeepSeek-R1-Distilled-1.4M}.