Understanding and Improving Information Preservation in Prompt Compression for LLMs
作者: Weronika Łajewska, Momchil Hardalov, Laura Aina, Neha Anna John, Hang Su, Lluís Màrquez
分类: cs.CL, cs.IR, cs.LG
发布日期: 2025-03-24 (更新: 2025-10-10)
备注: Accepted to EMNLP 2025 (Findings), 22 pages, 6 figures, 24 tables
🔗 代码/项目: GITHUB
💡 一句话要点
提出Prompt压缩评估框架并改进软提示方法,提升LLM信息保持能力与下游任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Prompt压缩 大型语言模型 信息保持 软提示 评估框架
📋 核心要点
- 现有Prompt压缩方法在降低输入长度的同时,可能丢失关键信息,导致LLM在复杂任务中性能下降。
- 论文提出一个全面的评估框架,从下游任务性能、上下文依据和信息保持三个方面分析Prompt压缩方法。
- 通过该框架,论文改进了一种软提示方法,控制压缩粒度,显著提升了下游性能、grounding效果和信息保留能力。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务中取得了成功。然而,在信息密集型任务中,prompt长度迅速增长,导致计算需求增加、性能下降,并可能引入来自无关或冗余信息的偏差。为了优化输入长度和性能之间的平衡,研究者们提出了多种prompt压缩技术。本文提出了一个全面的评估框架,用于深入分析prompt压缩方法。除了压缩率之外,我们重点关注三个关键方面:(i)下游任务性能,(ii)输入上下文的依据,以及(iii)信息保持。利用该框架,我们分析了最先进的软压缩和硬压缩方法,发现一些方法未能保留原始prompt中的关键细节,从而限制了复杂任务的性能。通过识别这些局限性,我们通过控制压缩粒度改进了一种软提示方法,在下游性能上实现了高达+23%的提升,在grounding方面实现了+8 BERTScore的提升,并在压缩中保留了2.7倍的实体。最终,我们发现软提示与序列级训练相结合实现了最佳的有效性/压缩率权衡。代码已在https://github.com/amazon-science/information-preservation-in-prompt-compression上发布。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中prompt过长导致计算成本高、性能下降以及信息冗余的问题。现有的prompt压缩方法,包括硬压缩(如删除不重要的token)和软压缩(如学习连续的prompt embedding),在压缩prompt的同时,往往会丢失关键信息,从而影响LLM在下游任务中的表现。尤其是在需要精确信息的任务中,信息损失会更加明显。
核心思路:论文的核心思路是构建一个全面的评估框架,用于分析prompt压缩方法在信息保持方面的能力。通过该框架,可以识别现有方法的不足,并针对性地改进prompt压缩策略。具体而言,论文通过控制软提示方法的压缩粒度,使其能够更好地保留原始prompt中的关键信息。
技术框架:论文的技术框架主要包含三个部分:首先,构建一个评估框架,该框架从三个维度评估prompt压缩方法:下游任务性能、grounding(即模型输出与输入上下文的相关性)和信息保持(即压缩后的prompt是否保留了原始prompt中的关键信息)。其次,使用该框架分析现有的硬压缩和软压缩方法。最后,基于分析结果,改进一种软提示方法,通过控制压缩粒度来提升信息保持能力。
关键创新:论文的关键创新在于提出了一个全面的prompt压缩评估框架,并利用该框架发现现有方法在信息保持方面的不足。此外,通过控制软提示方法的压缩粒度,论文成功地提升了LLM在下游任务中的性能和信息保持能力。与现有方法相比,该方法能够在压缩prompt的同时,更好地保留原始prompt中的关键信息。
关键设计:论文的关键设计包括:1) 评估框架中的三个指标:下游任务性能使用标准的任务评估指标;grounding使用BERTScore来衡量模型输出与输入上下文的相关性;信息保持使用实体识别来衡量压缩后的prompt是否保留了原始prompt中的关键实体。2) 改进的软提示方法通过调整压缩粒度,允许模型更灵活地选择需要保留的信息。3) 论文使用了序列级训练,以进一步优化软提示方法的性能。
🖼️ 关键图片
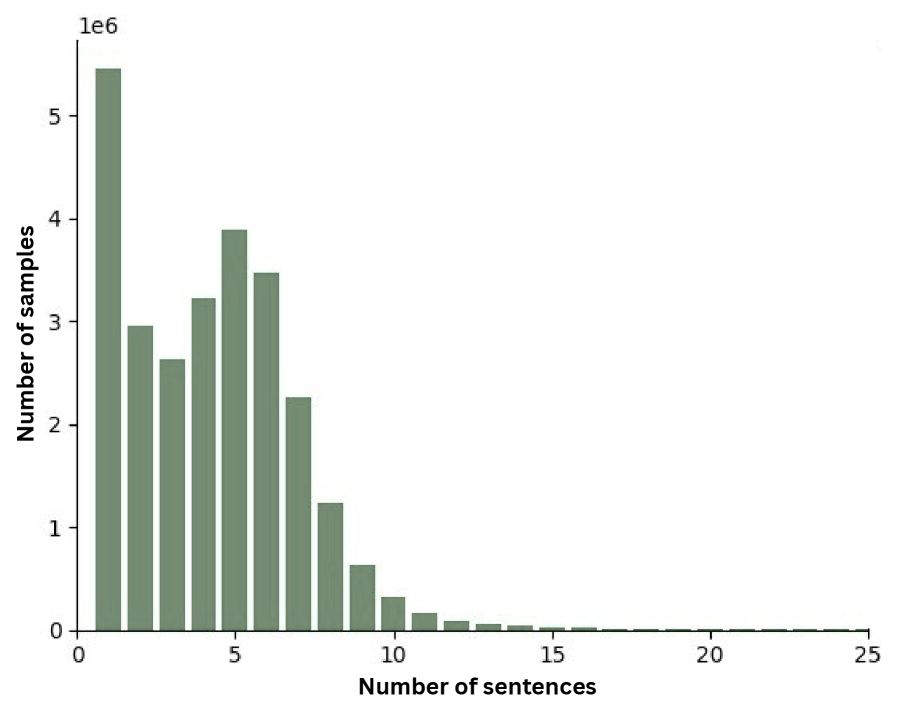
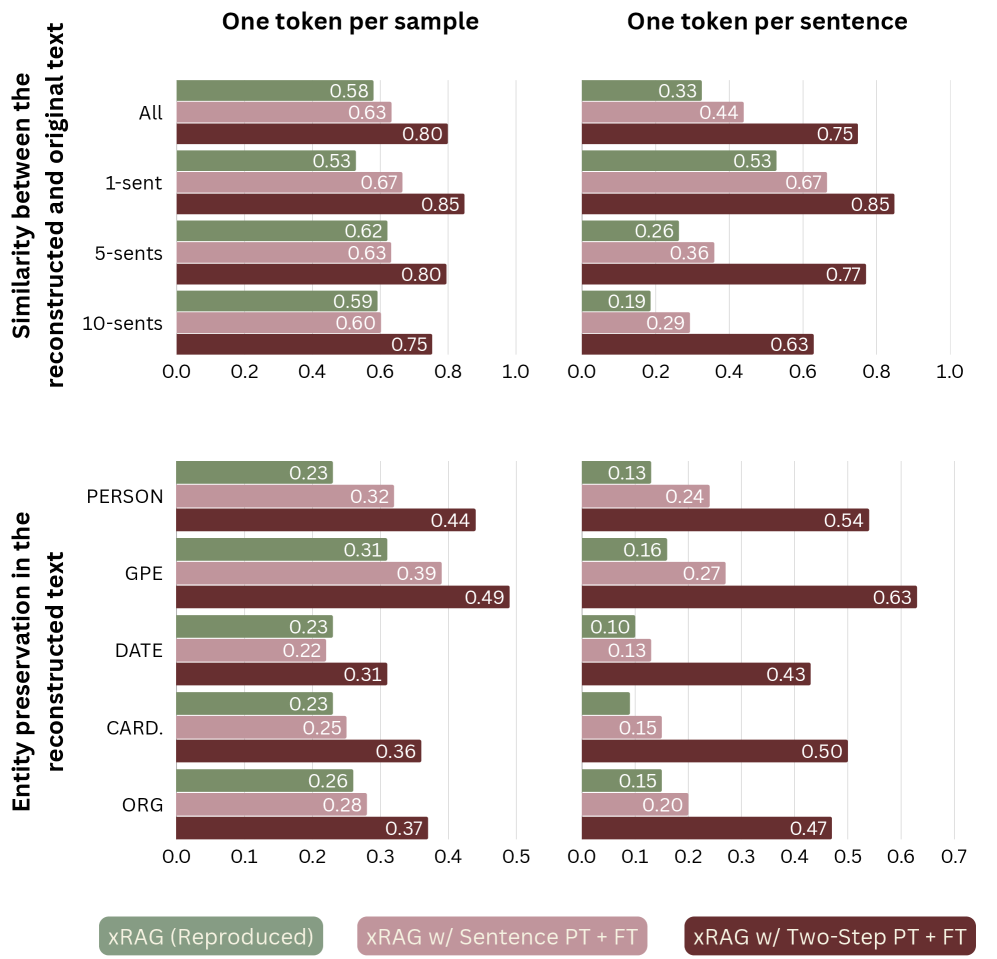
📊 实验亮点
实验结果表明,通过控制压缩粒度改进的软提示方法,在下游任务性能上实现了高达+23%的提升,在grounding方面实现了+8 BERTScore的提升,并在压缩中保留了2.7倍的实体。此外,论文还发现软提示与序列级训练相结合实现了最佳的有效性/压缩率权衡,优于其他基线方法。
🎯 应用场景
该研究成果可应用于各种需要处理长文本prompt的LLM应用场景,例如问答系统、文本摘要、信息检索等。通过提升prompt压缩的信息保持能力,可以降低计算成本,提高模型性能,并减少因信息丢失而产生的偏差。未来,该方法可以推广到其他类型的prompt压缩技术,并应用于更广泛的自然语言处理任务。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have enabled their successful application to a broad range of tasks. However, in information-intensive tasks, the prompt length can grow fast, leading to increased computational requirements, performance degradation, and induced biases from irrelevant or redundant information. Recently, various prompt compression techniques have been introduced to optimize the trade-off between reducing input length and retaining performance. We propose a holistic evaluation framework that allows for in-depth analysis of prompt compression methods. We focus on three key aspects, besides compression ratio: (i) downstream task performance, (ii) grounding in the input context, and (iii) information preservation. Using our framework, we analyze state-of-the-art soft and hard compression methods and show that some fail to preserve key details from the original prompt, limiting performance on complex tasks. By identifying these limitations, we are able to improve one soft prompting method by controlling compression granularity, achieving up to +23% in downstream performance, +8 BERTScore points in grounding, and 2.7x more entities preserved in compression. Ultimately, we find that the best effectiveness/compression rate trade-off is achieved with soft prompting combined with sequence-level training.The code is available at https://github.com/amazon-science/information-preservation-in-prompt-compression.