LookAhead Tuning: Safer Language Models via Partial Answer Previews
作者: Kangwei Liu, Mengru Wang, Yujie Luo, Lin Yuan, Mengshu Sun, Lei Liang, Zhiqiang Zhang, Jun Zhou, Bryan Hooi, Shumin Deng
分类: cs.CL, cs.AI, cs.CV, cs.LG, cs.MM
发布日期: 2025-03-24 (更新: 2025-12-19)
备注: WSDM 2026 short
💡 一句话要点
LookAhead Tuning:通过预览部分答案前缀,提升微调后语言模型的安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全性对齐 微调 数据增强 LookAhead Tuning
📋 核心要点
- 微调虽能使LLM适应特定领域,但常牺牲其安全性对齐,现有方法难以兼顾性能与安全。
- LookAhead Tuning通过预览部分答案前缀修改训练数据,减少对模型初始token分布的扰动,维持安全机制。
- 实验表明,LookAhead Tuning在保持模型安全性的同时,保证了下游任务的性能。
📝 摘要(中文)
微调使得大型语言模型(LLMs)能够适应特定领域,但通常会损害其先前建立的安全对齐。为了减轻微调过程中模型安全性的降低,我们引入了LookAhead Tuning,这是一种轻量级且有效的数据驱动方法,可在微调期间保持安全性。该方法引入了两种简单的策略,通过预览部分答案前缀来修改训练数据,从而最大限度地减少对模型初始token分布的扰动,并保持其内置的安全机制。综合实验表明,LookAhead Tuning有效地保持了模型安全性,而不会牺牲下游任务的强大性能。我们的研究结果表明,LookAhead Tuning是LLM安全有效适应的一种可靠且高效的解决方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在微调过程中出现的安全性下降问题。现有微调方法往往会破坏模型原有的安全对齐,导致模型产生有害或不安全的输出。因此,如何在微调过程中保持或提升模型的安全性,同时保证其在目标任务上的性能,是一个重要的挑战。
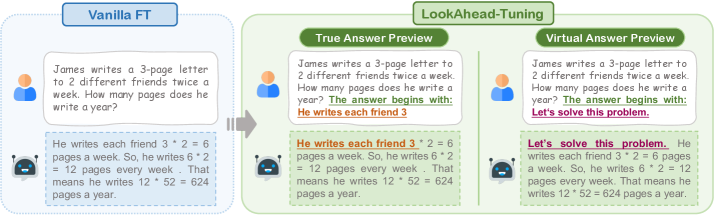
核心思路:LookAhead Tuning的核心思路是通过在训练数据中引入“部分答案预览”机制,来引导模型学习安全的输出。具体来说,该方法在训练时,不是直接给出完整的答案,而是先给出一个答案的前缀(即“look ahead”),让模型先基于这个前缀进行预测,然后再给出完整的答案。这样可以减少模型对不安全token的暴露,从而降低产生不安全输出的风险。
技术框架:LookAhead Tuning主要包含两个策略:1) Prefix Preview: 在训练数据中,将完整答案替换为答案的前缀,迫使模型基于前缀进行预测。2) Full Answer Completion: 在Prefix Preview的基础上,再给出完整的答案,让模型学习从前缀到完整答案的映射。整个过程可以看作是一种数据增强方法,旨在引导模型学习安全的输出模式。
关键创新:LookAhead Tuning的关键创新在于其简单而有效的数据增强策略。与传统的微调方法相比,LookAhead Tuning不需要修改模型结构或引入额外的损失函数,而是通过修改训练数据来达到提升安全性的目的。这种方法具有轻量级、易于实现的优点,并且可以与其他安全对齐方法结合使用。
关键设计:LookAhead Tuning的关键设计在于如何选择合适的前缀长度。如果前缀太短,可能无法有效引导模型学习安全的输出;如果前缀太长,则可能降低模型在目标任务上的性能。论文中可能探讨了不同的前缀长度对模型安全性和性能的影响,并给出了选择前缀长度的建议(具体细节未知)。此外,损失函数通常采用标准的交叉熵损失函数,优化器也采用常用的Adam或SGD等优化器(具体细节未知)。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了LookAhead Tuning的有效性。实验结果表明,LookAhead Tuning在保持模型在下游任务上良好性能的同时,显著提升了模型的安全性。具体性能数据(例如,安全性指标的提升幅度、下游任务的准确率等)未知,但总体而言,LookAhead Tuning是一种在微调过程中保持LLM安全性的有效方法。
🎯 应用场景
LookAhead Tuning可应用于各种需要安全保障的大型语言模型应用场景,例如智能客服、内容生成、教育辅导等。通过该方法,可以降低模型产生有害、偏见或不当内容的风险,提升用户体验和信任度。该方法还有助于推动LLM在安全敏感领域的应用,例如医疗诊断、金融风控等。
📄 摘要(原文)
Fine-tuning enables large language models (LLMs) to adapt to specific domains, but often compromises their previously established safety alignment. To mitigate the degradation of model safety during fine-tuning, we introduce LookAhead Tuning, a lightweight and effective data-driven approach that preserves safety during fine-tuning. The method introduces two simple strategies that modify training data by previewing partial answer prefixes, thereby minimizing perturbations to the model's initial token distributions and maintaining its built-in safety mechanisms. Comprehensive experiments demonstrate that LookAhead Tuning effectively maintains model safety without sacrificing robust performance on downstream tasks. Our findings position LookAhead Tuning as a reliable and efficient solution for the safe and effective adaptation of LLMs.