Exploring Training and Inference Scaling Laws in Generative Retrieval
作者: Hongru Cai, Yongqi Li, Ruifeng Yuan, Wenjie Wang, Zhen Zhang, Wenjie Li, Tat-Seng Chua
分类: cs.IR, cs.CL
发布日期: 2025-03-24 (更新: 2025-06-08)
备注: Accepted to SIGIR 2025
💡 一句话要点
探索生成式检索中的训练和推理扩展定律,揭示模型规模、数据规模和计算资源对性能的影响。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成式检索 扩展定律 大型语言模型 信息检索 模型缩放
📋 核心要点
- 现有检索方法难以充分利用大型语言模型的生成能力,缺乏对生成式检索范式内在机制的深入理解。
- 论文通过系统研究模型大小、训练数据规模和推理计算对生成式检索性能的影响,揭示了扩展定律。
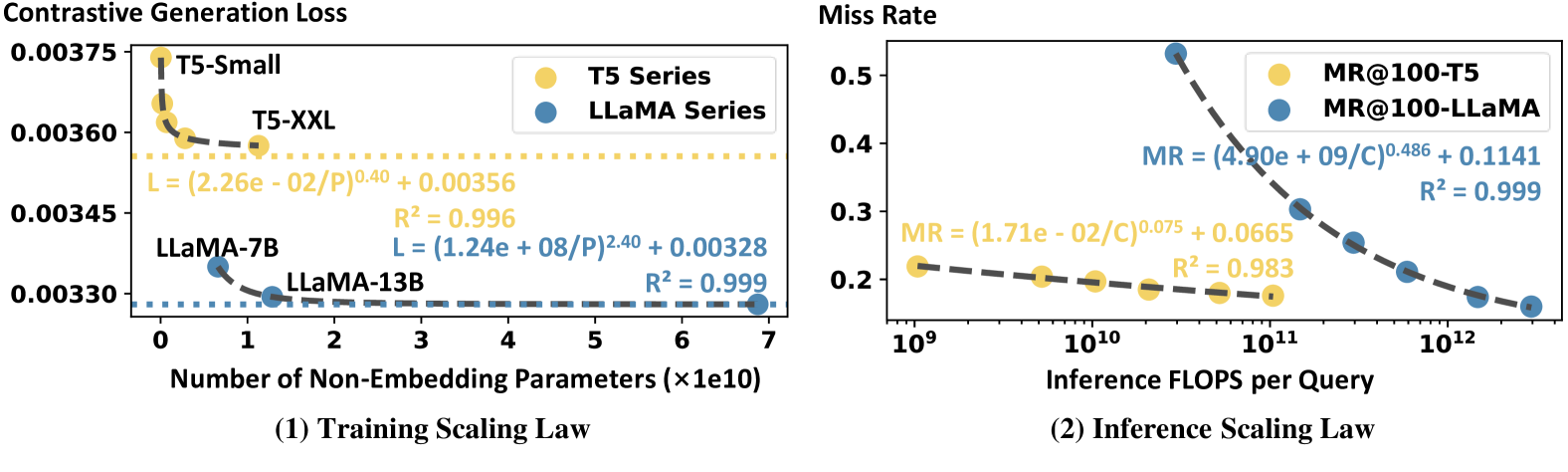
- 实验表明,增大模型、数据和计算量均能提升性能,且LLaMA模型优于T5模型,验证了扩展定律的有效性。
📝 摘要(中文)
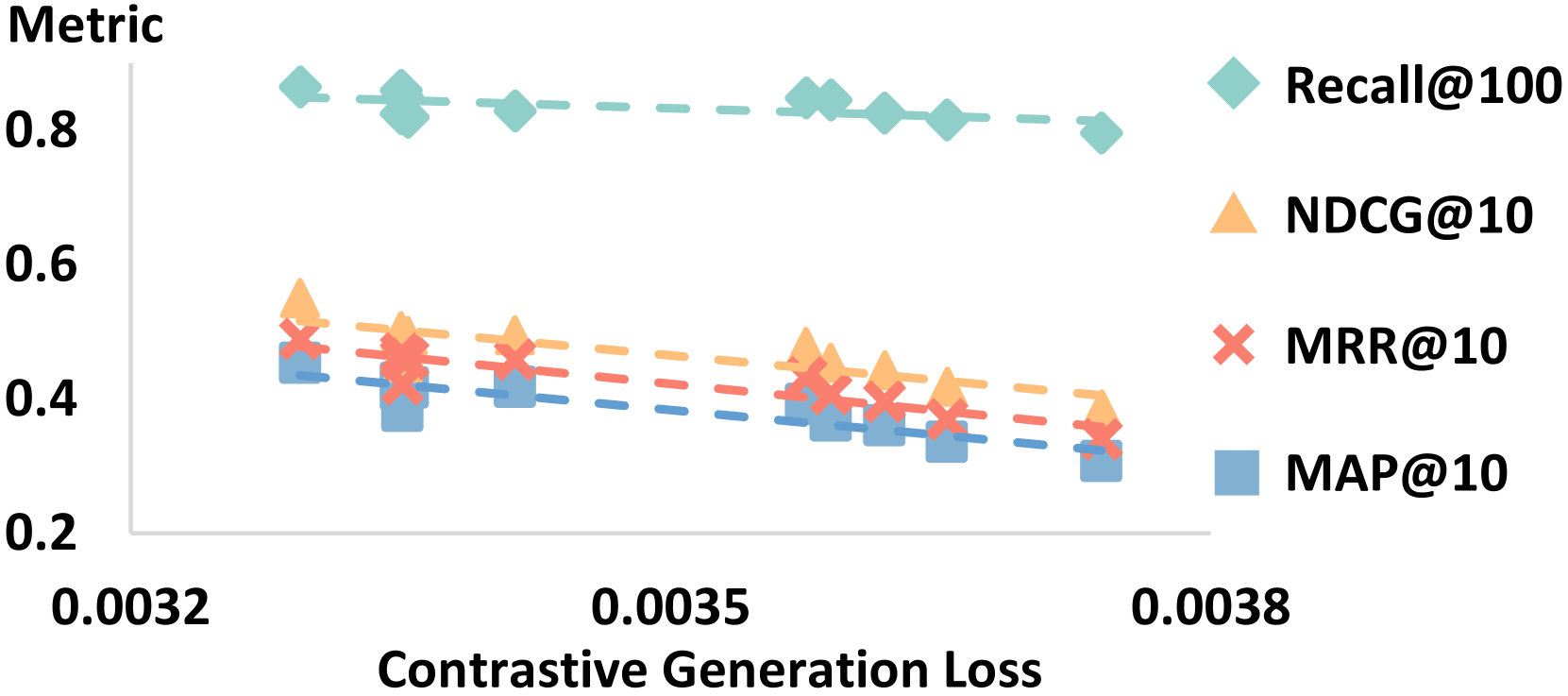
生成式检索将检索任务重构为自回归生成任务,其中大型语言模型(LLM)直接从查询生成目标文档。作为一种新颖的范式,其性能和可扩展性的机制在很大程度上仍未被探索。本文系统地研究了生成式检索中的训练和推理扩展定律,探讨了模型大小、训练数据规模和推理时计算如何共同影响性能。我们提出了一种受对比熵和生成损失启发的新的评估指标,提供了一种连续的性能信号,从而能够对不同的生成式检索方法进行稳健的比较。实验表明,基于n-gram的方法与训练和推理扩展定律高度一致。我们发现,增加模型大小、训练数据规模和推理时计算都有助于提高性能,突出了这些因素在增强生成式检索中的互补作用。在这些设置中,LLaMA模型始终优于T5模型,表明更大的仅解码器模型在生成式检索中具有特殊的优势。我们的研究结果强调,模型大小、数据可用性和推理计算相互作用,以释放生成式检索的全部潜力,为设计和优化未来的系统提供了新的见解。
🔬 方法详解
问题定义:论文旨在解决生成式检索中模型规模、训练数据规模和推理计算如何影响检索性能的问题。现有方法缺乏对这些因素之间相互作用的系统性研究,难以指导生成式检索系统的设计和优化。
核心思路:论文的核心思路是通过系统地探索训练和推理扩展定律,量化模型大小、训练数据规模和推理时计算对生成式检索性能的影响。通过分析这些因素之间的关系,揭示生成式检索的内在机制,为未来的系统设计提供指导。
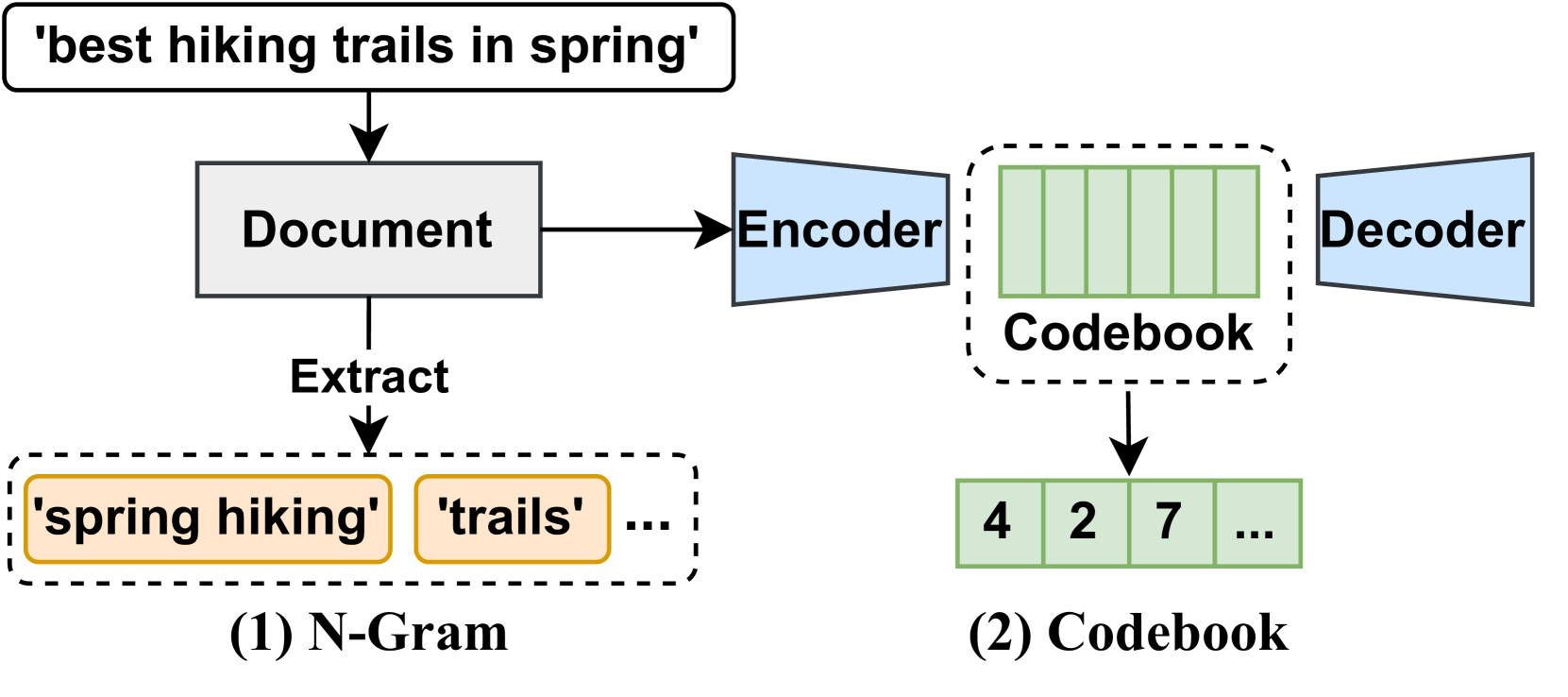
技术框架:论文的技术框架主要包括以下几个部分:1) 使用大型语言模型(如T5和LLaMA)作为生成器;2) 通过自回归生成的方式,直接从查询生成目标文档的ID;3) 提出一种新的评估指标,该指标基于对比熵和生成损失,能够提供连续的性能信号;4) 系统地进行实验,改变模型大小、训练数据规模和推理时计算,观察性能变化。
关键创新:论文的关键创新在于:1) 系统地研究了生成式检索中的训练和推理扩展定律,揭示了模型大小、数据规模和计算资源对性能的综合影响;2) 提出了一种新的评估指标,能够更准确地评估生成式检索的性能,并支持不同方法之间的比较;3) 实验结果表明,LLaMA模型在生成式检索中表现优于T5模型,为模型选择提供了新的见解。
关键设计:论文的关键设计包括:1) 使用不同的模型大小(例如,T5-small, T5-base, T5-large, LLaMA-7B, LLaMA-13B)来研究模型规模的影响;2) 使用不同规模的训练数据来研究数据规模的影响;3) 通过调整beam size等参数来控制推理时计算量;4) 使用负对数似然作为生成损失,并结合对比熵来评估检索性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,增加模型大小、训练数据规模和推理时计算都有助于提高生成式检索的性能。LLaMA模型在各种设置下均优于T5模型,表明decoder-only模型在生成式检索中具有优势。基于n-gram的方法与训练和推理扩展定律高度一致,验证了扩展定律的有效性。论文提出的新评估指标能够提供更准确的性能评估。
🎯 应用场景
该研究成果可应用于各种信息检索场景,例如问答系统、文档检索、代码检索等。通过优化模型大小、训练数据和推理计算,可以提升检索系统的效率和准确性,为用户提供更好的搜索体验。未来的研究可以进一步探索如何利用扩展定律来设计更高效的生成式检索系统。
📄 摘要(原文)
Generative retrieval reformulates retrieval as an autoregressive generation task, where large language models (LLMs) generate target documents directly from a query. As a novel paradigm, the mechanisms that underpin its performance and scalability remain largely unexplored. We systematically investigate training and inference scaling laws in generative retrieval, exploring how model size, training data scale, and inference-time compute jointly influence performance. We propose a novel evaluation metric inspired by contrastive entropy and generation loss, providing a continuous performance signal that enables robust comparisons across diverse generative retrieval methods. Our experiments show that n-gram-based methods align strongly with training and inference scaling laws. We find that increasing model size, training data scale, and inference-time compute all contribute to improved performance, highlighting the complementary roles of these factors in enhancing generative retrieval. Across these settings, LLaMA models consistently outperform T5 models, suggesting a particular advantage for larger decoder-only models in generative retrieval. Our findings underscore that model sizes, data availability, and inference computation interact to unlock the full potential of generative retrieval, offering new insights for designing and optimizing future systems.