xKV: Cross-Layer SVD for KV-Cache Compression
作者: Chi-Chih Chang, Chien-Yu Lin, Yash Akhauri, Wei-Cheng Lin, Kai-Chiang Wu, Luis Ceze, Mohamed S. Abdelfattah
分类: cs.CL, cs.LG
发布日期: 2025-03-24
🔗 代码/项目: GITHUB
💡 一句话要点
xKV:通过跨层奇异值分解压缩KV缓存,提升长文本LLM推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存压缩 奇异值分解 长上下文语言模型 低秩近似 模型推理加速
📋 核心要点
- 现有方法在压缩LLM的KV缓存时,要么需要大量预训练,要么依赖不成立的层间相似性假设,限制了压缩效率。
- xKV通过观察到KV缓存跨层奇异向量的对齐性,利用奇异值分解将多层KV缓存压缩到共享的低秩子空间。
- 实验表明,xKV在长文本基准测试中实现了更高的压缩率和准确率,并且与多头潜在注意力机制兼容。
📝 摘要(中文)
大规模语言模型(LLM)凭借其长上下文窗口实现了强大的应用,但也带来了存储键和值状态(KV缓存)的高内存消耗问题。现有研究尝试将多个层的KV缓存合并为共享表示,但这些方法要么需要昂贵的预训练,要么依赖于各层之间高token余弦相似度的假设,这在实践中通常不成立。我们发现,KV缓存中占主导地位的奇异向量在多个层中表现出显著的对齐性。基于此,我们提出xKV,一种简单的后训练方法,对分组层的KV缓存应用奇异值分解(SVD)。xKV将多个层的KV缓存整合到共享的低秩子空间中,显著降低了KV缓存的大小。在RULER长上下文基准上,对广泛使用的LLM(如Llama-3.1和Qwen2.5)进行的大量评估表明,xKV实现了比最先进的层间技术高出6.8倍的压缩率,同时提高了2.7%的准确率。此外,xKV与新兴的多头潜在注意力(MLA)(如DeepSeek-Coder-V2)兼容,在编码任务上实现了3倍的显著压缩率,且没有性能下降。这些结果突显了xKV在解决长上下文LLM推理的内存瓶颈方面的强大能力和通用性。我们的代码已在https://github.com/abdelfattah-lab/xKV上公开。
🔬 方法详解
问题定义:论文旨在解决大规模语言模型(LLM)推理过程中,由于长上下文窗口导致KV缓存占用大量内存的问题。现有方法,如直接合并KV缓存或依赖预训练的方法,要么效率不高,要么需要额外的训练成本,并且对层间相似性的假设在实际中往往不成立。
核心思路:论文的核心思路是利用KV缓存中奇异向量在不同层之间的对齐特性,通过奇异值分解(SVD)将多个层的KV缓存压缩到一个共享的低秩子空间。这种方法无需预训练,并且能够有效地降低KV缓存的大小。
技术框架:xKV的技术框架主要包括以下几个步骤:1) 对LLM进行推理,获取每一层的KV缓存;2) 将多个层的KV缓存进行分组;3) 对每组KV缓存进行奇异值分解,得到奇异值、奇异向量和低秩表示;4) 使用低秩表示替换原始的KV缓存,从而减少内存占用。推理时,使用低秩表示进行计算。
关键创新:xKV的关键创新在于发现了KV缓存跨层奇异向量的对齐性,并利用这一特性进行压缩。与现有方法相比,xKV无需预训练,且能够更有效地利用层间信息,实现更高的压缩率和准确率。
关键设计:xKV的关键设计包括:1) 如何选择分组的层数,这会影响压缩率和性能;2) 如何确定低秩子空间的维度,需要在压缩率和性能之间进行权衡;3) SVD分解的具体实现方式,可以选择不同的SVD算法以提高效率。
🖼️ 关键图片
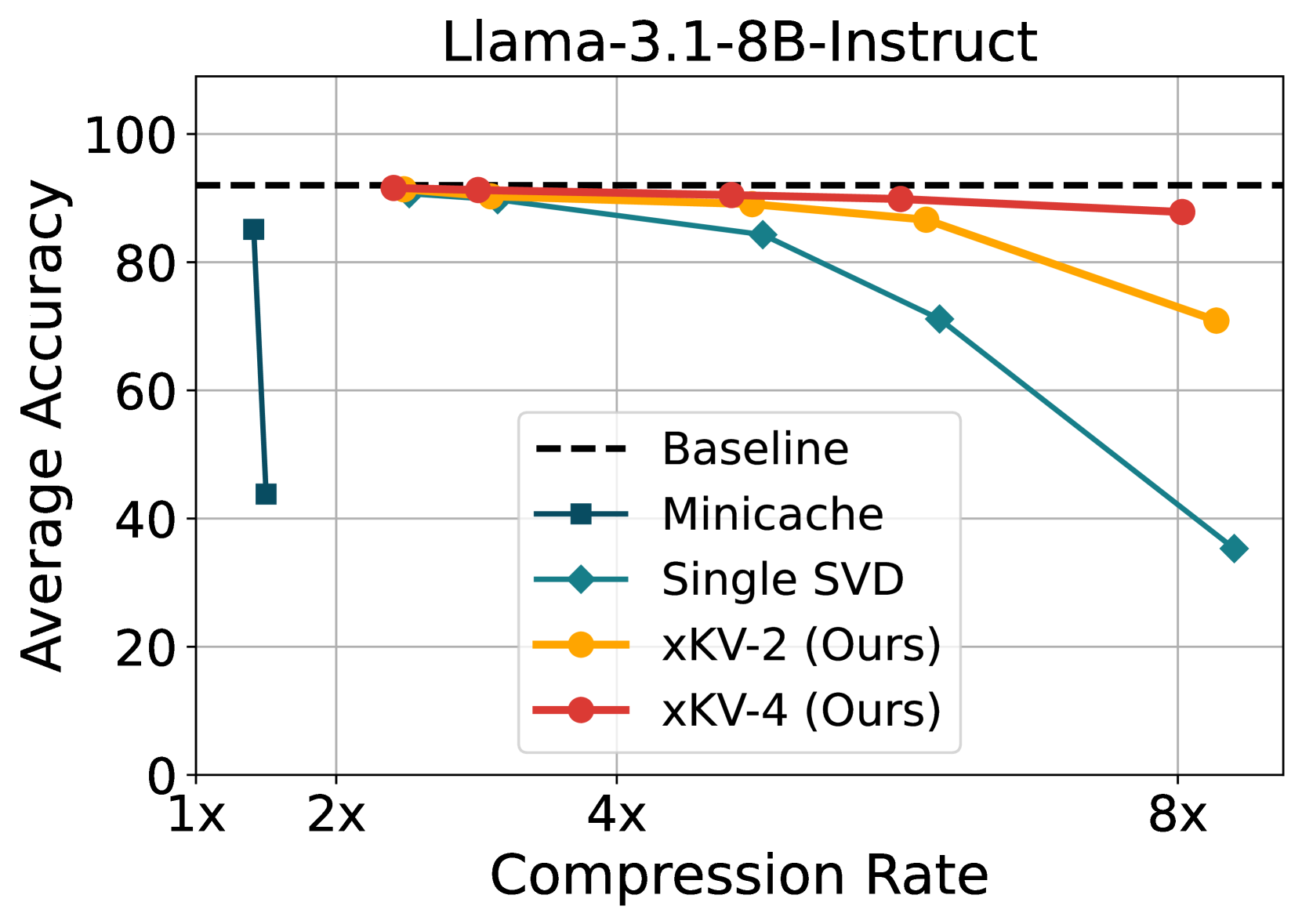
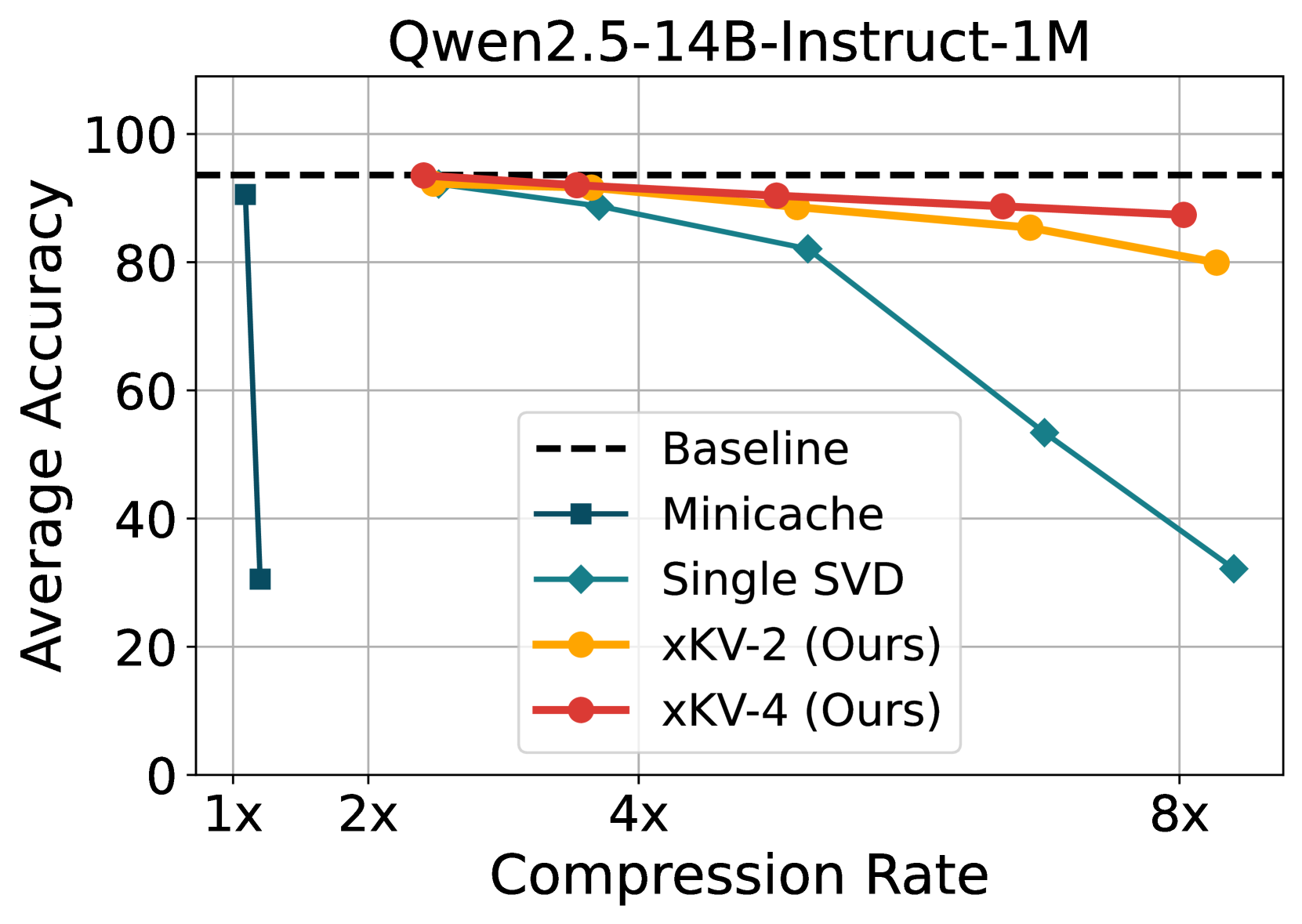

📊 实验亮点
实验结果表明,xKV在RULER长上下文基准测试中,相比于最先进的层间压缩技术,实现了高达6.8倍的压缩率,同时准确率提升了2.7%。此外,xKV在DeepSeek-Coder-V2等模型上,在编码任务中实现了3倍的压缩率,且没有性能下降,验证了其在不同模型和任务上的通用性。
🎯 应用场景
xKV技术可广泛应用于需要长上下文处理的大规模语言模型推理场景,例如长文档摘要、代码生成、对话系统等。通过降低KV缓存的内存占用,xKV能够显著提升LLM在资源受限设备上的部署能力,并降低推理成本,加速LLM的普及应用。
📄 摘要(原文)
Large Language Models (LLMs) with long context windows enable powerful applications but come at the cost of high memory consumption to store the Key and Value states (KV-Cache). Recent studies attempted to merge KV-cache from multiple layers into shared representations, yet these approaches either require expensive pretraining or rely on assumptions of high per-token cosine similarity across layers which generally does not hold in practice. We find that the dominant singular vectors are remarkably well-aligned across multiple layers of the KV-Cache. Exploiting this insight, we propose xKV, a simple post-training method that applies Singular Value Decomposition (SVD) on the KV-Cache of grouped layers. xKV consolidates the KV-Cache of multiple layers into a shared low-rank subspace, significantly reducing KV-Cache sizes. Through extensive evaluations on the RULER long-context benchmark with widely-used LLMs (e.g., Llama-3.1 and Qwen2.5), xKV achieves up to 6.8x higher compression rates than state-of-the-art inter-layer technique while improving accuracy by 2.7%. Moreover, xKV is compatible with the emerging Multi-Head Latent Attention (MLA) (e.g., DeepSeek-Coder-V2), yielding a notable 3x compression rates on coding tasks without performance degradation. These results highlight xKV's strong capability and versatility in addressing memory bottlenecks for long-context LLM inference. Our code is publicly available at: https://github.com/abdelfattah-lab/xKV.