Commander-GPT: Fully Unleashing the Sarcasm Detection Capability of Multi-Modal Large Language Models
作者: Yazhou Zhang, Chunwang Zou, Bo Wang, Jing Qin
分类: cs.CL, cs.AI
发布日期: 2025-03-24 (更新: 2025-07-03)
备注: Our original goal was to use Commander-GPT: Dividing and Routing for Multimodal Sarcasm Detection (arXiv:2506.19420) to replace Commander-GPT: Fully Unleashing the Sarcasm Detection Capability of Multi-Modal Large Language Models (arXiv:2503.18681). Due to various reasons, both versions were released, so we would like to withdraw the latter
💡 一句话要点
提出Commander-GPT框架,无需微调即可显著提升多模态大语言模型在讽刺检测任务上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态讽刺检测 大语言模型 任务分解 模型分配 情感分析 自然语言处理 Commander-GPT
📋 核心要点
- 现有讽刺检测方法难以有效利用多模态信息,导致识别精度不足,尤其是在处理隐晦的讽刺内容时。
- Commander-GPT框架将讽刺检测分解为多个子任务,并分配最合适的MLLM处理,实现更精细化的信息处理。
- 实验表明,该方法在MMSD和MMSD 2.0数据集上取得了SOTA性能,F1值提升19.3%,且无需微调。
📝 摘要(中文)
讽刺检测是自然语言处理领域中的一项重要研究方向,受到了广泛关注。传统的讽刺检测任务通常侧重于单模态方法(例如,文本),但由于讽刺的隐性和微妙性,这些方法往往无法产生令人满意的结果。近年来,研究人员已将讽刺检测的重点转移到多模态方法。然而,如何有效地利用多模态信息来准确识别讽刺内容仍然是一个值得进一步探索的挑战。本文利用多模态大语言模型(MLLM)对各种信息源的强大集成处理能力,提出了一种创新的多模态Commander-GPT框架。受到军事战略的启发,我们首先将讽刺检测任务分解为六个不同的子任务。然后,由中央指挥官(决策者)分配最适合的大语言模型来处理每个特定的子任务。最终,汇总来自每个模型的检测结果以识别讽刺。我们在MMSD和MMSD 2.0上进行了广泛的实验,使用了四个多模态大语言模型和六种提示策略。我们的实验表明,我们的方法实现了最先进的性能,F1得分提高了19.3%,而无需进行微调或使用ground-truth rationales。
🔬 方法详解
问题定义:论文旨在解决多模态讽刺检测问题,现有方法难以有效融合多模态信息,导致检测精度不高。传统的单模态方法无法捕捉讽刺的微妙之处,而直接应用多模态大模型可能无法充分利用各模态的优势信息。
核心思路:论文的核心思路是将复杂的讽刺检测任务分解为多个更易于处理的子任务,并针对每个子任务选择最合适的MLLM进行处理。这种“分而治之”的策略能够更有效地利用不同模型的优势,提升整体检测性能。借鉴军事指挥体系,设立“指挥官”角色进行任务分配和结果整合。
技术框架:Commander-GPT框架包含以下主要模块:1) 任务分解模块:将讽刺检测任务分解为六个子任务(具体子任务内容未知)。2) 模型选择与分配模块:根据子任务的特点,选择并分配最合适的MLLM进行处理。3) 多模态信息处理模块:每个MLLM根据分配的任务,处理相应的多模态信息(文本、图像等)。4) 结果聚合模块:将各个MLLM的输出结果进行整合,最终判断是否存在讽刺。
关键创新:该方法的核心创新在于任务分解和模型分配策略。通过将复杂的任务分解为更小的、更具体的子任务,可以更好地利用不同MLLM的优势。此外,引入“指挥官”角色进行任务分配和结果整合,模拟了人类解决复杂问题的思维方式。避免了对单个大型模型进行微调,降低了计算成本。
关键设计:论文使用了四个多模态大语言模型(具体模型未知)和六种提示策略(具体策略未知)。任务分解的具体方式和子任务的定义是关键设计之一,但论文摘要中未详细说明。结果聚合模块的具体算法也未知。损失函数和网络结构等细节未提及,因为该方法主要依赖于现有MLLM的能力,而非从头训练模型。
🖼️ 关键图片
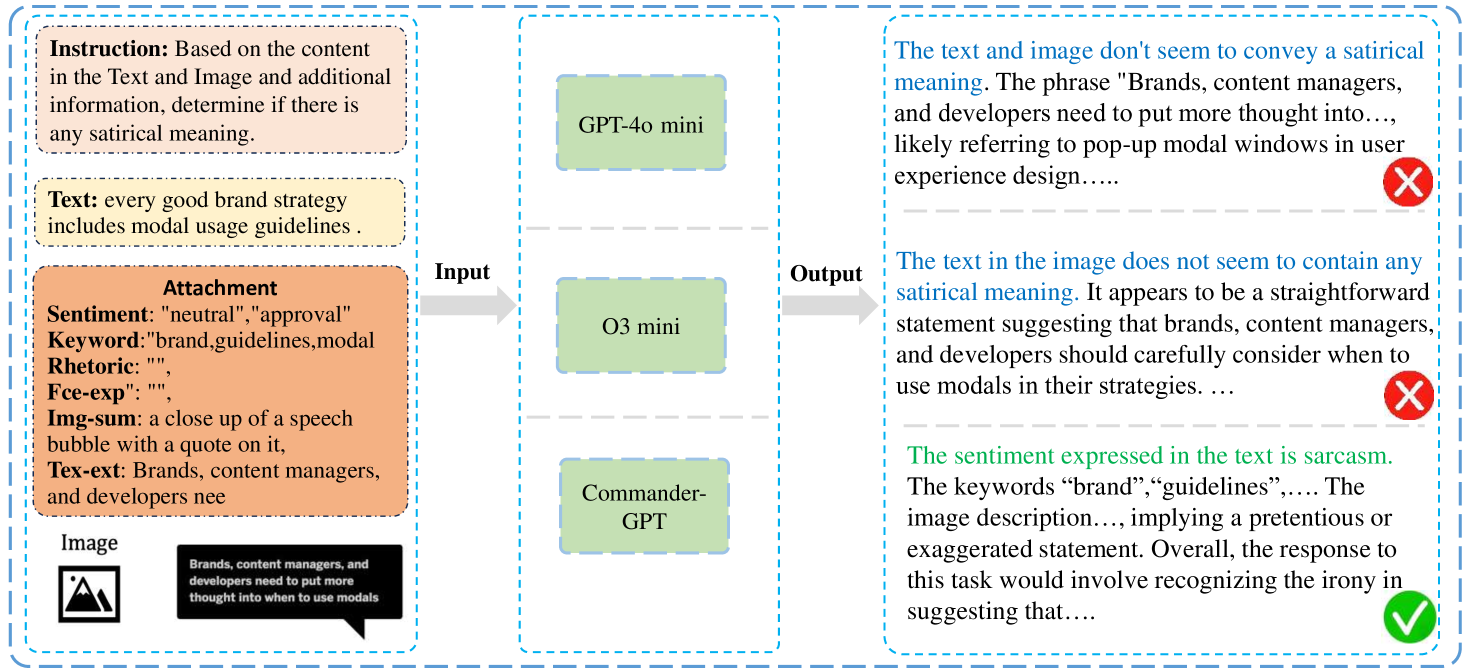
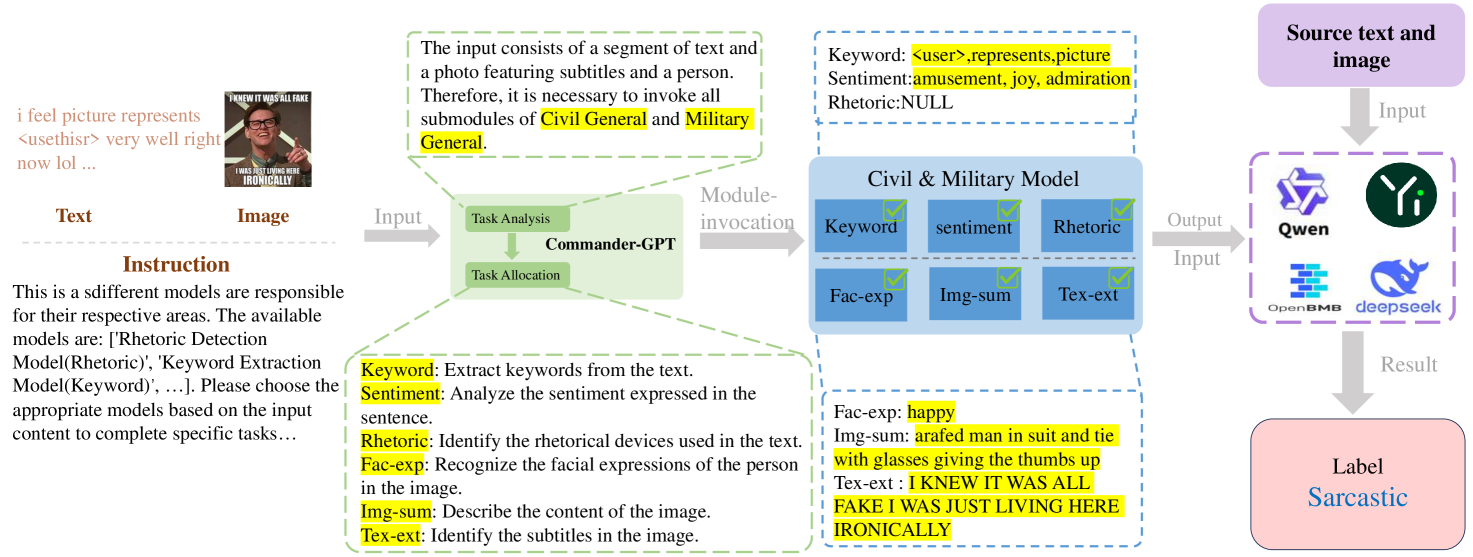

📊 实验亮点
Commander-GPT框架在MMSD和MMSD 2.0数据集上取得了显著的性能提升,F1得分提高了19.3%,达到了state-of-the-art水平。值得注意的是,该方法无需对MLLM进行微调,降低了计算成本,并避免了过拟合的风险。实验结果表明,任务分解和模型分配策略能够有效提升多模态讽刺检测的性能。
🎯 应用场景
该研究成果可应用于社交媒体情感分析、舆情监控、智能客服等领域。准确识别讽刺言论有助于更全面地理解用户意图,避免误解和错误决策。未来,该方法可以扩展到其他需要理解复杂语境的任务中,例如幽默识别、恶意评论检测等。
📄 摘要(原文)
Sarcasm detection, as a crucial research direction in the field of Natural Language Processing (NLP), has attracted widespread attention. Traditional sarcasm detection tasks have typically focused on single-modal approaches (e.g., text), but due to the implicit and subtle nature of sarcasm, such methods often fail to yield satisfactory results. In recent years, researchers have shifted the focus of sarcasm detection to multi-modal approaches. However, effectively leveraging multi-modal information to accurately identify sarcastic content remains a challenge that warrants further exploration. Leveraging the powerful integrated processing capabilities of Multi-Modal Large Language Models (MLLMs) for various information sources, we propose an innovative multi-modal Commander-GPT framework. Inspired by military strategy, we first decompose the sarcasm detection task into six distinct sub-tasks. A central commander (decision-maker) then assigns the best-suited large language model to address each specific sub-task. Ultimately, the detection results from each model are aggregated to identify sarcasm. We conducted extensive experiments on MMSD and MMSD 2.0, utilizing four multi-modal large language models and six prompting strategies. Our experiments demonstrate that our approach achieves state-of-the-art performance, with a 19.3% improvement in F1 score, without necessitating fine-tuning or ground-truth rationales.