"Whose Side Are You On?" Estimating Ideology of Political and News Content Using Large Language Models and Few-shot Demonstration Selection
作者: Muhammad Haroon, Magdalena Wojcieszak, Anshuman Chhabra
分类: cs.CL, cs.CY, cs.SI
发布日期: 2025-03-23 (更新: 2025-11-11)
💡 一句话要点
利用大语言模型和少样本演示选择,估计政治和新闻内容的意识形态倾向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 上下文学习 意识形态分类 少样本学习 政治观点分析
📋 核心要点
- 现有意识形态分类方法依赖大量人工标注和大型数据集,难以适应快速变化的意识形态环境。
- 该论文提出利用大语言模型(LLMs)的上下文学习能力,通过少样本演示选择来分类在线内容的政治意识形态。
- 实验结果表明,该方法在新闻文章和YouTube视频数据集上,显著优于零样本和传统监督方法。
📝 摘要(中文)
社交媒体平台的快速发展引发了对激进化、信息茧房和内容偏见的担忧。现有的意识形态分类方法需要大量的人工标注,依赖于大型数据集,并且难以适应不断变化的意识形态环境。本文探索了使用大语言模型(LLMs)通过上下文学习(ICL)来分类在线内容的政治意识形态的潜力。我们对包含新闻文章和YouTube视频的三个数据集进行了广泛的实验,实验中采用了标签平衡的演示选择方法,结果表明我们的方法明显优于零样本和传统的监督方法。此外,我们评估了元数据(例如,内容来源和描述)对意识形态分类的影响,并讨论了其意义。最后,我们展示了提供政治和非政治内容来源如何影响LLM的分类。
🔬 方法详解
问题定义:论文旨在解决在线内容政治意识形态分类的问题。现有方法的痛点在于需要大量人工标注数据,成本高昂且难以适应意识形态的快速演变,同时传统监督学习方法泛化能力有限。
核心思路:论文的核心思路是利用大语言模型(LLMs)的上下文学习(In-Context Learning, ICL)能力,通过提供少量示例(few-shot demonstrations)来引导LLM进行意识形态分类。这种方法避免了大规模数据标注,并能更好地适应新的意识形态语境。
技术框架:整体框架包括以下几个主要阶段:1)数据准备:收集包含政治和新闻内容的数据集,例如新闻文章和YouTube视频。2)演示选择:从数据集中选择少量具有代表性的示例作为LLM的上下文输入,论文采用标签平衡的方式进行选择,以避免偏差。3)LLM推理:将选择的示例和待分类的内容输入LLM,LLM根据上下文进行意识形态分类。4)结果评估:评估LLM的分类准确率,并与零样本和传统监督方法进行比较。
关键创新:最重要的技术创新点在于利用了LLM的上下文学习能力,通过少样本演示选择来解决意识形态分类问题。与传统方法相比,该方法无需大规模数据标注,并且能够更好地适应新的意识形态语境。此外,论文还研究了元数据(如内容来源)对分类结果的影响。
关键设计:论文的关键设计包括:1)标签平衡的演示选择:确保选择的示例在不同意识形态类别中分布均匀,以避免偏差。2)元数据的使用:研究内容来源等元数据对分类结果的影响,例如,提供内容来源信息可能会影响LLM的分类结果。3)数据集选择:使用了包含新闻文章和YouTube视频的多个数据集,以验证方法的泛化能力。
🖼️ 关键图片
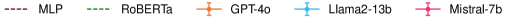
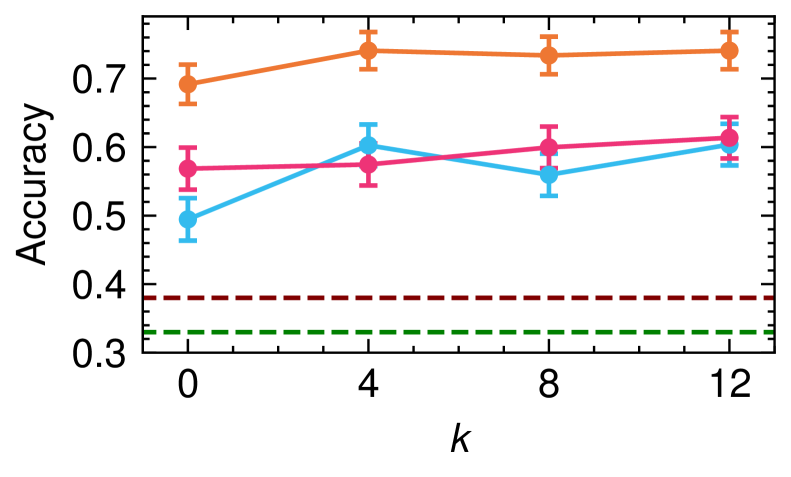
📊 实验亮点
实验结果表明,该方法在三个数据集上均显著优于零样本和传统监督方法。通过标签平衡的演示选择,该方法能够有效利用LLM的上下文学习能力,实现更准确的意识形态分类。此外,研究还发现,提供内容来源信息会影响LLM的分类结果,这表明LLM可能存在一定的偏见。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核、新闻推荐系统的个性化推荐、以及政治观点分析等领域。通过自动识别内容的意识形态倾向,可以帮助用户过滤信息、避免信息茧房,并促进更客观的政治讨论。未来,该技术可用于检测虚假信息和操纵性内容,维护健康的在线生态环境。
📄 摘要(原文)
The rapid growth of social media platforms has led to concerns about radicalization, filter bubbles, and content bias. Existing approaches to classifying ideology are limited in that they require extensive human effort, the labeling of large datasets, and are not able to adapt to evolving ideological contexts. This paper explores the potential of Large Language Models (LLMs) for classifying the political ideology of online content through in-context learning (ICL). Our extensive experiments involving demonstration selection in label-balanced fashion, conducted on three datasets comprising news articles and YouTube videos, reveal that our approach significantly outperforms zero-shot and traditional supervised methods. Additionally, we evaluate the influence of metadata (e.g., content source and descriptions) on ideological classification and discuss its implications. Finally, we show how providing the source for political and non-political content influences the LLM's classification.