Inverse Reinforcement Learning with Dynamic Reward Scaling for LLM Alignment
作者: Ruoxi Cheng, Haoxuan Ma, Weixin Wang, Ranjie Duan, Jiexi Liu, Xiaoshuang Jia, Simeng Qin, Xiaochun Cao, Yang Liu, Xiaojun Jia
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-23 (更新: 2025-09-25)
备注: The first three authors contributed equally to this work
💡 一句话要点
提出DR-IRL,通过动态奖励调整提升LLM安全对齐效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全对齐 逆强化学习 动态奖励缩放 奖励模型
📋 核心要点
- 现有LLM对齐方法面临安全数据集不平衡和静态奖励模型忽略任务难度的挑战,限制了优化效率。
- DR-IRL通过逆强化学习训练类别特定的奖励模型,并动态调整奖励,以平衡数据集和考虑任务难度。
- 实验表明,DR-IRL在安全对齐方面优于现有方法,同时保持了LLM的有用性。
📝 摘要(中文)
对齐对于安全部署大型语言模型(LLM)至关重要。现有技术分为基于奖励(在偏好对上训练奖励模型,并使用强化学习进行优化)和无奖励(直接在排序的输出上进行微调)两种。最近的研究表明,经过良好调整的基于奖励的流程仍然稳健,并且单响应演示可以优于成对偏好数据。然而,仍然存在两个挑战:(1)不平衡的安全数据集,过度表示常见危害,而忽略了长尾威胁;(2)静态奖励模型,忽略了任务难度,限制了优化效率和可获得的收益。我们提出了DR-IRL(通过逆强化学习动态调整奖励)。我们首先使用通过IRL获得的平衡安全数据集,训练特定类别的奖励模型,涵盖七个有害类别。然后,我们通过引入动态奖励缩放来增强Group Relative Policy Optimization(GRPO)——通过任务难度调整奖励——数据级别的难度通过文本编码器余弦相似度衡量,模型级别的响应性通过奖励差距衡量。跨各种基准和LLM的广泛实验表明,DR-IRL在安全对齐方面优于所有基线方法,同时保持了有用性。
🔬 方法详解
问题定义:现有基于奖励的LLM对齐方法,如使用强化学习微调LLM以最大化奖励模型预测的奖励,存在两个主要痛点。一是安全数据集通常不平衡,常见危害数据量大,而长尾风险数据不足,导致模型对常见风险过拟合,对罕见风险应对不足。二是静态奖励模型无法区分任务难度,对所有样本给予相同的奖励信号,导致优化效率低下,难以达到最佳性能。
核心思路:DR-IRL的核心思路是通过逆强化学习(IRL)学习类别特定的奖励模型,并引入动态奖励缩放机制,根据任务难度动态调整奖励。IRL用于从专家数据中推断奖励函数,从而解决数据集不平衡问题。动态奖励缩放则根据数据层面的难度(通过文本编码器余弦相似度衡量)和模型层面的响应性(通过奖励差距衡量)调整奖励,从而提高优化效率。
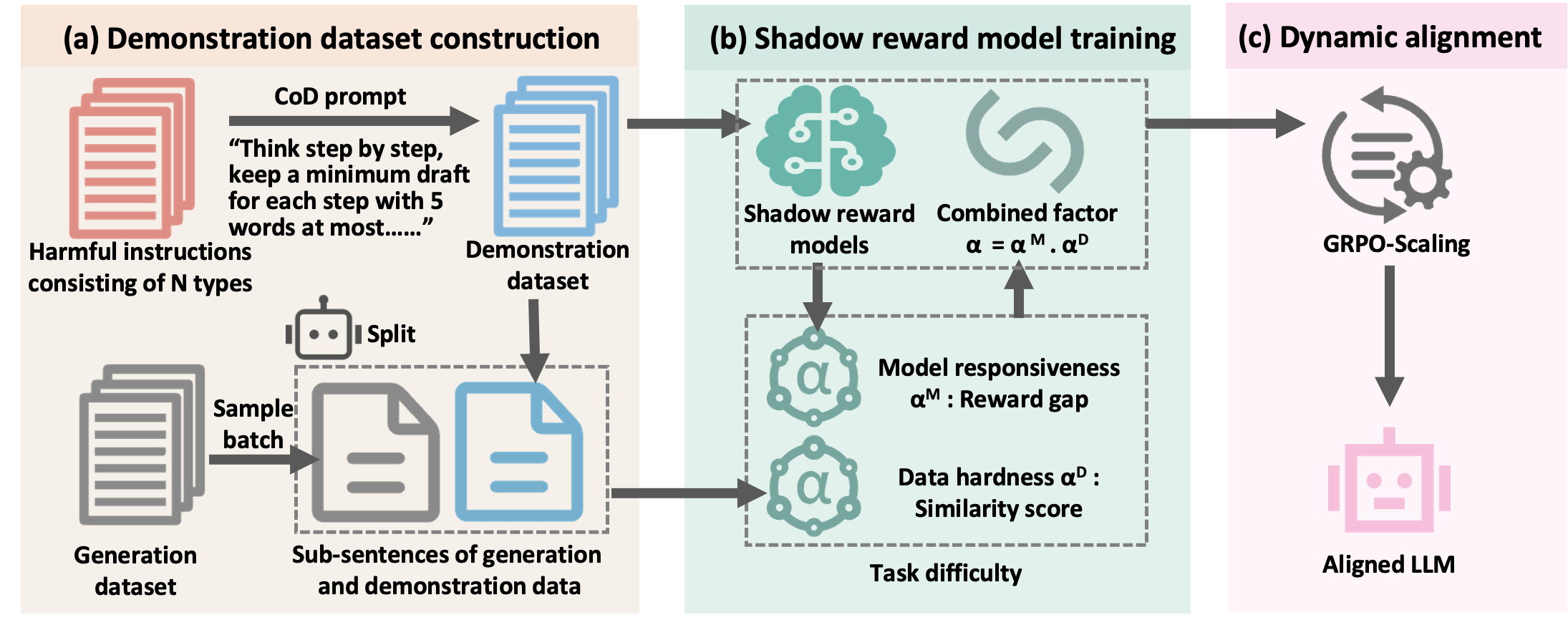
技术框架:DR-IRL的整体框架包含两个主要阶段。首先,使用逆强化学习训练类别特定的奖励模型。具体而言,针对七个有害类别,使用平衡的安全数据集,通过IRL学习每个类别的奖励函数。其次,使用增强的Group Relative Policy Optimization(GRPO)进行策略优化。在GRPO中,引入动态奖励缩放机制,根据任务难度动态调整奖励。
关键创新:DR-IRL的关键创新在于动态奖励缩放机制。传统的奖励模型是静态的,无法区分任务难度。DR-IRL通过文本编码器计算数据层面的难度,并通过奖励差距衡量模型层面的响应性,从而动态调整奖励。这种动态调整机制可以更有效地利用奖励信号,提高优化效率。
关键设计:DR-IRL的关键设计包括:1) 使用逆强化学习训练类别特定的奖励模型,平衡安全数据集;2) 使用文本编码器(如Sentence-BERT)计算数据层面的难度,通过余弦相似度衡量;3) 使用奖励差距(即模型对不同响应的奖励差异)衡量模型层面的响应性;4) 将数据层面难度和模型层面响应性结合起来,动态调整奖励。
🖼️ 关键图片
📊 实验亮点
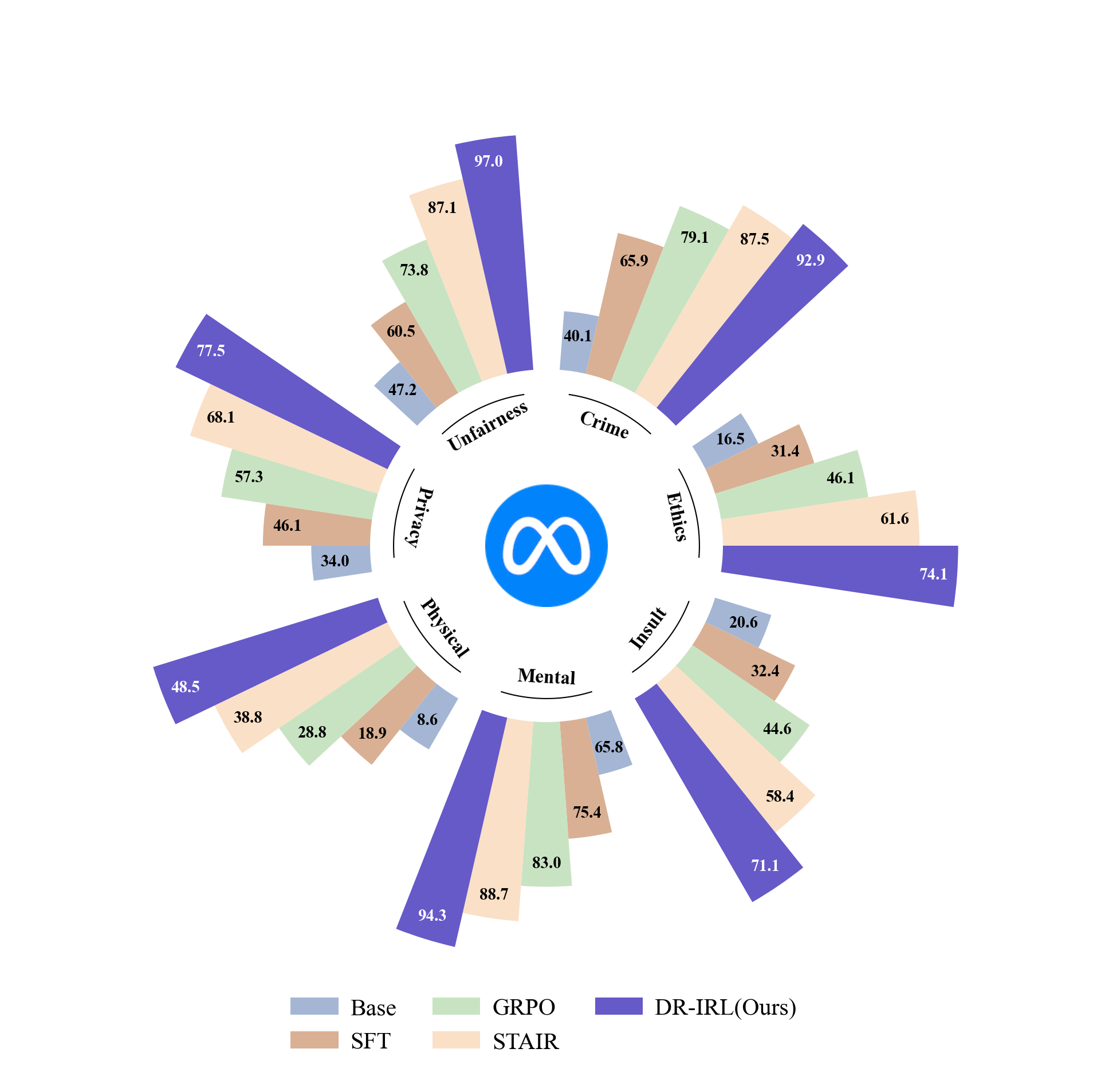
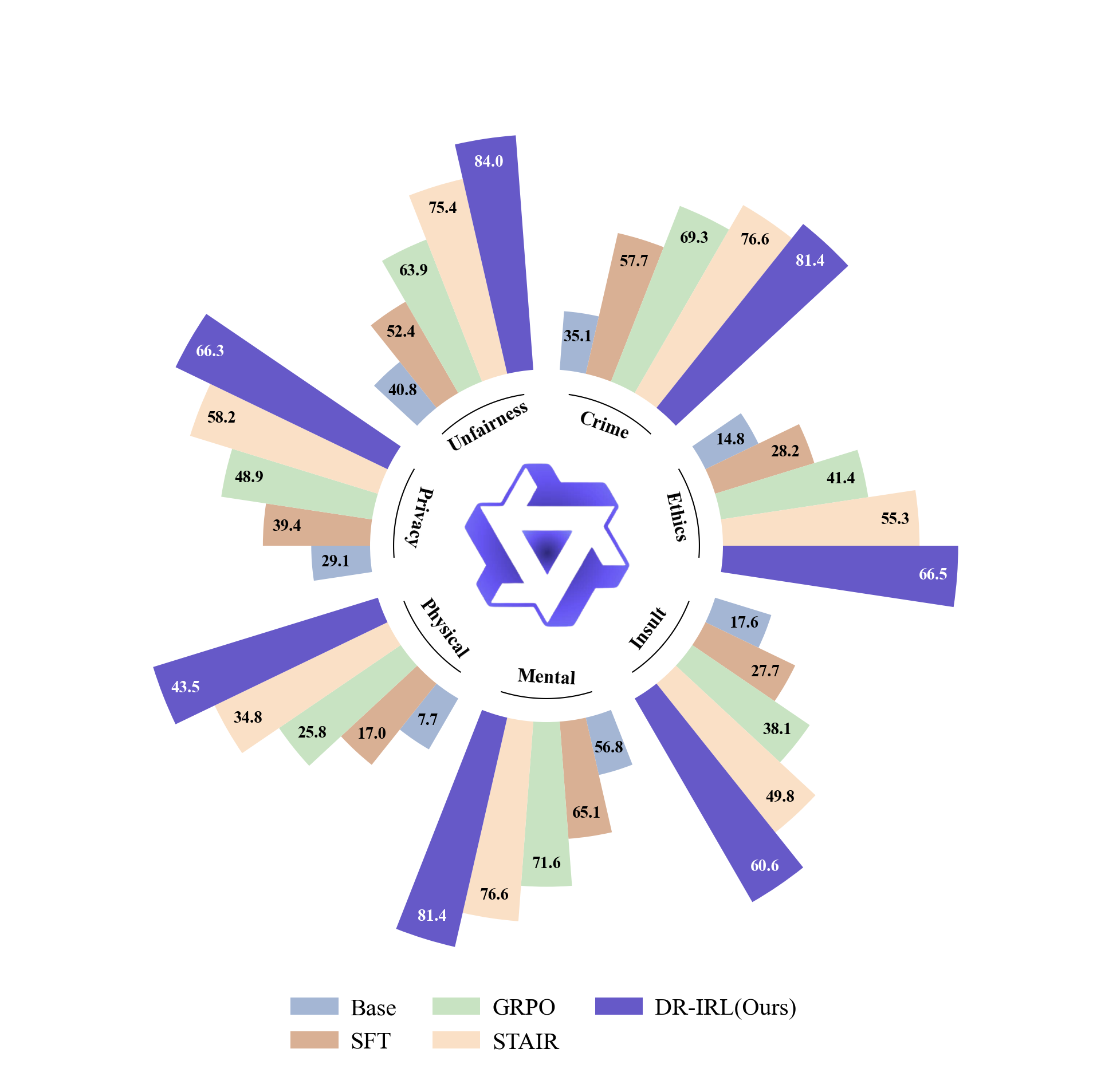
实验结果表明,DR-IRL在多个安全基准测试中优于所有基线方法,包括在安全性方面显著提升,同时保持了LLM的有用性。具体性能提升数据未知,但论文强调DR-IRL在安全对齐方面具有显著优势。
🎯 应用场景
DR-IRL可应用于各种需要安全对齐的大型语言模型,例如聊天机器人、内容生成系统和智能助手。通过提高LLM的安全性和可靠性,DR-IRL有助于减少有害内容的生成,提升用户体验,并促进LLM在更广泛领域的应用。
📄 摘要(原文)
Alignment is vital for safely deploying large language models (LLMs). Existing techniques are either reward-based (train a reward model on preference pairs and optimize with reinforcement learning) or reward-free (directly fine-tune on ranked outputs). Recent research shows that well-tuned reward-based pipelines remain robust, and single-response demonstrations can outperform pairwise preference data. However, two challenges persist: (1) imbalanced safety datasets that overrepresent common hazards while neglecting long-tail threats; and (2) static reward models that ignore task difficulty, limiting optimization efficiency and attainable gains. We propose DR-IRL (Dynamically adjusting Rewards through Inverse Reinforcement Learning). We first train category-specific reward models using a balanced safety dataset covering seven harmful categories via IRL. Then we enhance Group Relative Policy Optimization (GRPO) by introducing dynamic reward scaling--adjusting rewards by task difficulty--data-level hardness by text encoder cosine similarity, model-level responsiveness by reward gaps. Extensive experiments across various benchmarks and LLMs demonstrate that DR-IRL outperforms all baseline methods in safety alignment while maintaining usefulness.