WindowKV: Task-Adaptive Group-Wise KV Cache Window Selection for Efficient LLM Inference
作者: Youhui Zuo, Sibo Wei, Chen Zhang, Zhuorui Liu, Wenpeng Lu, Dawei Song
分类: cs.CL
发布日期: 2025-03-23 (更新: 2025-03-27)
💡 一句话要点
提出WindowKV,一种任务自适应的分组KV缓存窗口选择方法,用于高效LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存压缩 长上下文推理 大型语言模型 任务自适应 窗口选择 语义连贯性 内存优化
📋 核心要点
- 现有KV缓存压缩方法忽略了语义连贯性和任务特定特征,导致压缩性能受限。
- WindowKV通过动态选择局部语义窗口,并结合组内层KV缓存索引共享策略,实现高效压缩。
- 实验表明,WindowKV在LongBench上仅使用12%的KV缓存,性能与完整KV缓存相当,并在Needle-in-a-Haystack评估中达到SOTA。
📝 摘要(中文)
随着大型语言模型(LLM)长上下文推理能力的进步,KV缓存已成为基础组件之一。然而,其巨大的GPU内存消耗使得KV缓存压缩成为在工业场景中实现高效LLM推理的关键技术。虽然最近的研究主要集中在优化KV缓存占用的内存上,但它们忽略了两个关键因素:保持语义连贯性和考虑压缩期间的任务特定特征。为了解决这些限制,我们提出了一种新颖的任务自适应KV缓存窗口选择方法WindowKV。WindowKV根据任务特定特征动态选择由连续token组成的局部语义窗口,确保保留的KV缓存捕获连续的、必要的上下文。此外,我们引入了一种组内层KV缓存索引共享策略,以减少计算开销,从而在性能和效率之间取得平衡。我们在LongBench基准上严格评估了WindowKV,结果表明,它在仅使用原始KV缓存的12%的情况下,保持了与完整KV缓存保留相当的性能,显著降低了内存需求。此外,我们的方法还在Needle-in-a-Haystack评估中取得了最先进的结果,突出了其有效性和鲁棒性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型推理过程中KV缓存占用大量GPU内存的问题,现有KV缓存压缩方法通常忽略了语义连贯性以及不同任务的特性,导致压缩后的性能下降,无法满足实际应用需求。
核心思路:论文的核心思路是根据任务的特性,动态地选择具有语义连贯性的局部窗口作为KV缓存,从而在保证性能的同时,显著减少KV缓存的大小。通过保留关键的上下文信息,避免了盲目压缩导致的性能损失。
技术框架:WindowKV方法主要包含两个阶段:1) 任务自适应窗口选择:根据任务特性,动态选择包含连续token的局部语义窗口。具体实现可能涉及计算token之间的相关性或使用注意力机制来确定窗口边界。2) 组内层KV缓存索引共享:在同一组内的不同层之间共享KV缓存索引,进一步减少计算开销。
关键创新:WindowKV的关键创新在于任务自适应的窗口选择机制,它能够根据不同的任务动态地调整KV缓存的保留策略,从而更好地适应任务的需求。与传统的静态压缩方法相比,WindowKV能够更有效地保留关键的上下文信息,提高压缩后的性能。
关键设计:具体的技术细节可能包括:窗口大小的选择策略(例如,基于任务的token重要性或注意力权重),窗口选择的阈值设定,以及组内层KV缓存索引共享的具体实现方式(例如,使用哈希表或索引映射)。损失函数的设计可能需要考虑保留信息的完整性和压缩比例之间的平衡。
🖼️ 关键图片


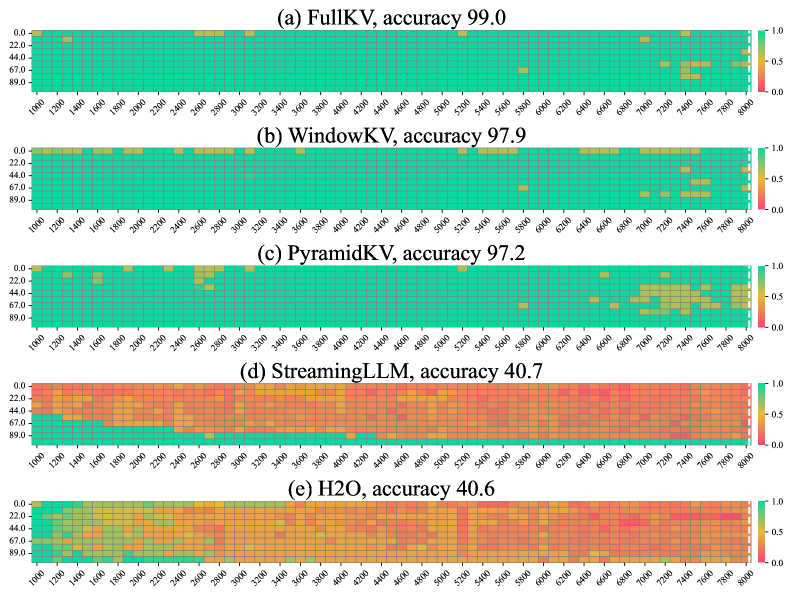
📊 实验亮点
WindowKV在LongBench基准测试中,仅使用原始KV缓存的12%就达到了与完整KV缓存相当的性能。此外,在Needle-in-a-Haystack评估中,WindowKV取得了当前最优的结果,证明了其在长上下文信息检索方面的有效性和鲁棒性。这些实验结果表明WindowKV在降低内存需求的同时,能够保持甚至提升LLM的推理性能。
🎯 应用场景
WindowKV技术可广泛应用于各种需要长上下文推理的大型语言模型应用场景,例如:智能客服、文档摘要、代码生成、机器翻译等。通过降低KV缓存的内存需求,该技术可以使LLM在资源受限的设备上运行,并提高推理效率,具有重要的实际应用价值和商业潜力。
📄 摘要(原文)
With the advancements in long-context inference capabilities of large language models (LLMs), the KV cache has become one of the foundational components. However, its substantial GPU memory consumption makes KV cache compression a key technique for enabling efficient LLM inference in industrial scenarios. While recent studies have focused on optimizing the memory occupied by the KV cache, they overlook two critical factors: preserving semantic coherence and considering task-specific characteristic during compression. To address these limitations, we propose a novel task-adaptive KV cache window selection method, WindowKV. WindowKV dynamically selects local semantic windows consisting of consecutive tokens, according to task-specific characteristics, ensuring the retained KV cache captures continuous, essential context. Additionally, we introduce an intra-group layer KV cache indices sharing strategy to reduce computational overhead, achieving a balance between performance and efficiency. We rigorously evaluate WindowKV on the LongBench benchmark, and the results demonstrate that it maintains a performance comparable to full KV cache retention while using only 12% of the original KV cache, significantly reducing memory requirements. Furthermore, our method also achieves state-of-the-art results in the Needle-in-a-Haystack evaluation, highlighting its effectiveness and robustness.