Improving Preference Extraction In LLMs By Identifying Latent Knowledge Through Classifying Probes
作者: Sharan Maiya, Yinhong Liu, Ramit Debnath, Anna Korhonen
分类: cs.CL, cs.LG
发布日期: 2025-03-22
备注: preprint, submitted to ACL ARR 2025, 21 pages, 23 figures
💡 一句话要点
提出基于分类探针的偏好提取方法,提升LLM作为评估者的准确性和效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏好提取 线性探针 文本评估 常识推理 领域泛化 模型偏见
📋 核心要点
- 现有LLM作为评估者易受偏见影响,降低了评估文本质量和常识推理的准确性。
- 利用线性分类探针,通过对比提示对之间的差异,直接提取LLM的潜在知识和偏好。
- 实验表明,该方法在多个数据集和模型上优于传统方法,且具有良好的泛化能力和计算效率。
📝 摘要(中文)
大型语言模型(LLMs)常被用作自动评估文本的工具,但其有效性可能受到各种无意偏见的影响。本文提出了一种利用线性分类探针的方法,通过对比提示对之间的差异来训练探针,直接访问LLMs的潜在知识,并提取更准确的偏好。通过对来自四个不同系列的、不同规模的模型以及六个评估文本质量和常识推理的多样化数据集进行的大量实验,我们证明了有监督和无监督的探针方法都始终优于传统的基于生成的方法,同时保持了相似的计算成本。这些探针在领域迁移下具有泛化能力,甚至可以优于使用相同训练数据量进行微调的评估器。我们的结果表明,线性探针为LLM作为评估者的任务提供了一种准确、稳健且计算高效的方法,同时为模型如何编码与判断相关的知识提供了可解释的见解。我们的数据和代码将在未来公开发布。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在作为自动评估者时,由于潜在偏见而导致的评估不准确问题。现有的基于生成的方法,依赖于LLM生成文本来判断质量或进行推理,容易受到模型自身固有的偏见和噪声的影响,导致评估结果不稳定且不可靠。
核心思路:论文的核心思路是通过训练线性分类探针,直接从LLM的内部表征中提取偏好信息。这种方法假设LLM在训练过程中已经学习到了相关的知识,只是这些知识以一种隐式的方式存储在模型的参数中。通过设计特定的提示对,并利用它们在LLM内部激活的差异,可以训练探针来区分不同的偏好,从而绕过生成过程中的噪声和偏见。
技术框架:整体框架包括以下几个主要步骤:1) 设计对比提示对,用于区分不同的偏好或质量等级。2) 将提示对输入到LLM中,提取LLM内部特定层的激活向量。3) 使用提取的激活向量训练线性分类探针,目标是区分提示对所代表的不同类别。4) 使用训练好的探针来评估新的文本或进行推理,通过分析LLM对新文本的激活向量,并利用探针进行分类,得到评估结果。
关键创新:最重要的技术创新点在于利用线性分类探针直接访问LLM的潜在知识,而不是依赖于生成文本。与现有方法相比,这种方法更加直接、高效,并且可以减少偏见的影响。此外,论文还提出了使用对比提示对来训练探针的方法,这种方法可以有效地利用LLM内部的知识,并提高探针的准确性。
关键设计:关键设计包括:1) 提示对的设计,需要精心选择提示,以确保它们能够有效地激活LLM内部与偏好相关的知识。2) 激活向量的提取层选择,不同的层可能包含不同类型的知识,需要根据具体任务选择合适的层。3) 探针的训练方法,可以使用有监督或无监督的方法,根据具体情况选择。4) 损失函数的设计,需要选择合适的损失函数来优化探针的性能。
🖼️ 关键图片

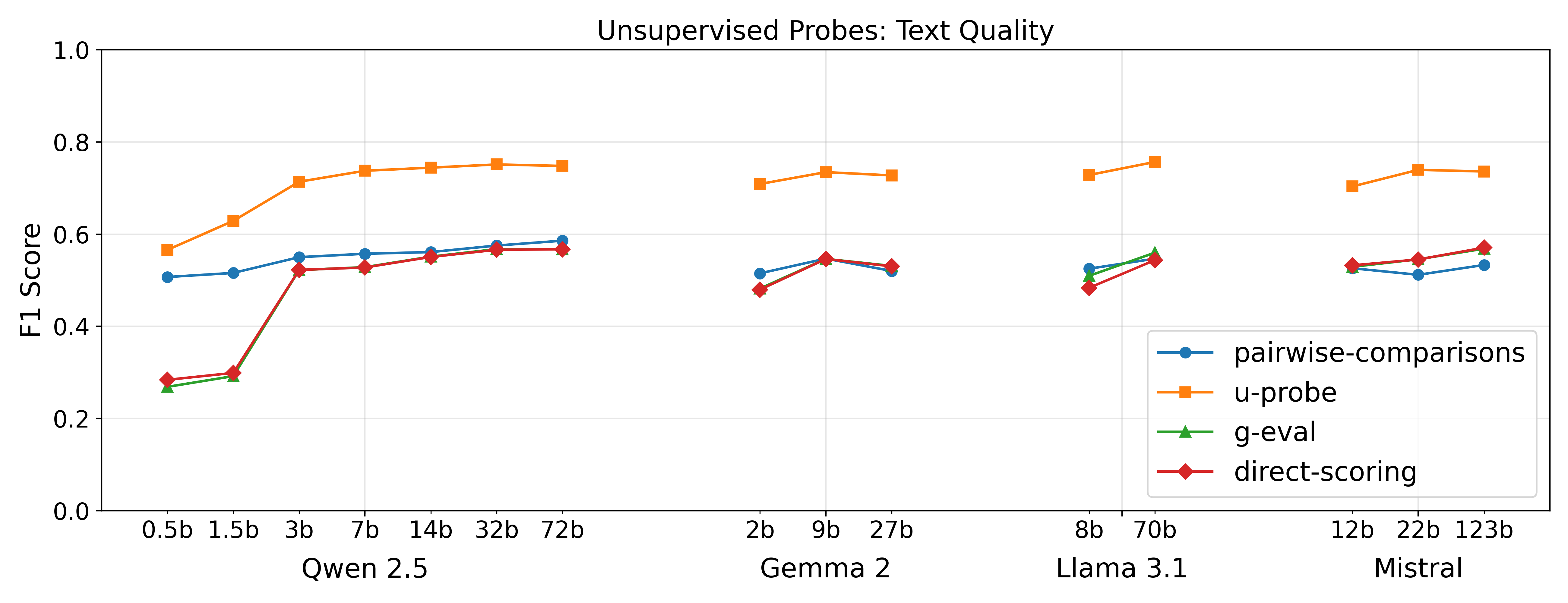

📊 实验亮点
实验结果表明,该方法在多个数据集和模型上都优于传统的基于生成的方法。例如,在文本质量评估任务中,该方法可以达到与微调模型相当甚至更好的性能,同时保持了较低的计算成本。此外,该方法还具有良好的泛化能力,可以在不同的领域和模型之间进行迁移。
🎯 应用场景
该研究成果可广泛应用于文本质量评估、常识推理、对话系统等领域。通过更准确地提取LLM的偏好,可以提升自动化评估的可靠性,减少人工干预,并为LLM的公平性和可解释性研究提供新的思路。未来,该方法有望应用于更复杂的决策场景,例如自动驾驶、医疗诊断等。
📄 摘要(原文)
Large Language Models (LLMs) are often used as automated judges to evaluate text, but their effectiveness can be hindered by various unintentional biases. We propose using linear classifying probes, trained by leveraging differences between contrasting pairs of prompts, to directly access LLMs' latent knowledge and extract more accurate preferences. Through extensive experiments using models of varying size from four different families and six diverse datasets assessing text quality evaluation and common sense reasoning, we demonstrate that both supervised and unsupervised probing approaches consistently outperform traditional generation-based judgement while maintaining similar computational costs. These probes generalise under domain shifts and can even outperform finetuned evaluators with the same training data size. Our results suggest linear probing offers an accurate, robust and computationally efficient approach for LLM-as-judge tasks while providing interpretable insights into how models encode judgement-relevant knowledge. Our data and code will be openly released in the future.