Bayesian Teaching Enables Probabilistic Reasoning in Large Language Models
作者: Linlu Qiu, Fei Sha, Kelsey Allen, Yoon Kim, Tal Linzen, Sjoerd van Steenkiste
分类: cs.CL, cs.AI
发布日期: 2025-03-21 (更新: 2026-01-15)
备注: Nature Communications
DOI: 10.1038/s41467-025-67998-6
💡 一句话要点
贝叶斯教学提升大语言模型中的概率推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 贝叶斯推理 概率推理 贝叶斯教学 信念更新
📋 核心要点
- 现有大语言模型在概率推理方面表现不足,无法有效更新信念。
- 通过贝叶斯教学,使LLM模仿规范贝叶斯模型的预测,提升信念更新能力。
- 实验表明,该方法显著提高了LLM的概率推理能力,并能泛化到新任务。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被用作与用户和世界互动的智能体。为了成功地做到这一点,LLM必须构建世界的表征并形成关于它们的概率信念。例如,为了提供个性化的推荐,LLM需要从用户在多次互动中的行为推断其偏好。贝叶斯推理框架阐述了智能体在接收到新信息时更新其信念的最佳方式。我们首先表明,LLM远远达不到贝叶斯框架所定义的标准。然后,我们表明,通过教导LLM模仿规范贝叶斯模型的预测,我们可以显著提高它们更新信念的能力;这种能力可以推广到新的任务。我们得出结论,LLM可以有效地从例子中学习推理技能,并将这些技能推广到新的领域。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在概率推理方面的不足。具体来说,LLM在根据新信息更新其信念方面表现不佳,无法达到贝叶斯推理框架所定义的标准。现有方法难以使LLM有效地进行概率推理,限制了其在需要进行信念更新的任务中的应用,例如个性化推荐等。
核心思路:论文的核心思路是利用贝叶斯教学,即通过教导LLM模仿规范贝叶斯模型的预测,来提高其概率推理能力。这种方法的关键在于,规范贝叶斯模型代表了理想的信念更新方式,通过让LLM学习模仿这种理想模型,可以使其更好地进行概率推理。
技术框架:论文的技术框架主要包括以下几个步骤:1)首先,评估LLM在概率推理方面的表现,发现其与贝叶斯框架的差距。2)然后,构建一个规范贝叶斯模型,作为LLM学习的目标。3)接着,使用贝叶斯模型生成的数据来训练LLM,使其学习模仿贝叶斯模型的预测。4)最后,评估训练后的LLM在新的任务中的表现,验证其泛化能力。
关键创新:论文最重要的技术创新点在于将贝叶斯教学应用于LLM,以提高其概率推理能力。与传统的训练方法不同,该方法不是直接训练LLM完成特定任务,而是让其学习模仿一个理想的概率推理模型。这种方法可以使LLM更好地理解概率推理的本质,从而提高其泛化能力。
关键设计:论文的关键设计包括:1)选择合适的规范贝叶斯模型,使其能够代表理想的信念更新方式。2)设计有效的训练方法,使LLM能够从贝叶斯模型生成的数据中学习。3)选择合适的评估指标,以全面评估LLM在概率推理方面的表现。具体的参数设置、损失函数、网络结构等技术细节在论文中可能有所描述,但此处无法详细展开。
🖼️ 关键图片
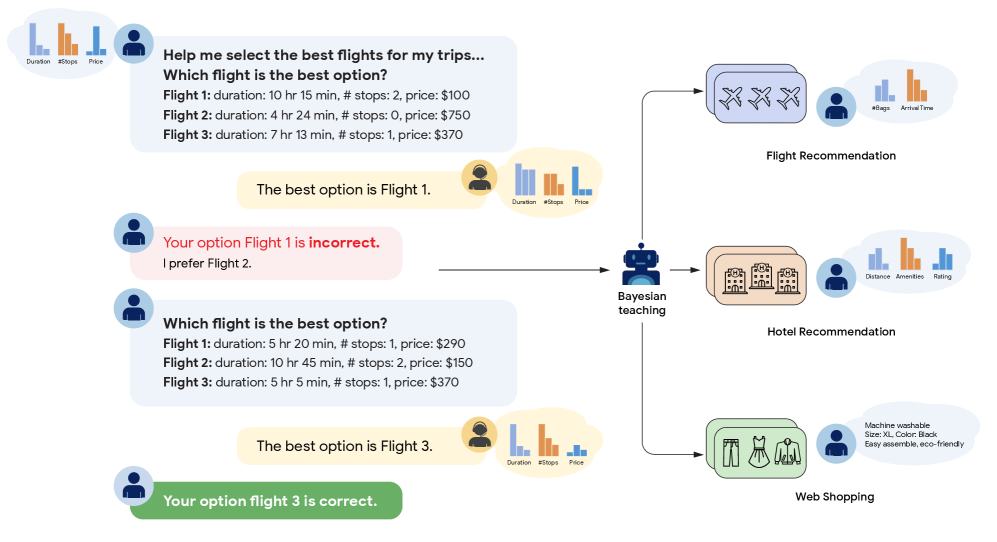
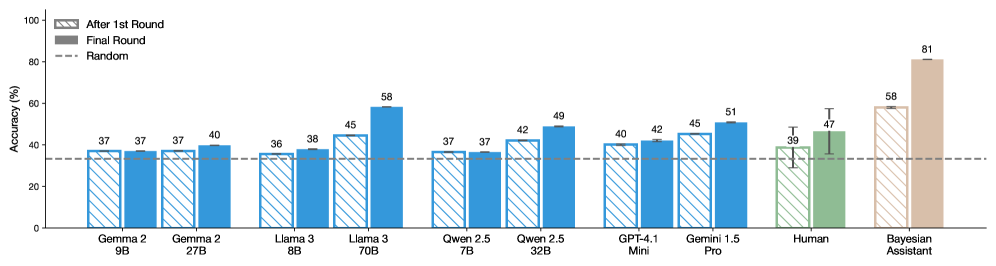
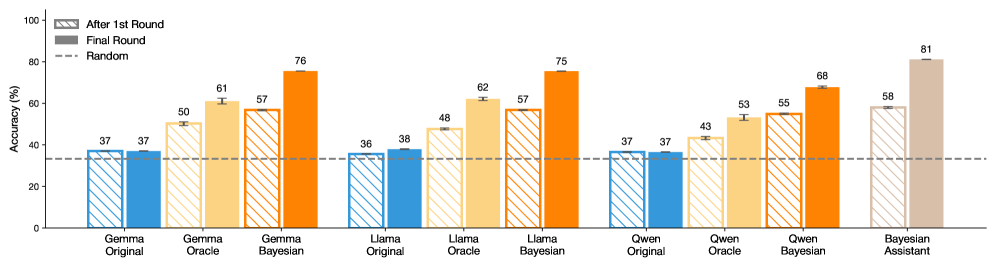
📊 实验亮点
论文实验结果表明,通过贝叶斯教学,LLM的概率推理能力得到了显著提升。具体来说,训练后的LLM在信念更新任务中的表现更接近规范贝叶斯模型,并且能够泛化到新的任务中。这些结果表明,LLM可以有效地从例子中学习推理技能,并将这些技能推广到新的领域。
🎯 应用场景
该研究成果可应用于各种需要概率推理的场景,如个性化推荐系统、风险评估、医疗诊断等。通过提升LLM的概率推理能力,可以使其更好地理解用户需求、预测未来事件,并做出更明智的决策。未来,该方法有望被应用于更复杂的推理任务,推动人工智能技术的发展。
📄 摘要(原文)
Large language models (LLMs) are increasingly used as agents that interact with users and with the world. To do so successfully, LLMs must construct representations of the world and form probabilistic beliefs about them. To provide personalized recommendations, for example, the LLM needs to infer a user's preferences from their behavior over multiple interactions. The Bayesian inference framework lays out the optimal way for an agent to update its beliefs as it receives new information. We first show that LLMs fall far short of the standard defined by the Bayesian framework. We then show that by teaching LLMs to mimic the predictions of the normative Bayesian model, we can dramatically improve their ability to update their beliefs; this ability generalizes to new tasks. We conclude that LLMs can effectively learn reasoning skills from examples and generalize those skills to new domains.