CASE -- Condition-Aware Sentence Embeddings for Conditional Semantic Textual Similarity Measurement
作者: Gaifan Zhang, Yi Zhou, Danushka Bollegala
分类: cs.CL
发布日期: 2025-03-21 (更新: 2026-01-23)
备注: Accepted to EACL2026
💡 一句话要点
提出CASE模型,利用条件感知句子嵌入提升条件语义文本相似度计算。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 条件语义文本相似度 句子嵌入 大型语言模型 条件感知 有监督降维
📋 核心要点
- 现有句子嵌入方法难以有效捕捉上下文信息,导致条件语义文本相似度计算精度不足。
- CASE模型通过条件感知机制,利用大型语言模型生成条件嵌入,并结合有监督的非线性投影进行降维。
- 实验表明,CASE在C-STS任务上显著优于现有方法,且减去条件嵌入和有监督降维均能提升性能。
📝 摘要(中文)
本文提出了一种条件感知句子嵌入(CASE)方法,旨在解决在给定上下文条件下如何更好地修改句子嵌入的问题,以提升条件语义文本相似度(C-STS)的计算。CASE首先利用大型语言模型(LLM)为条件生成嵌入,其中句子影响条件中token的注意力得分。然后,学习一个有监督的非线性投影来降低基于LLM的文本嵌入的维度。实验结果表明,CASE在现有的标准基准数据集上显著优于先前的C-STS方法。研究发现,减去条件嵌入能够持续提升基于LLM的文本嵌入的C-STS性能。此外,论文还提出了一种有监督的降维方法,该方法不仅降低了LLM嵌入的维度,还显著提高了它们的性能。
🔬 方法详解
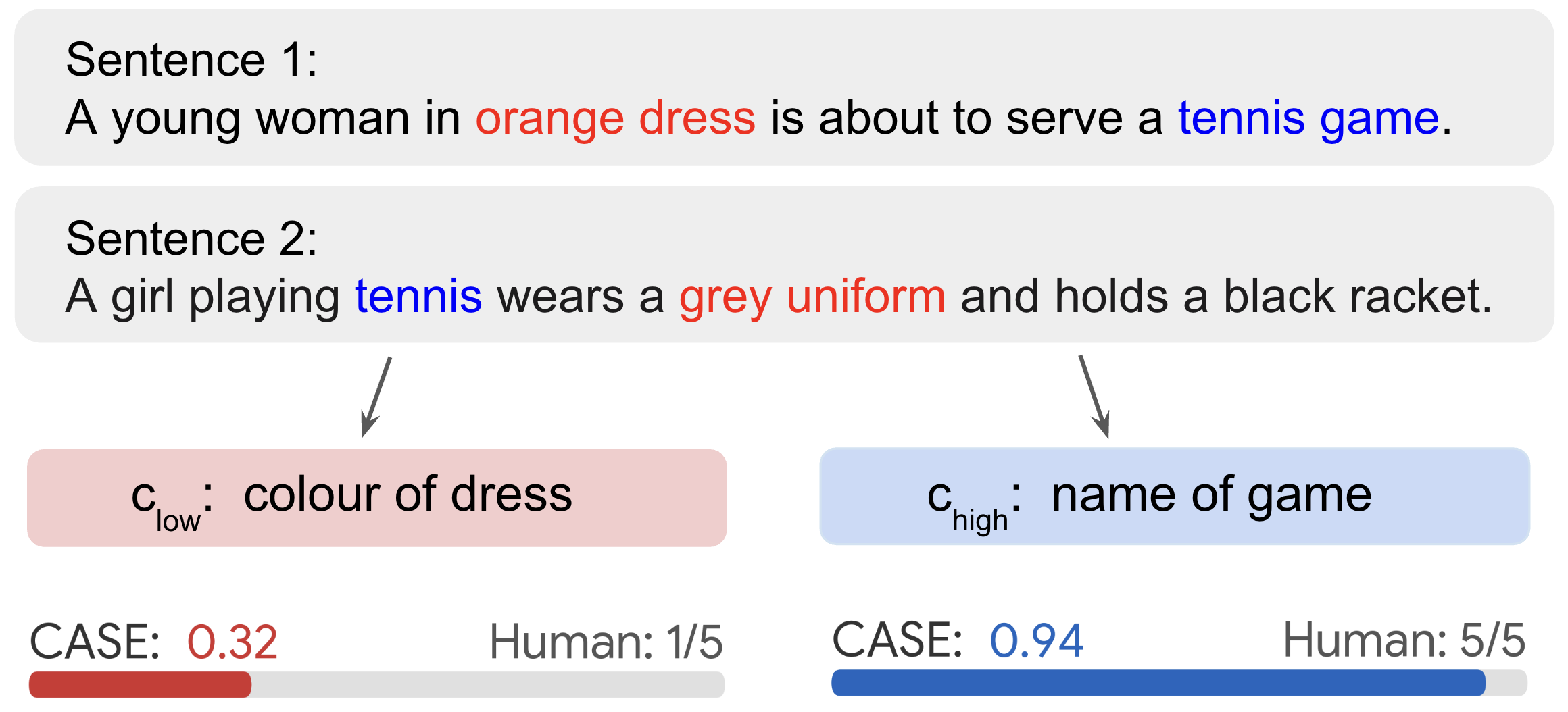
问题定义:论文旨在解决条件语义文本相似度(C-STS)计算问题。现有方法无法充分利用上下文信息,导致句子嵌入在不同语境下的表示能力不足,进而影响C-STS的准确性。现有方法的痛点在于如何有效地将条件信息融入到句子嵌入中。
核心思路:论文的核心思路是构建条件感知的句子嵌入。具体来说,首先利用大型语言模型(LLM)对条件进行编码,生成条件嵌入。然后,通过一个有监督的非线性投影,将LLM生成的文本嵌入进行降维,同时学习如何更好地融合条件信息。
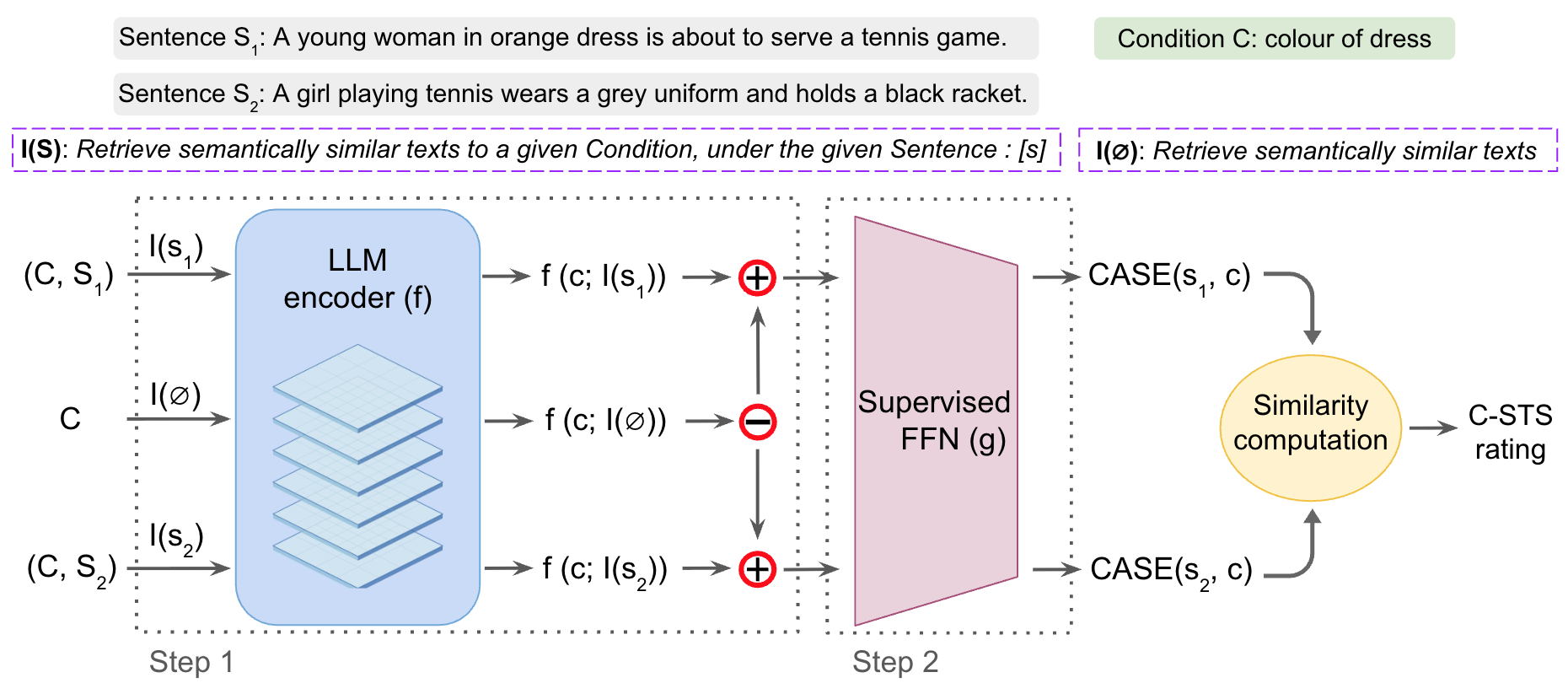
技术框架:CASE模型主要包含两个阶段:1) 条件嵌入生成阶段:利用LLM(如BERT)对条件文本进行编码,句子信息影响条件文本的注意力权重,从而生成条件嵌入;2) 句子嵌入调整阶段:利用有监督的非线性投影,对LLM生成的句子嵌入进行降维和调整,使其更好地适应条件信息。整体流程是先生成条件嵌入,再利用条件嵌入调整句子嵌入,最后计算相似度。
关键创新:论文的关键创新在于条件感知机制和有监督降维方法。条件感知机制允许句子信息影响条件嵌入的生成,从而更好地捕捉上下文信息。有监督降维方法不仅降低了LLM嵌入的维度,还通过学习,提升了嵌入的性能。与现有方法相比,CASE能够更有效地融合条件信息,从而提升C-STS的准确性。
关键设计:在条件嵌入生成阶段,使用Transformer结构的LLM,并使用句子嵌入来影响条件文本的注意力权重。在有监督降维阶段,使用多层感知机(MLP)作为非线性投影函数,并使用C-STS的相似度标签作为监督信号。损失函数包括相似度预测损失和降维损失。具体参数设置(如LLM的选择、MLP的层数和激活函数等)未知,需要在实验中进行调整。
🖼️ 关键图片
📊 实验亮点
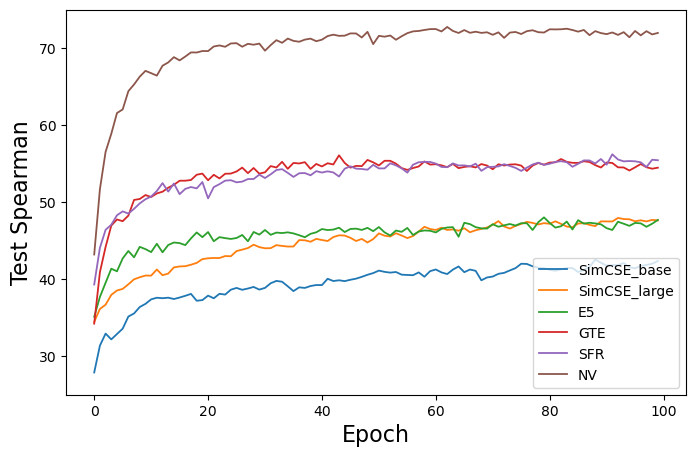
实验结果表明,CASE模型在C-STS任务上显著优于现有方法。具体来说,CASE在标准基准数据集上取得了最高的性能,并且减去条件嵌入和使用有监督降维方法均能带来性能提升。具体提升幅度未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于对话系统、信息检索、文本摘要等领域。例如,在对话系统中,可以根据对话历史(条件)更好地理解当前句子的含义,从而生成更合适的回复。在信息检索中,可以根据用户的搜索意图(条件)更准确地匹配相关文档。未来,该方法可以扩展到其他自然语言处理任务中,例如机器翻译和文本生成。
📄 摘要(原文)
The meaning conveyed by a sentence often depends on the context in which it appears. Despite the progress of sentence embedding methods, it remains unclear how to best modify a sentence embedding conditioned on its context. To address this problem, we propose Condition-Aware Sentence Embeddings (CASE), an efficient and accurate method to create an embedding for a sentence under a given condition. First, CASE creates an embedding for the condition using a Large Language Model (LLM), where the sentence influences the attention scores computed for the tokens in the condition during pooling. Next, a supervised nonlinear projection is learned to reduce the dimensionality of the LLM-based text embeddings. We show that CASE significantly outperforms previously proposed Conditional Semantic Textual Similarity (C-STS) methods on an existing standard benchmark dataset. We find that subtracting the condition embedding consistently improves the C-STS performance of LLM-based text embeddings. Moreover, we propose a supervised dimensionality reduction method that not only reduces the dimensionality of LLM-based embeddings but also significantly improves their performance.