SafeMERGE: Preserving Safety Alignment in Fine-Tuned Large Language Models via Selective Layer-Wise Model Merging
作者: Aladin Djuhera, Swanand Ravindra Kadhe, Farhan Ahmed, Syed Zawad, Holger Boche
分类: cs.CL, cs.AI
发布日期: 2025-03-21 (更新: 2025-10-27)
期刊: ICLR 2025 Workshop on Building Trust in Language Models and Applications
💡 一句话要点
SafeMERGE:通过选择性分层模型融合,在微调大语言模型中保持安全性对齐
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 安全性对齐 模型微调 模型融合 选择性融合
📋 核心要点
- 微调LLM虽能提升特定任务性能,但可能导致模型安全性下降,对有害提示产生不良响应。
- SafeMERGE通过选择性融合微调模型和安全对齐模型的层,在保持任务性能的同时恢复安全性。
- 实验表明,SafeMERGE能有效减少有害输出,且对模型效用影响甚微,甚至可能有所提升。
📝 摘要(中文)
微调大型语言模型(LLM)是将通用模型适配到特定领域的常用方法。然而,最近的研究表明,微调可能会削弱安全性对齐,导致LLM对有害或不道德的提示做出响应。虽然已经提出了许多重新对齐安全性的方法,但它们通常引入难以实施的自定义算法或损害任务效用。本文提出了SafeMERGE,一个轻量级的后微调框架,通过余弦相似性准则来衡量模型行为与安全行为的偏差,并仅在偏差出现时才选择性地将微调模型层与安全对齐模型层融合,从而在保持下游性能的同时维护安全性。在三个LLM和两个任务上的实验表明,与其他防御方法相比,SafeMERGE始终能减少有害输出,并且对效用的影响可忽略不计,甚至可能产生积极影响。我们的结果表明,选择性分层融合为防止微调过程中意外丢失安全性提供了一种有效的保障,使SafeMERGE成为一种简单的后微调防御方法。
🔬 方法详解
问题定义:论文旨在解决微调大型语言模型时,模型安全性对齐被破坏的问题。现有方法通常需要复杂的自定义算法,实施困难,或者会损害模型的任务效用,无法在安全性和性能之间取得平衡。
核心思路:SafeMERGE的核心思路是选择性地融合微调后的模型和安全对齐的模型。只有当微调后的模型层偏离安全行为时,才将其与安全对齐的模型层融合。这种方法旨在保留微调带来的性能提升,同时恢复模型的安全性。
技术框架:SafeMERGE是一个后微调框架,包含以下步骤:1. 使用特定任务的数据集微调LLM。2. 评估微调后模型在安全方面的表现。3. 对于偏离安全行为的层,计算微调后模型层和安全对齐模型层之间的余弦相似度。4. 基于余弦相似度,选择性地将微调后的模型层与安全对齐的模型层融合。
关键创新:SafeMERGE的关键创新在于其选择性融合机制。与传统的模型融合方法不同,SafeMERGE不是简单地将整个模型融合,而是根据每一层的安全表现,有选择性地进行融合。这种方法能够更精确地控制模型的安全性和性能之间的平衡。
关键设计:SafeMERGE的关键设计包括:1. 使用余弦相似度作为衡量模型层安全性的指标。2. 设置一个阈值,只有当余弦相似度低于该阈值时,才进行模型层融合。3. 融合比例可以根据具体情况进行调整,以达到最佳的安全性和性能平衡。
🖼️ 关键图片

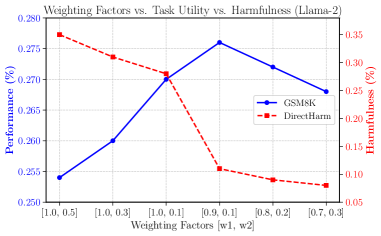

📊 实验亮点
实验结果表明,SafeMERGE在三个不同的LLM和两个不同的任务上,都能够有效地减少有害输出。与其他防御方法相比,SafeMERGE在降低有害输出的同时,对模型效用的影响可忽略不计,甚至可能带来积极的提升。这证明了SafeMERGE是一种简单而有效的后微调安全防御方法。
🎯 应用场景
SafeMERGE可应用于各种需要微调LLM的场景,尤其是在安全性至关重要的领域,如医疗、金融和法律。它可以作为一种通用的后微调防御机制,防止模型在微调过程中意外丢失安全性,确保LLM在特定任务中既能表现出色,又能遵守伦理和安全准则。未来,该方法可以扩展到其他类型的模型和任务,并与其他安全防御技术相结合,构建更强大的安全保障体系。
📄 摘要(原文)
Fine-tuning large language models (LLMs) is a common practice to adapt generalist models to specialized domains. However, recent studies show that fine-tuning can erode safety alignment, causing LLMs to respond to harmful or unethical prompts. Many methods to realign safety have been proposed, but often introduce custom algorithms that are difficult to implement or compromise task utility. In this work, we propose SafeMERGE, a lightweight, post-fine-tuning framework that preserves safety while maintaining downstream performance. SafeMERGE selectively merges fine-tuned with safety-aligned model layers only when they deviate from safe behavior, measured by a cosine similarity criterion. Across three LLMs and two tasks, SafeMERGE consistently reduces harmful outputs compared to other defenses, with negligible or even positive impact on utility. Our results demonstrate that selective layer-wise merging offers an effective safeguard against the inadvertent loss of safety during fine-tuning, establishing SafeMERGE as a simple post-fine-tuning defense.