A Comprehensive Survey on Long Context Language Modeling
作者: Jiaheng Liu, Dawei Zhu, Zhiqi Bai, Yancheng He, Huanxuan Liao, Haoran Que, Zekun Wang, Chenchen Zhang, Ge Zhang, Jiebin Zhang, Yuanxing Zhang, Zhuo Chen, Hangyu Guo, Shilong Li, Ziqiang Liu, Yong Shan, Yifan Song, Jiayi Tian, Wenhao Wu, Zhejian Zhou, Ruijie Zhu, Junlan Feng, Yang Gao, Shizhu He, Zhoujun Li, Tianyu Liu, Fanyu Meng, Wenbo Su, Yingshui Tan, Zili Wang, Jian Yang, Wei Ye, Bo Zheng, Wangchunshu Zhou, Wenhao Huang, Sujian Li, Zhaoxiang Zhang
分类: cs.CL, cs.LG
发布日期: 2025-03-20 (更新: 2025-11-24)
🔗 代码/项目: GITHUB
💡 一句话要点
针对长文本处理难题,综述长上下文语言模型(LCLM)的最新进展与未来方向。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长上下文语言模型 大型语言模型 长文本处理 注意力机制 模型评估
📋 核心要点
- 现有NLP方法在处理长文本时面临效率和效果的挑战,无法充分利用长距离依赖关系。
- 本文系统性地梳理了长上下文语言模型(LCLM)的设计、训练、评估和应用,旨在提供全面的技术指导。
- 综述涵盖数据策略、模型架构、训练基础设施、评估方法等多个方面,并展望了LCLM的未来发展方向。
📝 摘要(中文)
本文全面综述了大型语言模型中长上下文建模的最新进展。随着长文档、对话和其他文本数据的日益增长,开发能够有效处理和分析大量输入的长上下文语言模型(LCLM)至关重要。本综述围绕三个关键方面展开:如何获得有效且高效的LCLM,如何高效地训练和部署LCLM,以及如何全面地评估和分析LCLM。对于第一个方面,我们讨论了面向长上下文处理的数据策略、架构设计和工作流程方法。对于第二个方面,我们详细考察了LCLM训练和推理所需的基础设施。对于第三个方面,我们介绍了长上下文理解和长文本生成的评估范式,以及LCLM的行为分析和机制可解释性。除了这三个关键方面,我们还深入探讨了现有LCLM已部署的各种应用场景,并概述了有希望的未来发展方向。本综述提供了关于长上下文LLM的最新文献回顾,我们希望它能成为研究人员和工程师的宝贵资源。
🔬 方法详解
问题定义:现有语言模型在处理长文本时,由于计算复杂度和信息衰减等问题,难以有效捕捉长距离依赖关系,导致性能下降。传统的Transformer模型在处理长序列时面临平方级别的计算复杂度,并且存在信息瓶颈,限制了模型对长上下文的理解和生成能力。
核心思路:本文的核心思路是对现有长上下文语言模型进行系统性的梳理和归纳,从数据、模型、训练和评估等多个维度分析其优缺点,并总结出一些通用的设计原则和最佳实践。通过对现有方法的分类和比较,为研究人员提供一个全面的参考框架,帮助他们更好地理解和应用长上下文建模技术。
技术框架:本文的综述框架主要包括三个方面:1) 如何获得有效且高效的LCLM,涉及数据策略、架构设计和工作流程方法;2) 如何高效地训练和部署LCLM,涉及训练和推理所需的基础设施;3) 如何全面地评估和分析LCLM,涉及长上下文理解和长文本生成的评估范式,以及行为分析和机制可解释性。此外,还探讨了LCLM的应用场景和未来发展方向。
关键创新:本文的创新之处在于其全面性和系统性。它不仅涵盖了长上下文建模的各个方面,还对现有方法进行了深入的分析和比较。此外,本文还提出了对LCLM未来发展方向的展望,为研究人员提供了新的思路和方向。
关键设计:本文主要关注现有LCLM的设计,包括数据增强策略(如上下文扩充、数据混合等)、模型架构设计(如稀疏注意力、线性注意力等)和训练策略(如梯度累积、混合精度训练等)。此外,本文还关注LCLM的评估方法,包括长上下文理解任务(如问答、摘要等)和长文本生成任务(如故事生成、对话生成等)。
🖼️ 关键图片

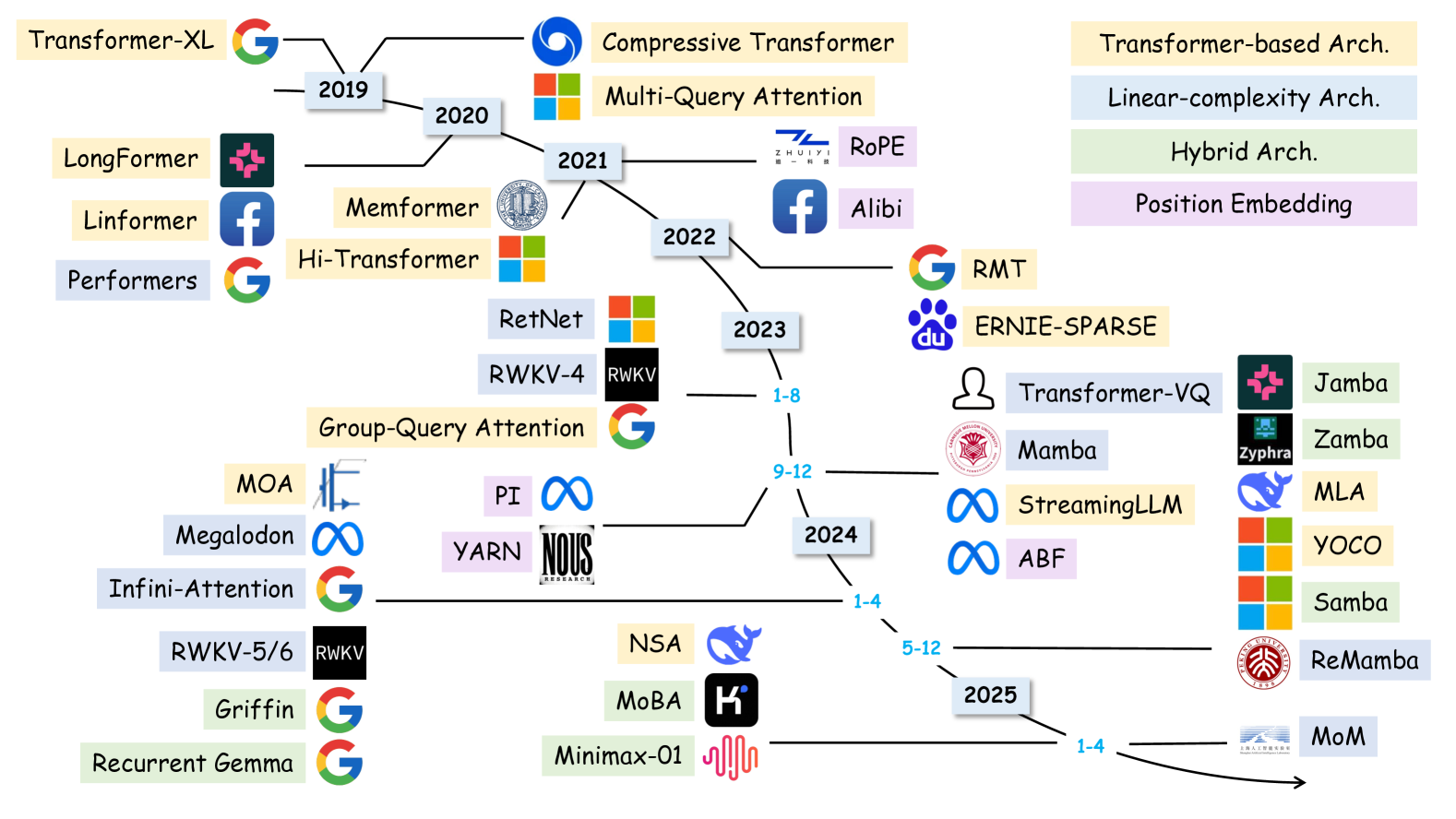
📊 实验亮点
本文对现有长上下文语言模型进行了全面的综述,涵盖了数据、模型、训练和评估等多个方面。通过对现有方法的分析和比较,总结出了一些通用的设计原则和最佳实践。此外,本文还提出了对LCLM未来发展方向的展望,为研究人员提供了新的思路和方向。
🎯 应用场景
长上下文语言模型在处理长篇文档、对话系统、代码生成、知识库问答等领域具有广泛的应用前景。能够更好地理解和生成长文本,提升相关任务的性能和用户体验。未来,LCLM有望在医疗、金融、法律等领域发挥更大的作用。
📄 摘要(原文)
Efficient processing of long contexts has been a persistent pursuit in Natural Language Processing. With the growing number of long documents, dialogues, and other textual data, it is important to develop Long Context Language Models (LCLMs) that can process and analyze extensive inputs in an effective and efficient way. In this paper, we present a comprehensive survey on recent advances in long-context modeling for large language models. Our survey is structured around three key aspects: how to obtain effective and efficient LCLMs, how to train and deploy LCLMs efficiently, and how to evaluate and analyze LCLMs comprehensively. For the first aspect, we discuss data strategies, architectural designs, and workflow approaches oriented with long context processing. For the second aspect, we provide a detailed examination of the infrastructure required for LCLM training and inference. For the third aspect, we present evaluation paradigms for long-context comprehension and long-form generation, as well as behavioral analysis and mechanism interpretability of LCLMs. Beyond these three key aspects, we thoroughly explore the diverse application scenarios where existing LCLMs have been deployed and outline promising future development directions. This survey provides an up-to-date review of the literature on long-context LLMs, which we wish to serve as a valuable resource for both researchers and engineers. An associated GitHub repository collecting the latest papers and repos is available at: \href{https://github.com/LCLM-Horizon/A-Comprehensive-Survey-For-Long-Context-Language-Modeling}{\color[RGB]{175,36,67}{LCLM-Horizon}}.