WaveFM: A High-Fidelity and Efficient Vocoder Based on Flow Matching
作者: Tianze Luo, Xingchen Miao, Wenbo Duan
分类: cs.SD, cs.CL, eess.AS
发布日期: 2025-03-20
备注: Accepted to the main conference of NAACL 2025. The codes are available at https://github.com/luotianze666/WaveFM
💡 一句话要点
WaveFM:一种基于流匹配的高保真高效声码器,用于mel谱条件下的语音合成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 流匹配 扩散模型 声码器 语音合成 一致性蒸馏
📋 核心要点
- 现有扩散声码器直接应用流匹配方法时,音频质量不佳,存在提升空间。
- WaveFM通过mel谱条件先验分布和辅助损失函数,优化流匹配过程,提升音频质量。
- WaveFM采用定制的一致性蒸馏方法加速推理,在保证质量的前提下实现单步波形生成。
📝 摘要(中文)
本文提出WaveFM,一种重参数化的流匹配模型,用于mel谱图条件下的语音合成,旨在提高扩散声码器的采样质量和生成速度。WaveFM采用mel谱图条件下的先验分布,而非标准高斯先验,以最小化合成过程中的不必要传输成本,因为mel谱图代表了波形的能量分布。此外,除了单一损失函数外,本文还引入了辅助损失,包括改进的多分辨率STFT损失,以进一步提高音频质量。为了在不显著降低采样质量的情况下加速推理,本文为WaveFM定制了一种一致性蒸馏方法。实验结果表明,与之前的扩散声码器相比,该模型在质量和效率方面都取得了优异的性能,并能够以单步推理生成波形。
🔬 方法详解
问题定义:论文旨在解决mel谱图条件下的语音合成任务中,现有扩散声码器质量和效率难以兼顾的问题。直接应用流匹配方法训练的声码器,音频质量有待提高。同时,扩散模型推理速度慢,难以满足实时性要求。
核心思路:论文的核心思路是通过优化流匹配过程,并结合一致性蒸馏技术,在保证音频质量的前提下,提升生成速度。具体而言,利用mel谱图的特性,设计mel条件先验分布,减少不必要的传输成本。同时,引入辅助损失函数,进一步提升音频质量。最后,通过一致性蒸馏,将扩散模型的知识迁移到单步模型,加速推理。
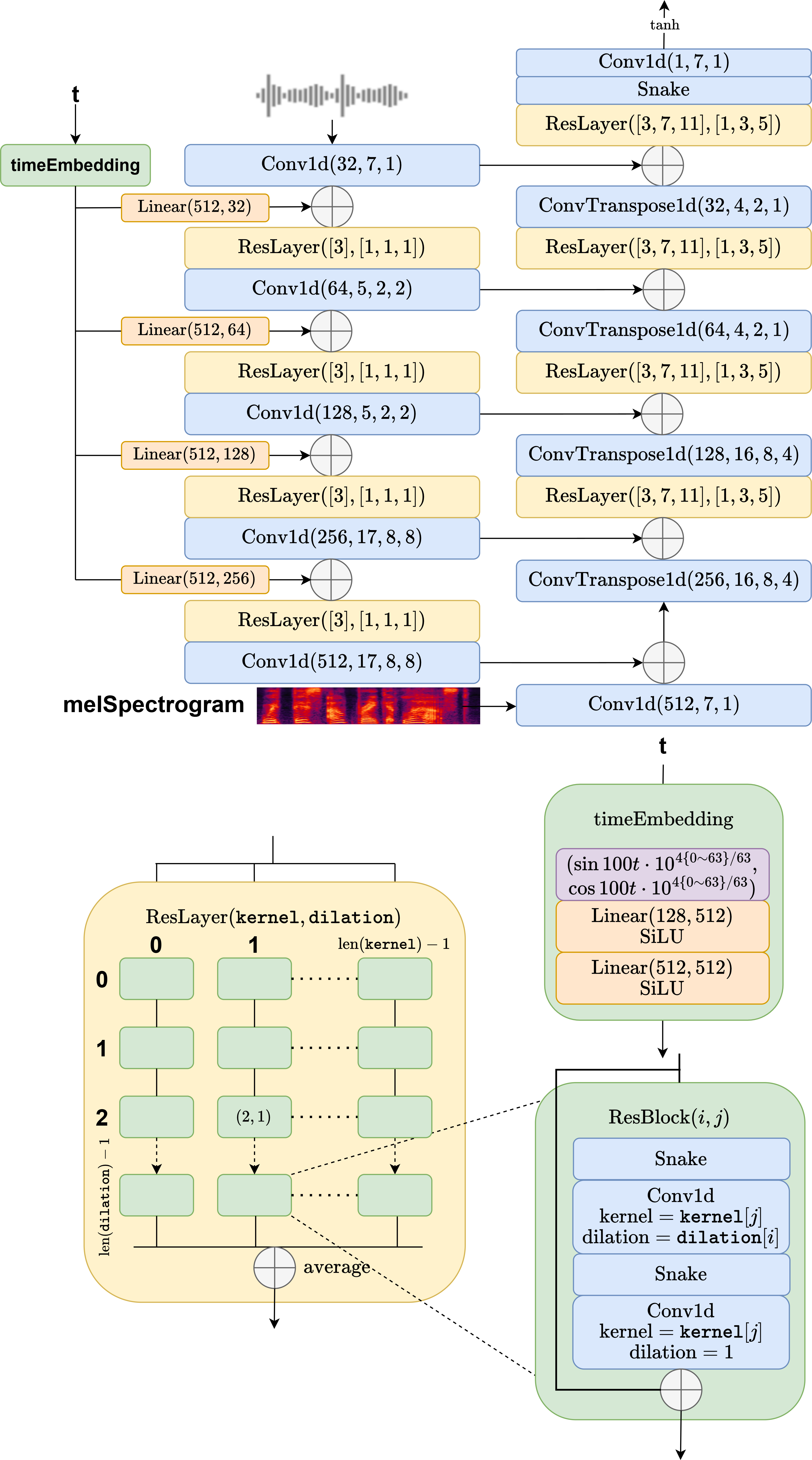
技术框架:WaveFM的整体框架包括以下几个主要模块:1) Mel谱图编码器:将mel谱图转换为特征表示。2) 流匹配模型:基于mel谱图特征,学习从先验分布到目标分布的映射。3) 辅助损失计算模块:计算多分辨率STFT损失等辅助损失。4) 一致性蒸馏模块:将扩散模型的知识蒸馏到单步模型。整个流程是:首先,mel谱图通过编码器得到特征表示,然后输入到流匹配模型中,生成波形。同时,计算辅助损失,优化模型参数。最后,通过一致性蒸馏,得到单步推理模型。
关键创新:论文的关键创新点在于:1) 提出了mel条件先验分布,更符合语音合成任务的特点,减少了不必要的计算。2) 引入了辅助损失函数,进一步提升了音频质量。3) 设计了定制的一致性蒸馏方法,在保证质量的前提下,实现了单步推理。与现有方法的本质区别在于,WaveFM更加注重利用mel谱图的特性来优化流匹配过程,并结合一致性蒸馏技术来加速推理。
关键设计:在mel条件先验分布方面,论文采用了基于mel谱图的条件高斯分布。在辅助损失函数方面,论文采用了多分辨率STFT损失,并对损失函数进行了改进。在一致性蒸馏方面,论文采用了基于教师-学生模型的蒸馏方法,并设计了特定的蒸馏目标。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片
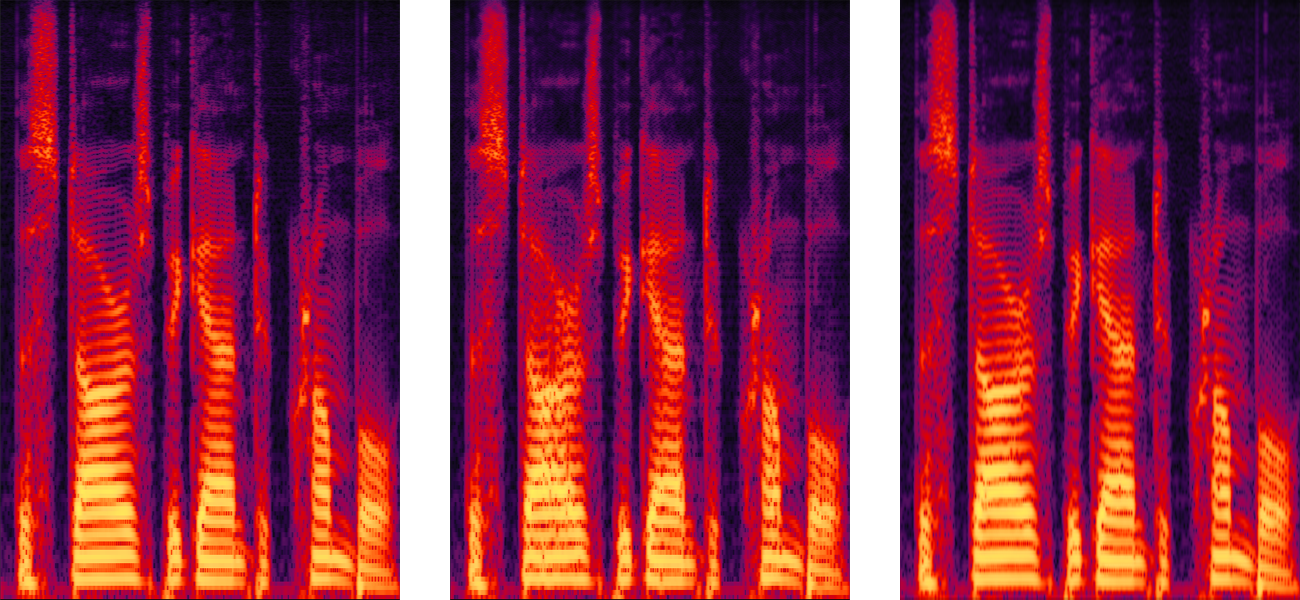
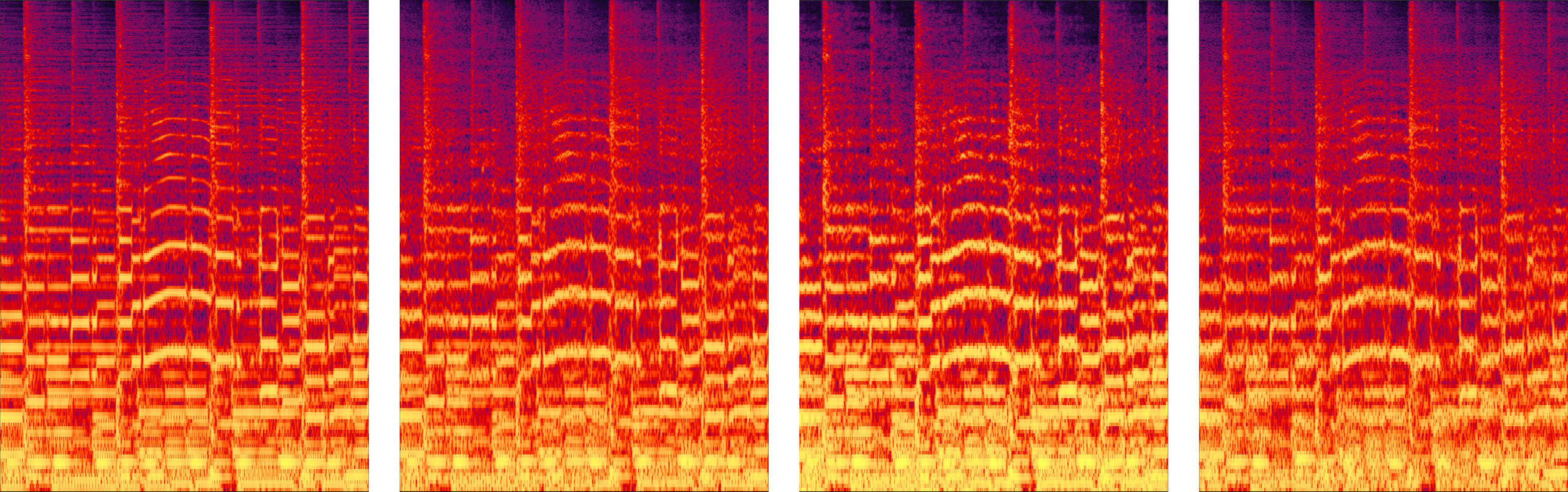
📊 实验亮点
实验结果表明,WaveFM在语音合成质量和效率方面均优于现有扩散声码器。在主观听觉测试中,WaveFM的MOS得分显著高于其他基线模型。同时,WaveFM通过一致性蒸馏,实现了单步推理,大大提高了生成速度。具体性能数据在论文中有详细展示。
🎯 应用场景
WaveFM具有广泛的应用前景,包括语音合成、语音转换、语音增强等领域。它可以用于生成高质量的语音,提升语音交互体验。此外,WaveFM的高效性使其可以应用于实时语音合成场景,例如智能助手、语音游戏等。未来,WaveFM可以进一步扩展到其他音频生成任务,例如音乐生成、音效生成等。
📄 摘要(原文)
Flow matching offers a robust and stable approach to training diffusion models. However, directly applying flow matching to neural vocoders can result in subpar audio quality. In this work, we present WaveFM, a reparameterized flow matching model for mel-spectrogram conditioned speech synthesis, designed to enhance both sample quality and generation speed for diffusion vocoders. Since mel-spectrograms represent the energy distribution of waveforms, WaveFM adopts a mel-conditioned prior distribution instead of a standard Gaussian prior to minimize unnecessary transportation costs during synthesis. Moreover, while most diffusion vocoders rely on a single loss function, we argue that incorporating auxiliary losses, including a refined multi-resolution STFT loss, can further improve audio quality. To speed up inference without degrading sample quality significantly, we introduce a tailored consistency distillation method for WaveFM. Experiment results demonstrate that our model achieves superior performance in both quality and efficiency compared to previous diffusion vocoders, while enabling waveform generation in a single inference step.