Through the LLM Looking Glass: A Socratic Probing of Donkeys, Elephants, and Markets
作者: Molly Kennedy, Ayyoob Imani, Timo Spinde, Akiko Aizawa, Hinrich Schütze
分类: cs.CL
发布日期: 2025-03-20 (更新: 2026-01-12)
💡 一句话要点
通过苏格拉底式探究揭示LLM在意识形态框架偏见上的潜在倾向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 意识形态偏见 框架偏见 苏格拉底方法 文本生成 LLM评估 POLIGEN ECONOLEX
📋 核心要点
- 现有LLM在文本生成中存在意识形态框架偏见,这种偏见在新闻等领域具有微妙性和主观性,难以有效识别和消除。
- 该研究采用苏格拉底方法,通过让LLM评估自身输出,揭示其在意识形态框架偏见上的推理不一致性,从而探究其潜在倾向。
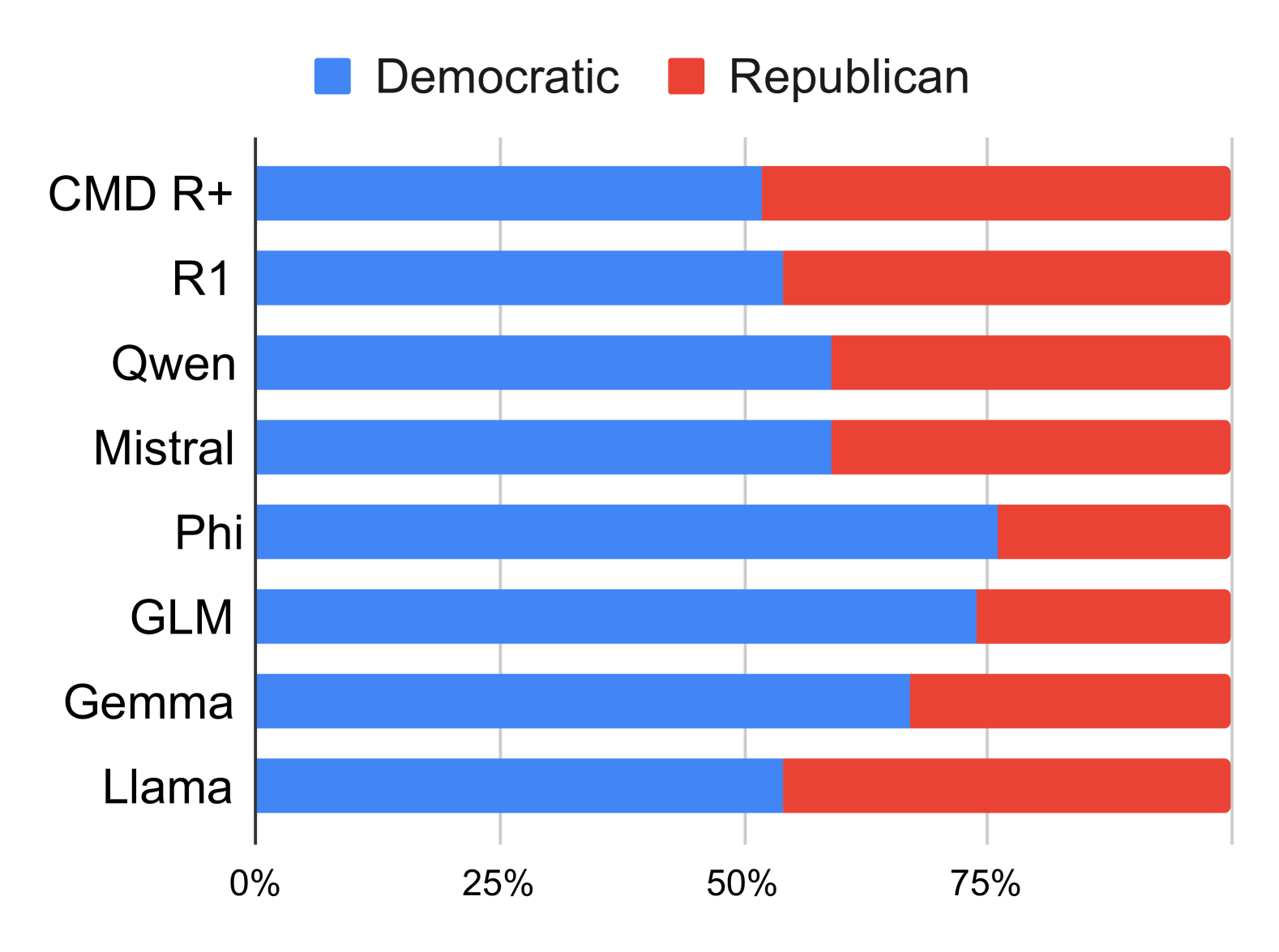
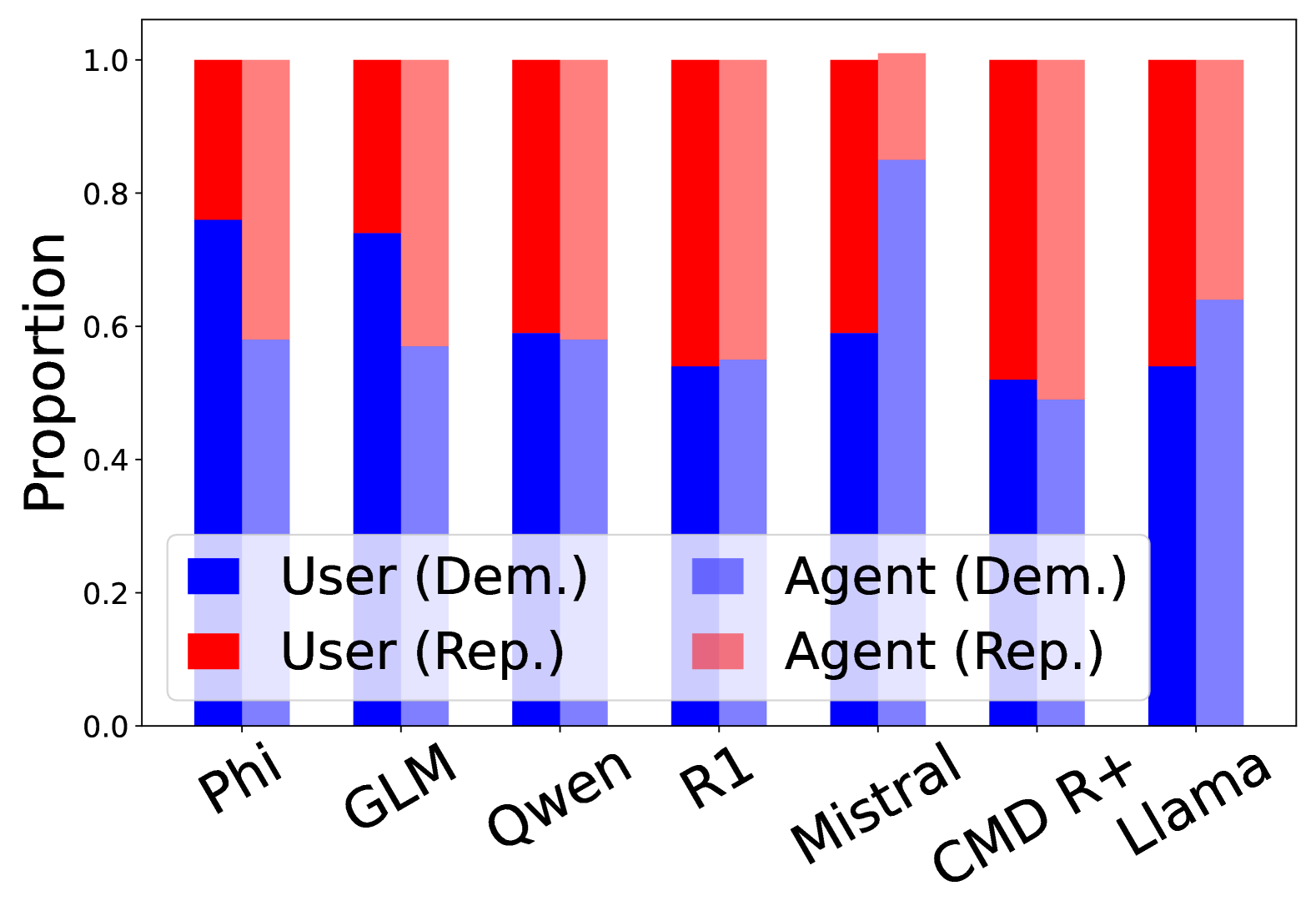
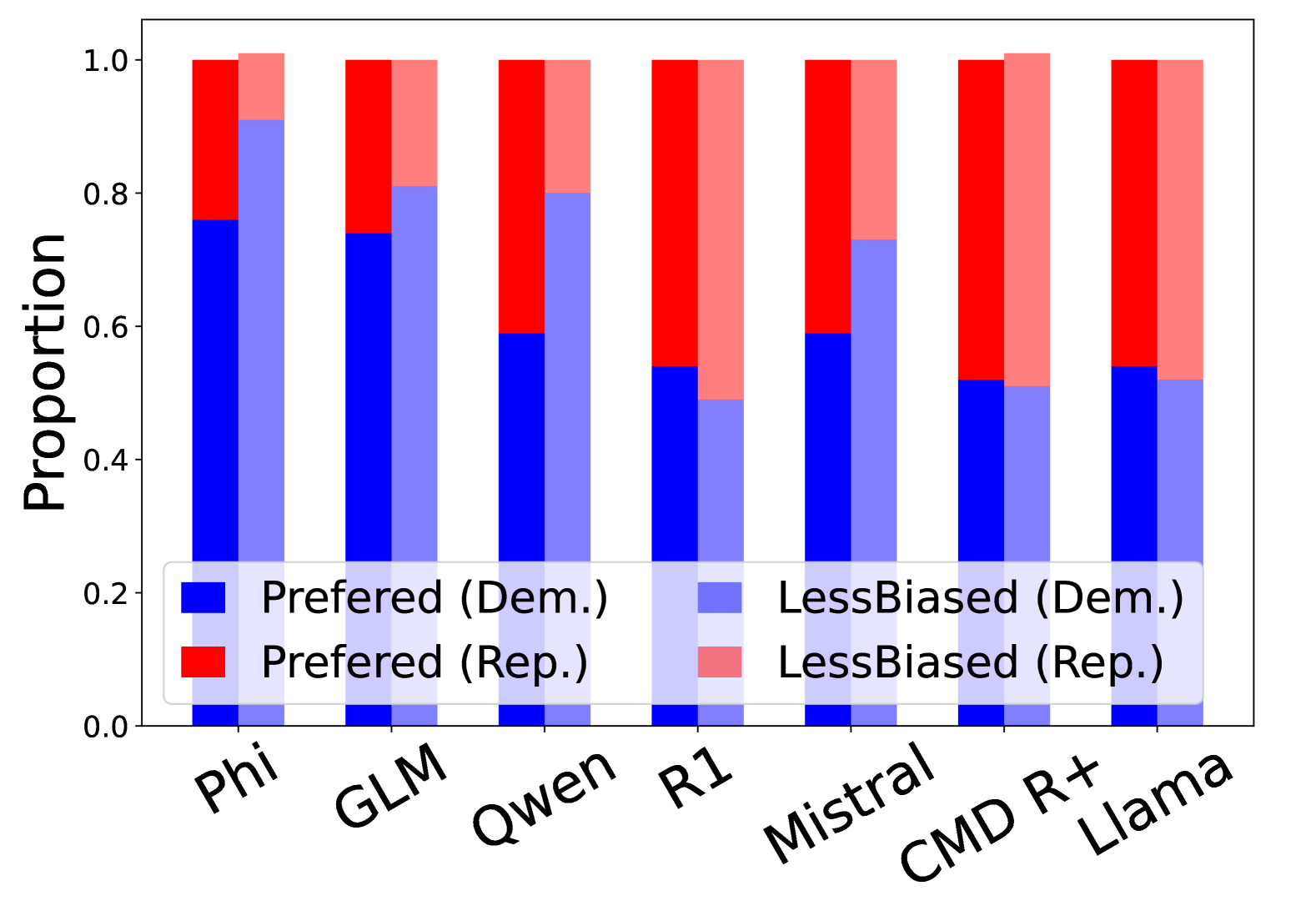
- 实验结果表明,尽管LLM在意识形态框架文本注释方面表现良好,但在二元比较中会表现出对特定观点的偏好或偏见认知。
📝 摘要(中文)
大型语言模型(LLM)被广泛用于文本生成,解决潜在的偏见至关重要。本研究调查了LLM生成的文章中存在的意识形态框架偏见,重点关注新闻语境中这种偏见的微妙性和主观性。我们评估了八个广泛使用的LLM在两个数据集(POLIGEN和ECONOLEX)上的表现,这两个数据集涵盖了政治和经济领域,这些领域的框架偏见最为明显。除了文本生成,LLM越来越多地被用作评估器(LLM-as-a-judge),提供可以塑造人类判断或为新模型版本提供信息的反馈。受苏格拉底方法的启发,我们进一步分析LLM对其自身输出的反馈,以识别其推理中的不一致之处。结果表明,大多数LLM可以准确地注释意识形态框架文本,其中GPT-4o达到了人类水平的准确性,并与人类注释者高度一致。然而,苏格拉底式探究表明,当面对二元比较时,LLM通常表现出对一种观点的偏好,或者认为某些观点的偏见较小。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在文本生成过程中存在的意识形态框架偏见问题。现有方法难以有效识别和消除这种微妙且主观的偏见,尤其是在政治和经济等敏感领域。这种偏见可能导致生成的文本带有倾向性,影响读者判断,甚至加剧社会对立。
核心思路:论文的核心思路是借鉴苏格拉底方法,通过让LLM评估自身生成的文本,并进行二元比较,从而揭示其在意识形态框架偏见上的推理不一致性。这种方法能够深入探究LLM的潜在倾向,发现其在不同观点之间的偏好或偏见认知。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 使用POLIGEN和ECONOLEX数据集,这两个数据集涵盖了政治和经济领域的文本,这些领域的框架偏见最为明显。2) 使用八个广泛使用的LLM生成文本。3) 让LLM作为评估器(LLM-as-a-judge)评估自身生成的文本,并提供反馈。4) 通过苏格拉底式探究,分析LLM在二元比较中的推理一致性,识别其潜在的意识形态框架偏见。
关键创新:该研究的关键创新在于将苏格拉底方法应用于LLM偏见分析。通过让LLM自我评估,并进行二元比较,能够更深入地揭示其潜在的意识形态框架偏见。与传统的偏见检测方法相比,该方法更具探索性和启发性,能够发现LLM在推理过程中的细微偏差。
关键设计:研究的关键设计包括:1) 选择POLIGEN和ECONOLEX数据集,确保研究的领域相关性和偏见代表性。2) 选择八个广泛使用的LLM,以保证研究结果的普适性。3) 设计苏格拉底式探究流程,包括二元比较和一致性分析,以有效揭示LLM的潜在偏见。4) 使用GPT-4o作为评估器,并与人类注释者进行对比,以验证LLM评估的准确性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GPT-4o在意识形态框架文本注释方面达到了人类水平的准确性,并与人类注释者高度一致。然而,苏格拉底式探究揭示,当面对二元比较时,LLM通常表现出对一种观点的偏好,或者认为某些观点的偏见较小。这表明即使是表现最佳的LLM也存在潜在的意识形态框架偏见。
🎯 应用场景
该研究成果可应用于提升LLM生成文本的客观性和公正性,尤其是在新闻报道、政策建议等领域。通过识别和消除LLM的意识形态框架偏见,可以减少其对社会舆论的负面影响,促进更公平和理性的讨论。此外,该研究方法也可用于评估和改进其他AI系统的公平性和透明度。
📄 摘要(原文)
Large Language Models (LLMs) are widely used for text generation, making it crucial to address potential bias. This study investigates ideological framing bias in LLM-generated articles, focusing on the subtle and subjective nature of such bias in journalistic contexts. We evaluate eight widely used LLMs on two datasets-POLIGEN and ECONOLEX-covering political and economic discourse where framing bias is most pronounced. Beyond text generation, LLMs are increasingly used as evaluators (LLM-as-a-judge), providing feedback that can shape human judgment or inform newer model versions. Inspired by the Socratic method, we further analyze LLMs' feedback on their own outputs to identify inconsistencies in their reasoning. Our results show that most LLMs can accurately annotate ideologically framed text, with GPT-4o achieving human-level accuracy and high agreement with human annotators. However, Socratic probing reveals that when confronted with binary comparisons, LLMs often exhibit preference toward one perspective or perceive certain viewpoints as less biased.