Investigating Retrieval-Augmented Generation in Quranic Studies: A Study of 13 Open-Source Large Language Models
作者: Zahra Khalila, Arbi Haza Nasution, Winda Monika, Aytug Onan, Yohei Murakami, Yasir Bin Ismail Radi, Noor Mohammad Osmani
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-20
备注: 11 pages, keywords: Large-language-models; retrieval-augmented generation; question answering; Quranic studies; Islamic teachings
期刊: International Journal of Advanced Computer Science and Applications(IJACSA), 16(2), 2025
DOI: 10.14569/IJACSA.2025.01602134
💡 一句话要点
利用检索增强生成技术提升大型语言模型在古兰经研究中的准确性和可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 大型语言模型 古兰经研究 领域知识 幻觉问题
📋 核心要点
- 通用LLM在古兰经研究等特定领域易产生幻觉,导致生成内容偏离权威来源,影响可靠性。
- 采用检索增强生成(RAG)技术,使LLM在生成答案前检索相关领域知识,提高准确性和忠实性。
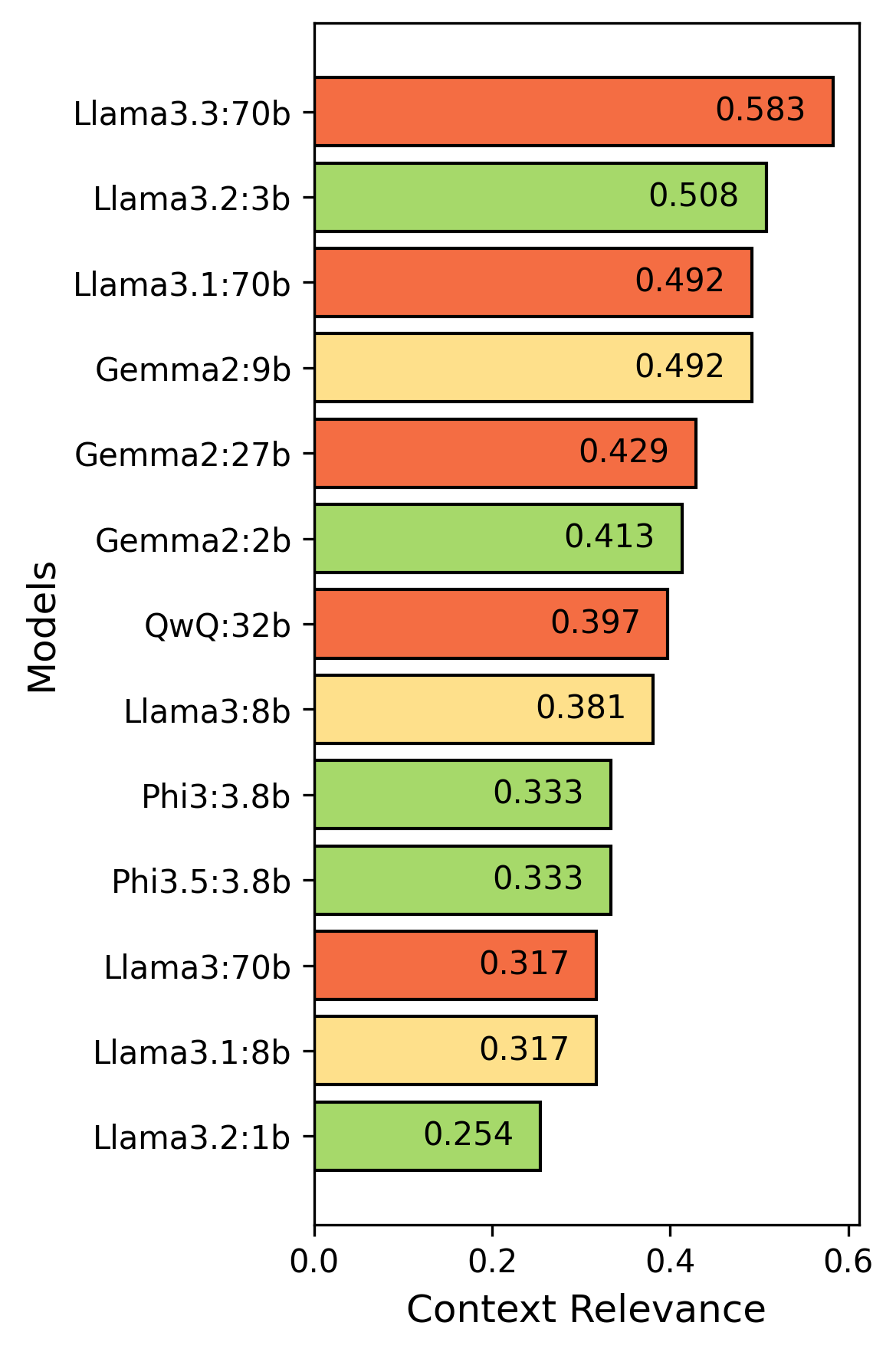
- 实验评估了13个开源LLM,结果表明大型模型表现更优,但优化后的小型模型在特定指标上表现出色。
📝 摘要(中文)
本研究探讨了检索增强生成(RAG)技术在古兰经研究领域的应用,旨在解决通用大型语言模型(LLM)在该领域中存在的幻觉问题,即生成的内容偏离权威来源。研究评估了13个开源LLM,包括大型(如Llama3:70b, Gemma2:27b, QwQ:32b)、中型(如Gemma2:9b, Llama3:8b)和小型模型(如Llama3.2:3b, Phi3:3.8b)。通过RAG方法,模型在回答问题前能够检索相关知识。评估指标包括上下文相关性、答案忠实性和答案相关性。结果表明,大型模型在捕捉查询语义和生成准确、基于上下文的回答方面表现更优。值得注意的是,小型模型Llama3.2:3b在忠实性和相关性方面表现出色,证明了优化后的小型架构的潜力。本研究探讨了模型大小、计算效率和响应质量之间的权衡。
🔬 方法详解
问题定义:现有通用大型语言模型在处理古兰经研究等领域特定任务时,容易产生幻觉,即生成与权威来源不符的内容。这降低了模型在宗教等敏感领域的可靠性。现有的方法缺乏对领域知识的有效整合,难以保证答案的准确性和忠实性。
核心思路:本研究的核心思路是利用检索增强生成(RAG)技术,使LLM在生成答案之前,能够从领域知识库中检索相关信息。通过将检索到的信息作为上下文,引导LLM生成更准确、更忠实于原始资料的答案。这样可以有效缓解LLM的幻觉问题,提高其在特定领域的应用价值。
技术框架:该研究采用的整体框架包括以下几个主要模块:1) 问题输入:接收用户关于古兰经研究的提问。2) 信息检索:利用检索模型(具体模型未知)从包含古兰经章节含义、历史背景和特点的知识库中检索相关信息。3) 上下文增强:将检索到的信息与原始问题结合,形成增强的上下文。4) 答案生成:利用LLM基于增强的上下文生成答案。5) 答案评估:通过人工评估,衡量答案的上下文相关性、忠实性和相关性。
关键创新:本研究的关键创新在于将RAG技术应用于古兰经研究领域,并系统地评估了不同规模的开源LLM在该任务上的表现。通过实验,研究者能够分析模型大小、计算效率和响应质量之间的权衡关系,为领域特定LLM的应用提供指导。
关键设计:研究中使用了包含114个古兰经章节含义、历史背景和特点的描述性数据集作为知识库。评估指标包括:1) 上下文相关性:衡量检索到的信息与问题的相关程度。2) 答案忠实性:衡量生成的答案与检索到的信息的一致程度。3) 答案相关性:衡量生成的答案是否回答了用户的问题。具体参数设置和损失函数等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,大型LLM在上下文相关性、答案忠实性和答案相关性方面通常优于小型模型。然而,小型模型Llama3.2:3b在忠实性(4.619)和相关性(4.857)方面表现出色,证明了优化后的小型模型在特定任务上的潜力。该研究揭示了模型大小、计算效率和响应质量之间的权衡关系。
🎯 应用场景
该研究成果可应用于开发智能古兰经问答系统、宗教知识库构建、辅助宗教研究等领域。通过提高LLM在宗教领域的准确性和可靠性,有助于促进宗教知识的传播和理解,并为相关研究提供技术支持。未来可扩展到其他宗教或文化领域。
📄 摘要(原文)
Accurate and contextually faithful responses are critical when applying large language models (LLMs) to sensitive and domain-specific tasks, such as answering queries related to quranic studies. General-purpose LLMs often struggle with hallucinations, where generated responses deviate from authoritative sources, raising concerns about their reliability in religious contexts. This challenge highlights the need for systems that can integrate domain-specific knowledge while maintaining response accuracy, relevance, and faithfulness. In this study, we investigate 13 open-source LLMs categorized into large (e.g., Llama3:70b, Gemma2:27b, QwQ:32b), medium (e.g., Gemma2:9b, Llama3:8b), and small (e.g., Llama3.2:3b, Phi3:3.8b). A Retrieval-Augmented Generation (RAG) is used to make up for the problems that come with using separate models. This research utilizes a descriptive dataset of Quranic surahs including the meanings, historical context, and qualities of the 114 surahs, allowing the model to gather relevant knowledge before responding. The models are evaluated using three key metrics set by human evaluators: context relevance, answer faithfulness, and answer relevance. The findings reveal that large models consistently outperform smaller models in capturing query semantics and producing accurate, contextually grounded responses. The Llama3.2:3b model, even though it is considered small, does very well on faithfulness (4.619) and relevance (4.857), showing the promise of smaller architectures that have been well optimized. This article examines the trade-offs between model size, computational efficiency, and response quality while using LLMs in domain-specific applications.