Fin-R1: A Large Language Model for Financial Reasoning through Reinforcement Learning
作者: Zhaowei Liu, Xin Guo, Zhi Yang, Fangqi Lou, Lingfeng Zeng, Mengping Li, Qi Qi, Zhiqiang Liu, Yiyang Han, Dongpo Cheng, Xingdong Feng, Huixia Judy Wang, Chengchun Shi, Liwen Zhang
分类: cs.CL
发布日期: 2025-03-20 (更新: 2025-12-18)
🔗 代码/项目: GITHUB
💡 一句话要点
提出Fin-R1:一个通过强化学习进行金融推理的大语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 金融推理 大语言模型 强化学习 监督微调 思维链 金融数据集 合规性检查
📋 核心要点
- 现有通用大语言模型在金融领域应用面临数据分散、推理不透明和迁移性弱等挑战。
- Fin-R1通过构建高质量金融数据集并结合监督微调和强化学习,提升金融推理能力。
- Fin-R1在金融基准测试中表现出色,并在合规检查和机器人咨询等实际应用中展现了潜力。
📝 摘要(中文)
近年来,GPT、Gemini、Claude和DeepSeek等通用大语言模型(LLMs)取得了前所未有的进展。然而,由于数据来源分散、推理过程不透明以及向商业应用的可迁移性较弱,它们在金融领域的应用仍然具有挑战性。为了应对这些挑战,我们推出了Fin-R1,一个专为金融场景设计的推理LLM。Fin-R1具有70亿个参数,体积紧凑,降低了部署成本,同时解决了上述挑战。其开发过程分为两个阶段。首先,我们构建了Fin-R1-Data,一个高质量的金融数据集,包含60,091个思维链(CoT)样本,这些样本从多个权威基准中提炼和过滤,以确保一致性和可靠性。其次,我们使用Fin-R1-Data通过监督微调(SFT)训练Fin-R1,然后进行强化学习(RL)。这个阶段大大提高了模型解决复杂金融推理任务的能力,产生了准确且可解释的输出。尽管参数规模相对较小,但Fin-R1在已建立的金融基准测试中取得了具有竞争力的经验性能,并在合规性检查和机器人咨询中展示了实际效用。我们的代码已在https://github.com/SUFE-AIFLM-Lab/Fin-R1上公开,并已吸引了超过700个star。
🔬 方法详解
问题定义:论文旨在解决通用大语言模型在金融领域应用时面临的挑战,包括数据来源分散、推理过程不透明以及向商业应用的可迁移性较弱等问题。现有方法难以有效处理金融领域复杂的推理任务,缺乏针对性和可解释性。
核心思路:论文的核心思路是构建一个专门针对金融领域的、参数量较小但推理能力强大的大语言模型Fin-R1。通过高质量的金融数据集和强化学习,提升模型在金融场景下的推理能力和可解释性。
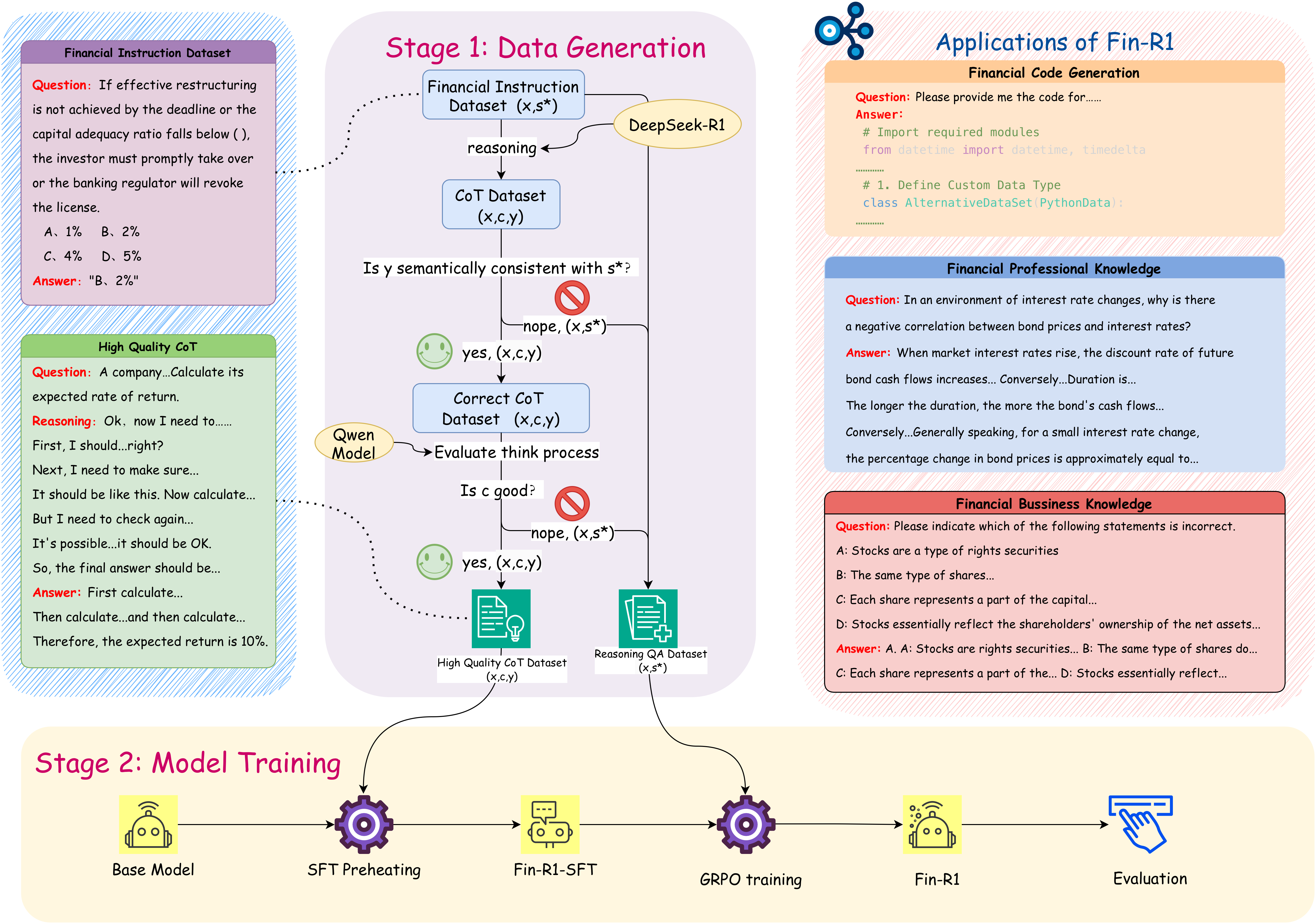
技术框架:Fin-R1的训练分为两个阶段:首先,构建高质量的金融数据集Fin-R1-Data,包含60,091个思维链(CoT)样本,这些样本从多个权威基准中提炼和过滤。其次,使用Fin-R1-Data通过监督微调(SFT)训练Fin-R1,然后进行强化学习(RL),以进一步提升模型性能。
关键创新:论文的关键创新在于构建了高质量的金融数据集Fin-R1-Data,并结合监督微调和强化学习,使得模型能够在参数量较小的情况下,在金融推理任务上取得优异的性能。这种方法降低了部署成本,并提高了模型的可解释性。
关键设计:Fin-R1-Data数据集的构建过程至关重要,需要仔细筛选和提炼数据,确保数据的一致性和可靠性。强化学习阶段的具体奖励函数设计未知,但其目标是提升模型在复杂金融推理任务上的准确性和可解释性。
🖼️ 关键图片


📊 实验亮点
Fin-R1在已建立的金融基准测试中取得了具有竞争力的经验性能,证明了其在金融推理任务上的有效性。尽管模型参数规模相对较小(70亿),但其性能优于许多更大的通用语言模型。此外,Fin-R1在合规性检查和机器人咨询等实际应用中展示了良好的实用性。
🎯 应用场景
Fin-R1具有广泛的应用前景,包括合规性检查、机器人咨询、风险评估、投资决策支持等金融领域。该模型能够提供准确且可解释的金融推理结果,帮助金融机构提高效率、降低风险,并为投资者提供更智能的决策支持。未来,Fin-R1有望成为金融领域的重要工具。
📄 摘要(原文)
In recent years, general-purpose large language models (LLMs) such as GPT, Gemini, Claude, and DeepSeek have advanced at an unprecedented pace. Despite these achievements, their application to finance remains challenging, due to fragmented data sources, intransparent reasoning processes, and weak transferability to business applications. In response, we introduce Fin-R1, a reasoning LLM designed for financial scenarios. With a compact size of 7 billion parameters, Fin-R1 reduces deployment costs while addressing the aforementioned challenges. Its development follows a two-stage pipeline. First, we construct Fin-R1-Data, a high-quality financial dataset consisting of 60,091 chain-of-thought (CoT) samples, distilled and filtered from multiple authoritative benchmarks to ensure consistency and reliability. Second, we train Fin-R1 using Fin-R1-Data through supervised fine-tuning (SFT), followed by reinforcement learning (RL). This stage substantially improves the model's ability to solve complex financial reasoning tasks, yielding outputs that are both accurate and interpretable. Despite its relatively small parameter scale, Fin-R1 achieves competitive empirical performance across established financial benchmarks and demonstrates practical utility in compliance checking and robo-advisory. Our code is publicly available at https://github.com/SUFE-AIFLM-Lab/Fin-R1, and has already attracted over 700 stars.