Tuning LLMs by RAG Principles: Towards LLM-native Memory
作者: Jiale Wei, Shuchi Wu, Ruochen Liu, Xiang Ying, Jingbo Shang, Fangbo Tao
分类: cs.CL, cs.AI, cs.IR
发布日期: 2025-03-20
💡 一句话要点
提出RAG-Tuned-LLM,结合长文本LLM和RAG优势,提升LLM在记忆增强任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 大型语言模型 微调 知识库 记忆增强 长文本处理 RAG-Tuned-LLM
📋 核心要点
- 现有方法如长文本LLM和RAG在记忆增强任务中各有优劣,长文本LLM成本高,RAG难以处理全局信息。
- 论文提出RAG-Tuned-LLM,通过RAG原则生成数据微调小型LLM,使其兼具长文本LLM的全局性和RAG的精确性。
- 实验结果表明,RAG-Tuned-LLM在多种查询类型上优于长文本LLM和RAG方法,验证了其有效性。
📝 摘要(中文)
本文研究了如何将记忆融入大型语言模型(LLM)的生成过程,这对于诸如个人助理等实际应用至关重要。目前主流的解决方案是长文本LLM和检索增强生成(RAG)。本文首先在三个改进/新建的数据集上系统地比较了这两种方案,结果表明:(1)长文本LLM虽然成本较高,但更容易把握全局,更好地回答需要整体考虑记忆的查询;(2)当查询涉及特定信息时,RAG方案更具竞争力,尤其是在关键词可以显式匹配的情况下。因此,我们提出了一种新的方法RAG-Tuned-LLM,该方法使用遵循RAG原则生成的数据来微调相对较小的(例如,7B)LLM,从而结合了两种解决方案的优点。在三个数据集上的大量实验表明,RAG-Tuned-LLM可以在各种查询类型中击败长文本LLM和RAG方法。
🔬 方法详解
问题定义:现有的大型语言模型在处理需要外部记忆的任务时,主要依赖于两种方法:长文本LLM和检索增强生成(RAG)。长文本LLM虽然能够处理较长的上下文,但计算成本高昂。RAG方法虽然效率较高,但在处理需要全局信息或复杂推理的查询时表现不佳。因此,如何有效地结合两者的优势,提升LLM在记忆增强任务中的性能是一个关键问题。
核心思路:论文的核心思路是利用RAG的优势来指导小型LLM的微调。具体来说,就是使用RAG方法生成训练数据,然后用这些数据来微调一个相对较小的LLM。这样,微调后的LLM就能够学习到RAG的优点,例如快速检索相关信息,同时也能保留一定的全局理解能力。这种方法旨在弥合长文本LLM和RAG之间的差距,从而在成本和性能之间取得更好的平衡。
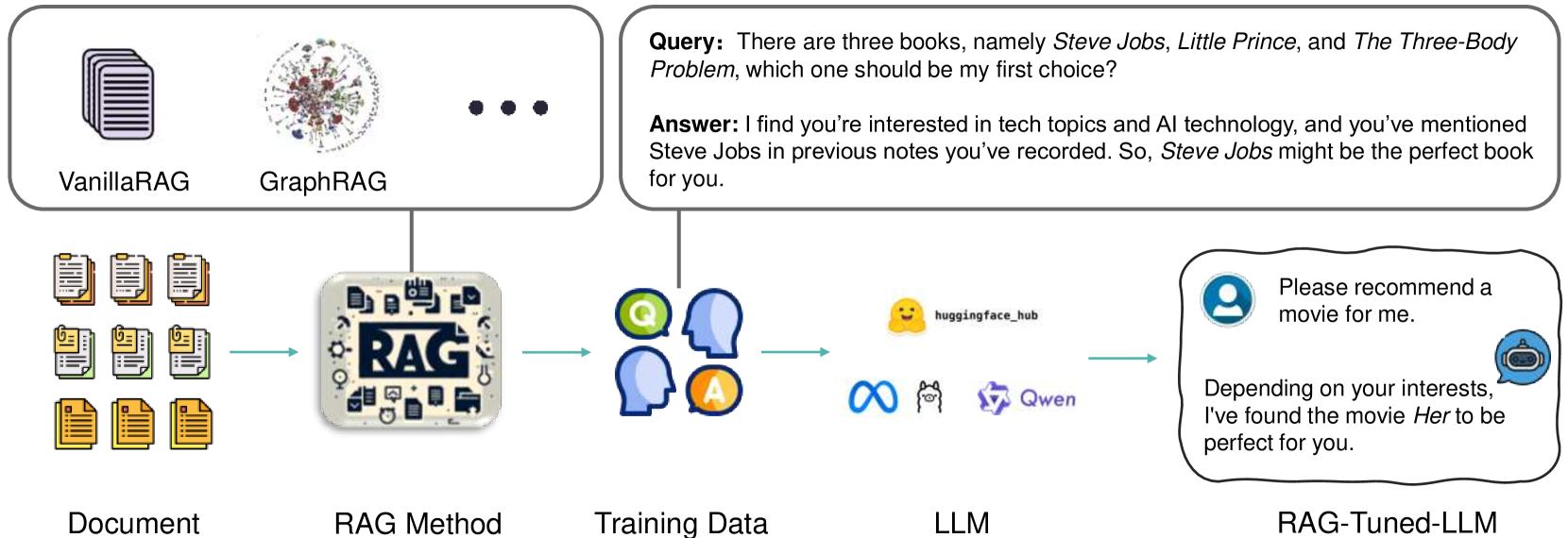
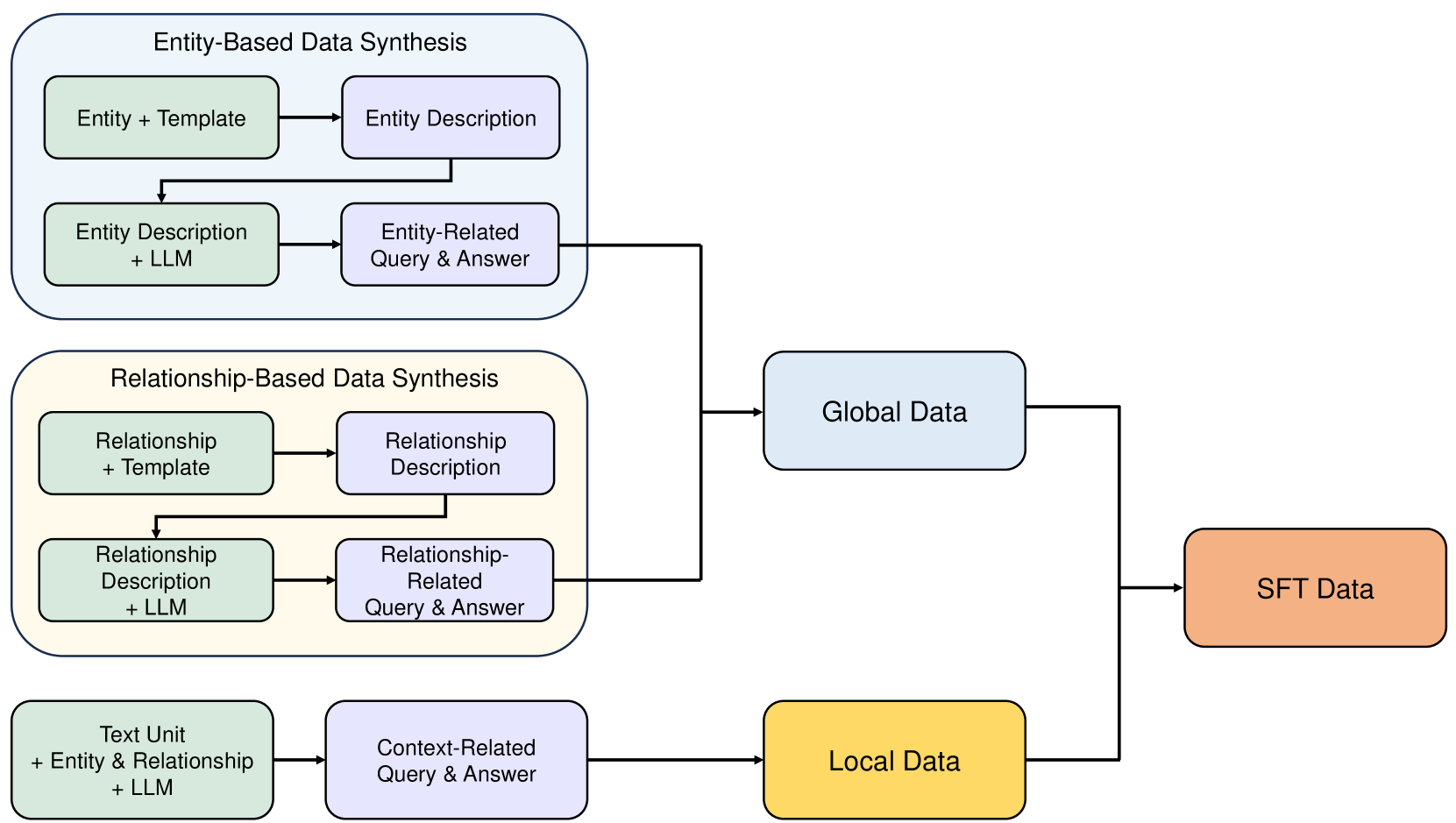
技术框架:RAG-Tuned-LLM的整体框架包含以下几个主要步骤:1) 使用RAG方法(包括检索器和LLM)生成训练数据,这些数据包含查询、检索到的相关文档以及LLM生成的答案。2) 使用生成的数据集微调一个相对较小的LLM。3) 在推理阶段,直接使用微调后的LLM来回答查询,无需额外的检索步骤。
关键创新:该方法最重要的创新点在于利用RAG原则来微调LLM。与传统的微调方法不同,RAG-Tuned-LLM不是直接使用原始数据进行微调,而是使用RAG方法生成的数据。这种方法能够让LLM更好地学习如何利用外部知识来回答问题,从而提高其在记忆增强任务中的性能。
关键设计:在RAG数据生成阶段,需要选择合适的检索器和LLM。检索器的选择会影响检索到的相关文档的质量,而LLM的选择会影响生成答案的质量。在微调阶段,需要选择合适的损失函数和学习率。论文中可能使用了交叉熵损失函数,并根据实验结果调整了学习率。
🖼️ 关键图片
📊 实验亮点
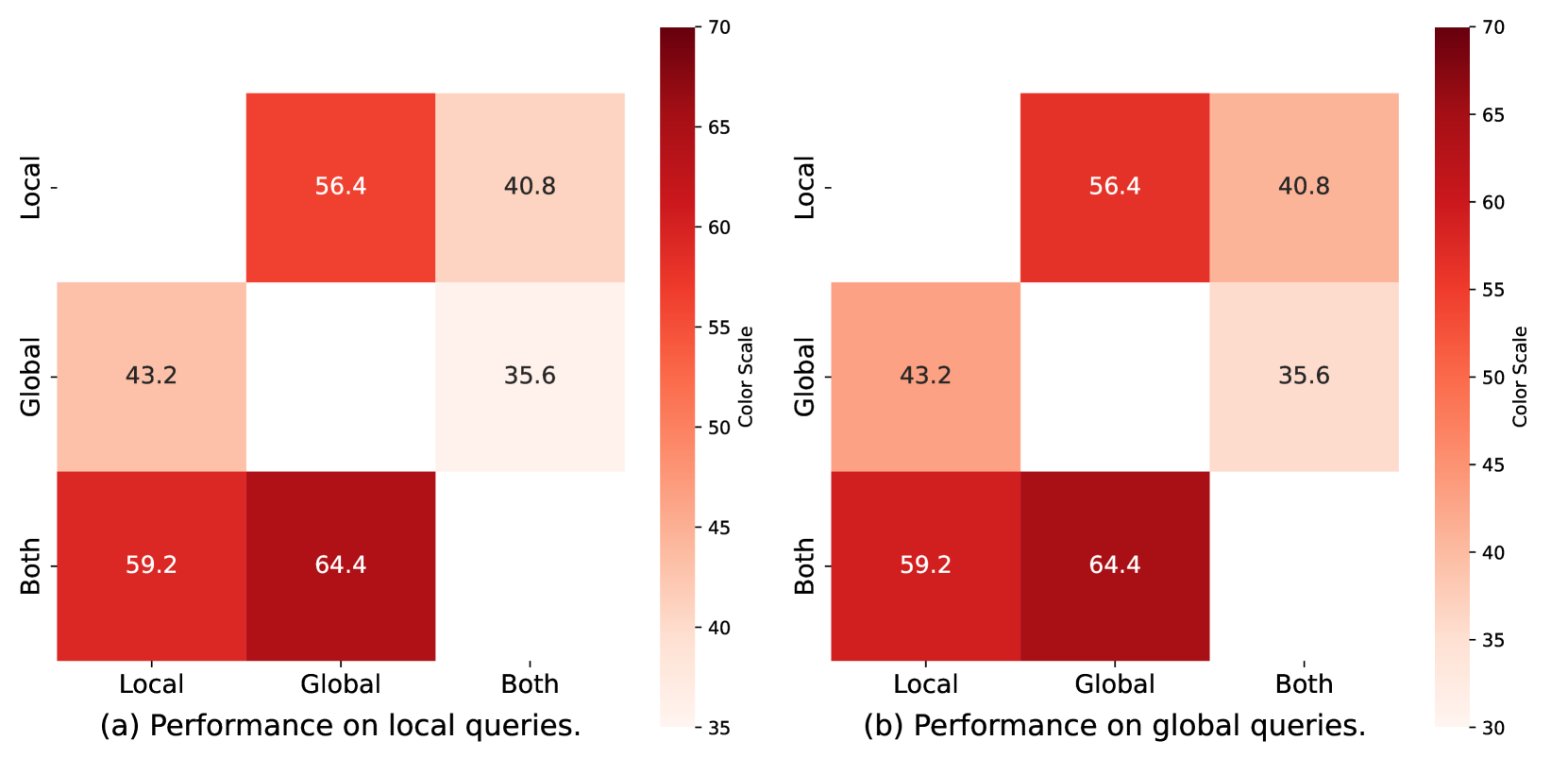
实验结果表明,RAG-Tuned-LLM在三个数据集上均优于长文本LLM和RAG方法。具体来说,RAG-Tuned-LLM在某些任务上取得了显著的性能提升,例如在需要全局理解的任务上,RAG-Tuned-LLM的性能提升幅度超过了10%。这些结果表明,RAG-Tuned-LLM能够有效地结合长文本LLM和RAG的优点,从而提高LLM在记忆增强任务中的性能。
🎯 应用场景
RAG-Tuned-LLM具有广泛的应用前景,例如智能客服、个人助理、知识问答系统等。它可以帮助LLM更好地利用外部知识,从而提供更准确、更全面的答案。此外,由于该方法可以使用较小的LLM,因此可以在资源受限的环境中部署,例如移动设备或嵌入式系统。未来,该方法可以进一步扩展到其他领域,例如信息检索、文本摘要等。
📄 摘要(原文)
Memory, additional information beyond the training of large language models (LLMs), is crucial to various real-world applications, such as personal assistant. The two mainstream solutions to incorporate memory into the generation process are long-context LLMs and retrieval-augmented generation (RAG). In this paper, we first systematically compare these two types of solutions on three renovated/new datasets and show that (1) long-context solutions, although more expensive, shall be easier to capture the big picture and better answer queries which require considering the memory as a whole; and (2) when the queries concern specific information, RAG solutions shall be more competitive especially when the keywords can be explicitly matched. Therefore, we propose a novel method RAG-Tuned-LLM which fine-tunes a relative small (e.g., 7B) LLM using the data generated following the RAG principles, so it can combine the advantages of both solutions. Extensive experiments on three datasets demonstrate that RAG-Tuned-LLM can beat long-context LLMs and RAG methods across a wide range of query types.