Evaluating Test-Time Scaling LLMs for Legal Reasoning: OpenAI o1, DeepSeek-R1, and Beyond
作者: Yinghao Hu, Yaoyao Yu, Leilei Gan, Bin Wei, Kun Kuang, Fei Wu
分类: cs.CL
发布日期: 2025-03-20 (更新: 2025-11-10)
备注: 23 pages, Published in Findings of the Association for Computational Linguistics: EMNLP 2025
DOI: 10.18653/v1/2025.findings-emnlp.742
💡 一句话要点
评估测试时扩展LLM在法律推理中的表现:OpenAI o1、DeepSeek-R1及其他模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 法律推理 大型语言模型 测试时扩展 知识蒸馏 Legal-R1 DeepSeek-R1 法律人工智能
📋 核心要点
- 现有方法在法律推理方面存在不足,尤其是在测试时扩展LLM能力方面缺乏充分评估。
- 通过构建双语法律推理数据集并开发Legal-R1模型,探索LLM在法律领域的应用潜力。
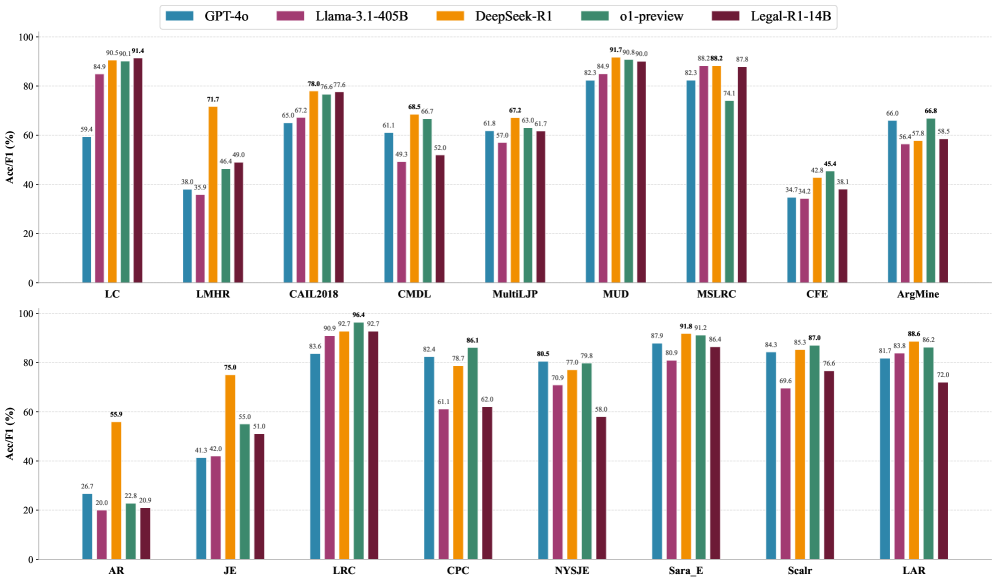
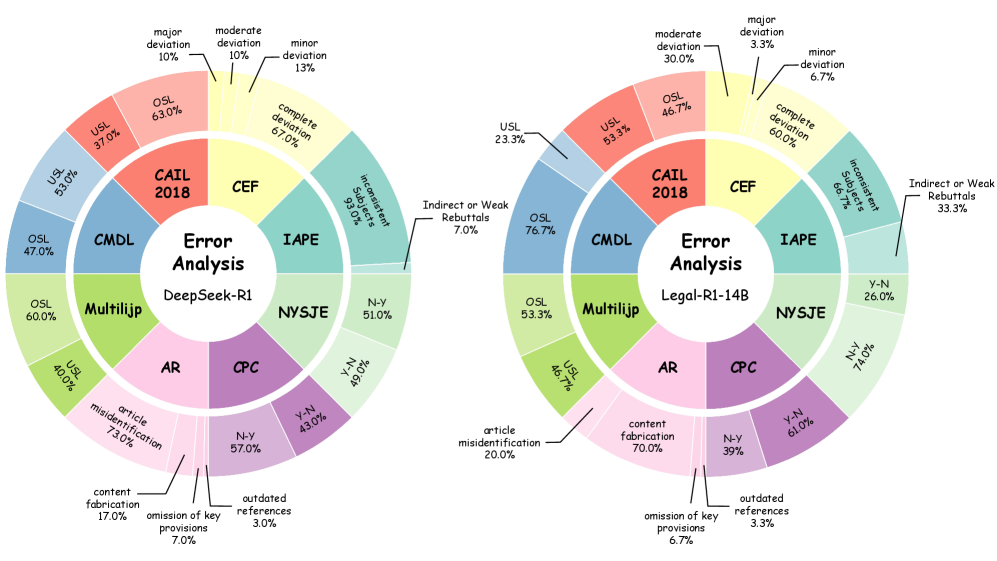
- 实验结果表明,Legal-R1具有竞争力,DeepSeek-R1在中文法律推理方面表现突出,但仍存在知识过时等问题。
📝 摘要(中文)
本文针对大型语言模型(LLMs)的测试时扩展能力在法律推理领域的应用进行了系统性评估,特别是DeepSeek-R1和OpenAI的o1等模型。研究表明,在推理过程中扩展思维链可以显著提高通用推理性能,但其对法律推理的影响尚不明确。为此,本文对12个LLM(包括推理型和通用型)在17个中英文法律任务上进行了评估,涵盖成文法和判例法。此外,本文还通过从DeepSeek-R1中蒸馏知识,构建了一个双语法律推理思维链数据集,并开发了专门针对法律领域的开源模型Legal-R1。实验结果表明,Legal-R1在各种任务中表现出竞争力。DeepSeek-R1在中文法律推理方面表现出明显优势,而OpenAI的o1在英文任务上取得了相当的结果。详细的错误分析揭示了诸如法律知识过时、法律解释能力有限以及容易出现事实幻觉等问题。这些发现指出了法律领域LLM面临的主要障碍,并为未来的研究提出了有希望的方向。
🔬 方法详解
问题定义:现有的大型语言模型在通用推理任务上取得了显著进展,但其在法律领域的推理能力仍有待考察。特别是在测试时扩展(Test-Time Scaling)LLM,例如增加推理步骤或使用更长的思维链,是否能有效提升法律推理性能,以及不同模型在不同法律体系(如成文法和判例法)下的表现差异,这些问题尚未得到充分研究。现有方法的痛点在于缺乏针对法律领域的系统性评估和专门优化。
核心思路:本文的核心思路是通过构建一个全面的法律推理评估基准,并对多个LLM进行测试,从而深入了解它们在法律领域的优势和不足。此外,通过知识蒸馏的方式,从强大的LLM(DeepSeek-R1)中提取知识,构建一个专门针对法律领域的模型(Legal-R1),以提升模型在法律推理方面的性能。这样设计的目的是为了弥补现有方法在法律领域评估和优化方面的空白。
技术框架:整体框架包括以下几个主要阶段:1) 数据收集与整理:收集涵盖中英文、成文法和判例法的法律任务数据集。2) 模型选择与配置:选择一系列具有代表性的LLM,包括通用型和推理型模型,并配置合适的测试时扩展策略。3) 知识蒸馏:利用DeepSeek-R1生成法律推理的思维链数据,并以此训练Legal-R1模型。4) 评估与分析:在法律推理基准上评估各个模型的性能,并进行详细的错误分析。
关键创新:本文最重要的技术创新点在于:1) 首次对测试时扩展LLM在法律推理领域的性能进行了系统性评估。2) 构建了一个双语法律推理思维链数据集,为法律领域LLM的研究提供了宝贵资源。3) 开发了专门针对法律领域的开源模型Legal-R1,为法律领域的应用提供了新的选择。与现有方法相比,本文更加关注LLM在法律领域的实际表现,并致力于构建专门的法律推理模型。
关键设计:在知识蒸馏过程中,使用了DeepSeek-R1生成的思维链作为训练数据,以提升Legal-R1的推理能力。具体的技术细节包括:选择合适的蒸馏损失函数,例如交叉熵损失或KL散度损失;调整训练参数,例如学习率和batch size,以获得最佳的蒸馏效果;对Legal-R1的网络结构进行微调,使其更适合处理法律领域的文本数据。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Legal-R1在多个法律推理任务中表现出竞争力,证明了知识蒸馏在法律领域的可行性。DeepSeek-R1在中文法律推理方面表现出明显优势,而OpenAI的o1在英文任务上取得了相当的结果。错误分析揭示了现有LLM在法律领域面临的挑战,例如法律知识过时和法律解释能力有限等。这些发现为未来的研究提供了重要的指导。
🎯 应用场景
该研究成果可应用于智能法律咨询、法律文书生成、案件分析与预测等领域。通过提升LLM在法律领域的推理能力,可以辅助律师、法官等专业人士提高工作效率,降低法律服务成本,并为公众提供更便捷的法律服务。未来,该研究有望推动法律人工智能的发展,促进法律行业的智能化转型。
📄 摘要(原文)
Recent advances in test-time scaling of large language models (LLMs), exemplified by DeepSeek-R1 and OpenAI's o1, show that extending the chain of thought during inference can significantly improve general reasoning performance. However, the impact of this paradigm on legal reasoning remains insufficiently explored. To address this gap, we present the first systematic evaluation of 12 LLMs, including both reasoning-focused and general-purpose models, across 17 Chinese and English legal tasks spanning statutory and case-law traditions. In addition, we curate a bilingual chain-of-thought dataset for legal reasoning through distillation from DeepSeek-R1 and develop Legal-R1, an open-source model specialized for the legal domain. Experimental results show that Legal-R1 delivers competitive performance across diverse tasks. DeepSeek-R1 exhibits clear advantages in Chinese legal reasoning, while OpenAI's o1 achieves comparable results on English tasks. We further conduct a detailed error analysis, which reveals recurring issues such as outdated legal knowledge, limited capacity for legal interpretation, and susceptibility to factual hallucinations. These findings delineate the main obstacles confronting legal-domain LLMs and suggest promising directions for future research.