Deceptive Humor: A Synthetic Multilingual Benchmark Dataset for Bridging Fabricated Claims with Humorous Content
作者: Sai Kartheek Reddy Kasu, Shankar Biradar, Sunil Saumya
分类: cs.CL
发布日期: 2025-03-20 (更新: 2025-06-19)
备注: 7 Pages, 2 figures, 7 tables
💡 一句话要点
提出Deceptive Humor数据集,用于评估幽默内容掩盖下的虚假信息识别
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 虚假信息检测 幽默分析 自然语言处理 多语言数据集 ChatGPT-4o
📋 核心要点
- 现有在线信息检测方法难以识别被幽默内容掩盖的虚假信息,导致其传播范围扩大。
- 论文提出Deceptive Humor数据集,包含多语言、多类型的幽默评论,并标注了讽刺等级。
- 该数据集可用于训练模型识别幽默内容中的虚假信息,并建立了基线以供后续研究参考。
📝 摘要(中文)
本文提出了一个名为“Deceptive Humor”的新研究方向,重点关注虚假叙事如何通过幽默的包装来逃避检测并获得更广泛的传播。为了支持该领域的研究,作者构建了Deceptive Humor Dataset (DHD),该数据集包含由ChatGPT-4o模型生成的、基于虚假声明的幽默评论。每个条目都标有讽刺等级(从1级代表微妙的讽刺到3级代表公开的讽刺),并被分为五种幽默类型:黑色幽默、讽刺、社会评论、文字游戏和荒诞。该数据集涵盖英语、泰卢固语、印地语、卡纳达语、泰米尔语及其混合代码形式,为多语言分析提供了宝贵的资源。DHD为理解幽默如何作为虚假信息传播的载体提供了结构化的基础,从而微妙地增强了其影响力和范围。论文建立了强大的基线,以鼓励在该新兴领域进行进一步的研究和模型开发。
🔬 方法详解
问题定义:论文旨在解决虚假信息通过幽默方式传播难以被检测的问题。现有方法难以有效识别这种伪装,导致虚假信息更容易获得关注和传播,对社会造成负面影响。
核心思路:论文的核心思路是构建一个包含多种语言和幽默类型的合成数据集,用于训练和评估模型识别幽默内容中隐藏的虚假信息。通过分析不同讽刺程度和幽默类型对信息传播的影响,提高模型对欺骗性幽默的识别能力。
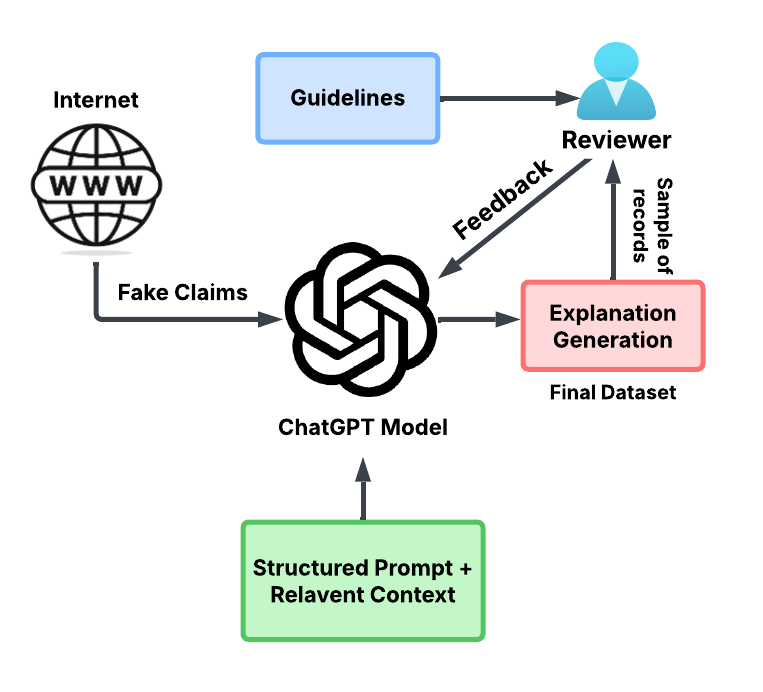
技术框架:该研究主要包含数据集构建和基线模型建立两个阶段。数据集构建阶段,利用ChatGPT-4o模型生成基于虚假声明的幽默评论,并进行人工标注,包括讽刺等级(1-3级)和幽默类型(黑色幽默、讽刺、社会评论、文字游戏、荒诞)。基线模型建立阶段,选择合适的自然语言处理模型,在构建的数据集上进行训练和评估,为后续研究提供参考。
关键创新:该研究的创新点在于首次关注幽默作为虚假信息传播媒介的问题,并构建了多语言、多类型的Deceptive Humor数据集。该数据集的构建方法和标注体系为后续研究提供了借鉴,有助于推动该领域的发展。
关键设计:数据集包含英语、泰卢固语、印地语、卡纳达语、泰米尔语及其混合代码形式,保证了多语言的覆盖。讽刺等级分为1-3级,用于区分不同程度的讽刺。幽默类型分为五种,涵盖了常见的幽默形式。使用ChatGPT-4o生成数据,保证了数据的多样性和质量。论文未明确说明损失函数和网络结构等细节,属于未知信息。
🖼️ 关键图片

📊 实验亮点
论文构建了包含多种语言和幽默类型的Deceptive Humor数据集,并建立了基线模型。虽然论文中没有给出具体的性能数据和提升幅度,但该数据集和基线模型为后续研究提供了重要的资源和参考,有助于推动该领域的发展。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核、舆情监控和虚假信息检测等领域。通过训练模型识别幽默内容中的虚假信息,可以有效减少虚假信息的传播,维护网络空间的健康和安全。未来,该研究可以扩展到更多语言和文化背景,提高模型的泛化能力。
📄 摘要(原文)
In the evolving landscape of online discourse, misinformation increasingly adopts humorous tones to evade detection and gain traction. This work introduces Deceptive Humor as a novel research direction, emphasizing how false narratives, when coated in humor, can become more difficult to detect and more likely to spread. To support research in this space, we present the Deceptive Humor Dataset (DHD) a collection of humor-infused comments derived from fabricated claims using the ChatGPT-4o model. Each entry is labeled with a Satire Level (from 1 for subtle satire to 3 for overt satire) and categorized into five humor types: Dark Humor, Irony, Social Commentary, Wordplay, and Absurdity. The dataset spans English, Telugu, Hindi, Kannada, Tamil, and their code-mixed forms, making it a valuable resource for multilingual analysis. DHD offers a structured foundation for understanding how humor can serve as a vehicle for the propagation of misinformation, subtly enhancing its reach and impact. Strong baselines are established to encourage further research and model development in this emerging area.