Command R7B Arabic: A Small, Enterprise Focused, Multilingual, and Culturally Aware Arabic LLM
作者: Yazeed Alnumay, Alexandre Barbet, Anna Bialas, William Darling, Shaan Desai, Joan Devassy, Kyle Duffy, Stephanie Howe, Olivia Lasche, Justin Lee, Anirudh Shrinivason, Jennifer Tracey
分类: cs.CL, cs.LG
发布日期: 2025-03-18
💡 一句话要点
Command R7B Arabic:面向企业,具备文化感知能力的小型多语种阿拉伯语LLM
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 阿拉伯语LLM 数据合成 人机协作标注 企业应用 文化感知 指令遵循 RAG
📋 核心要点
- 高质量阿拉伯语LLM的构建受限于阿拉伯语数字化数据的匮乏,这阻碍了其在企业级应用中的发展。
- 论文提出了一种数据合成与优化策略,结合合成数据生成与人工标注,有效扩展了阿拉伯语训练语料。
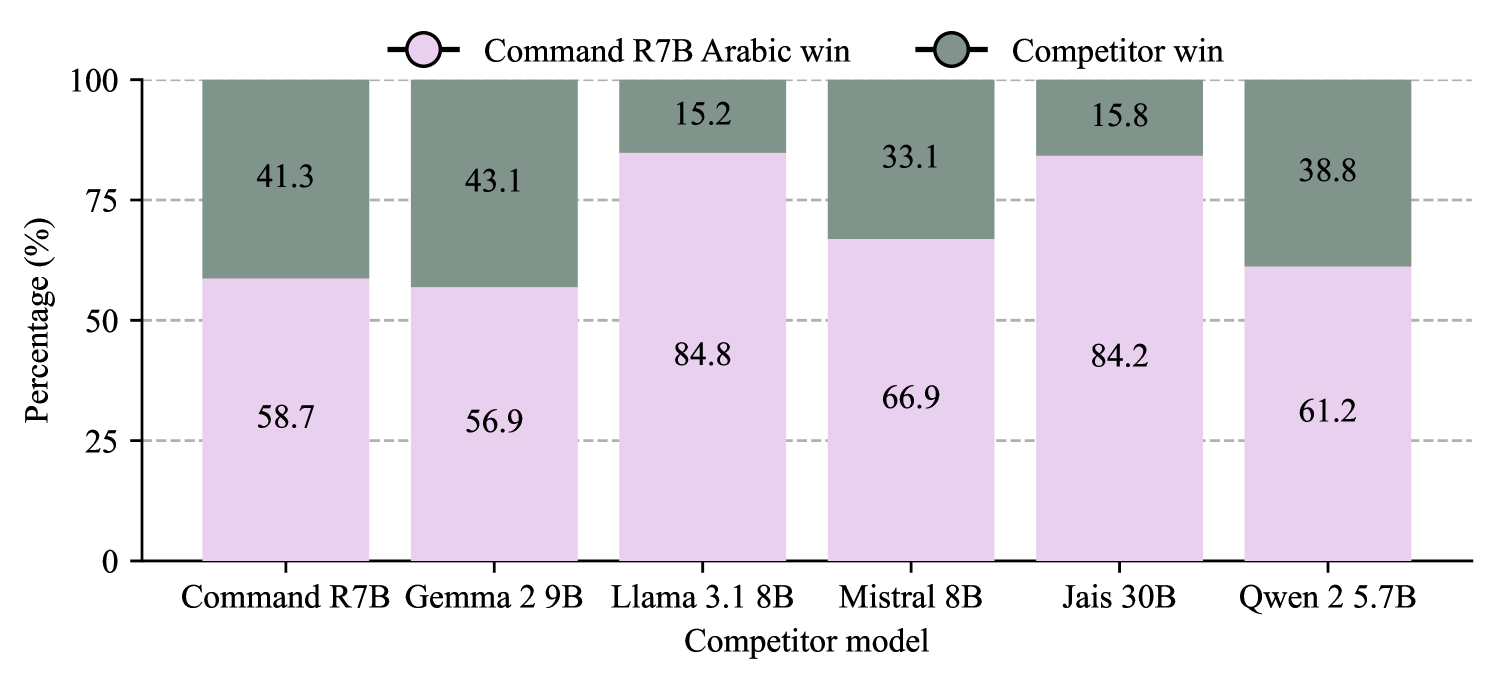
- Command R7B Arabic模型在文化知识、指令遵循等阿拉伯语基准测试中,性能超越了同等规模的其他模型。
📝 摘要(中文)
由于数字化阿拉伯语数据的有限性,构建高质量的面向企业应用的阿拉伯语大型语言模型(LLM)仍然具有挑战性。本文提出了一种数据合成和优化策略来解决这个问题,即利用合成数据生成和人机协作标注来扩展我们的阿拉伯语训练语料库。此外,我们还提出了迭代式的后训练方法,这对于实现模型与人类偏好对齐(企业用例的关键方面)方面的最先进性能至关重要。最终成果是一个小型的、70亿参数的、开放权重的模型,在直接比较以及涵盖文化知识、指令遵循、RAG和上下文忠实性的阿拉伯语基准测试中,优于同等规模的模型。
🔬 方法详解
问题定义:论文旨在解决企业级阿拉伯语应用中,由于高质量阿拉伯语数据稀缺而导致的大型语言模型(LLM)训练困难的问题。现有方法通常依赖于有限的公开阿拉伯语数据集,这限制了模型的性能和泛化能力,尤其是在文化敏感性和上下文理解方面。
核心思路:论文的核心思路是通过数据合成和人机协作标注相结合的方式,构建一个更大、更高质量的阿拉伯语训练数据集。同时,采用迭代式的后训练方法,使模型更好地与人类偏好对齐,从而提升模型在实际企业应用中的性能。
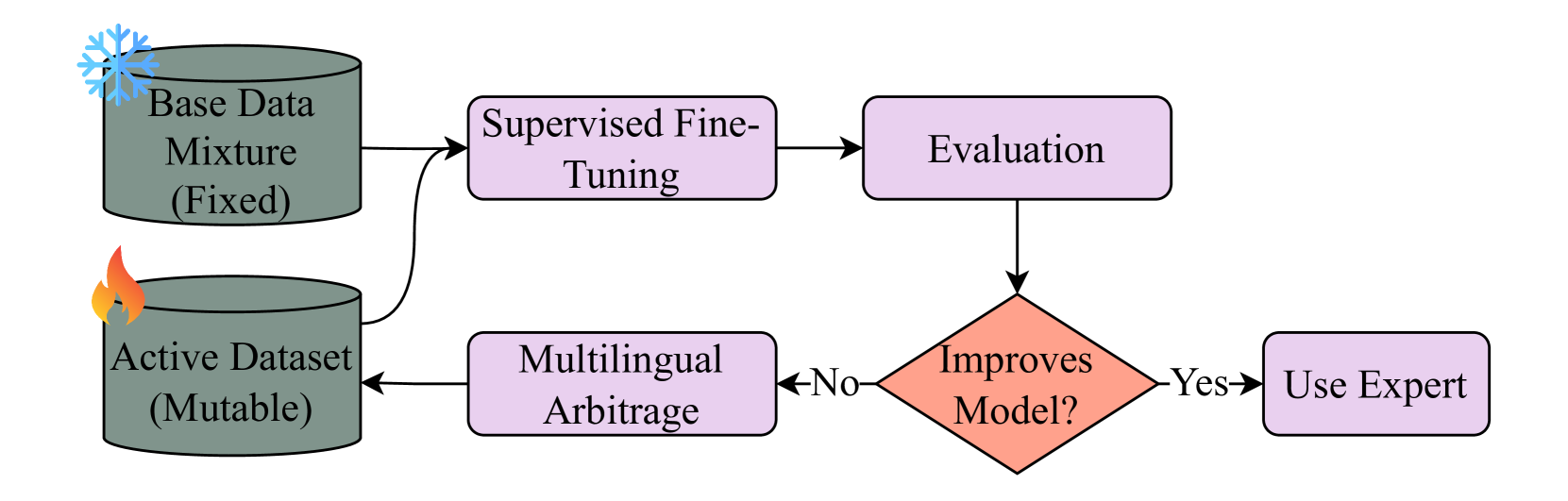
技术框架:该方法主要包含以下几个阶段:1) 数据合成:利用现有资源生成大量的合成阿拉伯语数据。2) 人机协作标注:通过人工标注对合成数据进行质量控制和优化。3) 模型训练:使用扩展后的数据集训练7B参数的LLM。4) 迭代后训练:通过迭代式的训练过程,不断优化模型,使其更好地与人类偏好对齐。
关键创新:该方法的关键创新在于结合了数据合成和人机协作标注,有效地解决了阿拉伯语数据稀缺的问题。此外,迭代式的后训练方法也显著提升了模型与人类偏好的对齐程度,使其更适合企业级应用。
关键设计:论文中关于数据合成的具体方法和标注策略未详细说明,属于未知信息。后训练阶段的具体损失函数和优化算法也未明确给出,属于未知信息。模型采用7B参数,具体网络结构细节未知。
🖼️ 关键图片

📊 实验亮点
Command R7B Arabic模型在阿拉伯语基准测试中表现出色,超越了同等规模的其他模型。具体性能数据未在摘要中给出,属于未知信息。该模型在文化知识、指令遵循、RAG和上下文忠实性等方面均有显著提升,表明其在理解和生成高质量阿拉伯语文本方面具有优势。
🎯 应用场景
该研究成果可广泛应用于需要阿拉伯语支持的企业级应用,例如智能客服、内容生成、信息检索和机器翻译等。该模型能够更好地理解阿拉伯语的文化背景和上下文信息,从而提供更准确、更自然的语言服务。未来,该模型有望促进阿拉伯语自然语言处理技术的发展,并为阿拉伯语用户带来更好的AI体验。
📄 摘要(原文)
Building high-quality large language models (LLMs) for enterprise Arabic applications remains challenging due to the limited availability of digitized Arabic data. In this work, we present a data synthesis and refinement strategy to help address this problem, namely, by leveraging synthetic data generation and human-in-the-loop annotation to expand our Arabic training corpus. We further present our iterative post training recipe that is essential to achieving state-of-the-art performance in aligning the model with human preferences, a critical aspect to enterprise use cases. The culmination of this effort is the release of a small, 7B, open-weight model that outperforms similarly sized peers in head-to-head comparisons and on Arabic-focused benchmarks covering cultural knowledge, instruction following, RAG, and contextual faithfulness.