PLAY2PROMPT: Zero-shot Tool Instruction Optimization for LLM Agents via Tool Play
作者: Wei Fang, Yang Zhang, Kaizhi Qian, James Glass, Yada Zhu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-18 (更新: 2025-06-12)
备注: ACL 2025 Long Paper (Findings)
💡 一句话要点
PLAY2PROMPT:通过工具试错优化LLM Agent的零样本工具指令
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 工具使用 零样本学习 指令优化 自动化探索
📋 核心要点
- 现有方法依赖手动重写或标注数据来提升LLM Agent的工具使用能力,在零样本场景下存在局限性。
- PLAY2PROMPT通过与工具交互,自动探索工具的输入输出行为,无需标注数据即可优化工具文档和生成使用示例。
- 实验表明,PLAY2PROMPT显著提升了LLM在零样本场景下的工具使用性能,适用于开放和封闭模型。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地与专门的外部工具集成,但许多任务需要在极少或嘈杂的文档下进行零样本工具使用。现有的解决方案依赖于手动重写或标记数据进行验证,这使得它们在真正的零样本设置中不适用。为了解决这些挑战,我们提出了PLAY2PROMPT,一个自动化的框架,它系统地“玩弄”每个工具,以探索其输入-输出行为。通过这种迭代的试错过程,PLAY2PROMPT改进了工具文档并生成了使用示例,无需任何标记数据。这些示例不仅指导LLM推理,还用作验证,以进一步增强工具利用率。在真实世界任务上的大量实验表明,PLAY2PROMPT显著提高了开放和封闭模型上的零样本工具性能,为特定领域的工具集成提供了一种可扩展且有效的解决方案。
🔬 方法详解
问题定义:论文旨在解决LLM Agent在零样本场景下,如何有效利用外部工具的问题。现有方法,如人工编写prompt或使用标注数据进行训练,成本高昂且难以泛化到新的工具或领域。特别是在工具文档不完善或存在噪声的情况下,LLM Agent难以正确理解和使用工具。
核心思路:PLAY2PROMPT的核心思路是通过与工具进行交互式“玩耍”,自动探索工具的输入输出行为,从而学习工具的使用方法。这种方法模拟了人类学习新工具的过程,即通过不断尝试和观察结果来理解工具的功能和使用规则。通过这种方式,可以无需人工干预或标注数据,即可提升LLM Agent的工具使用能力。
技术框架:PLAY2PROMPT框架主要包含以下几个阶段:1) 工具探索阶段:系统自动生成不同的输入,并提交给工具执行,记录工具的输出结果。2) 文档优化阶段:根据工具的输入输出行为,自动修正或补充工具的文档,使其更易于理解。3) 示例生成阶段:基于工具的输入输出记录,生成工具的使用示例,作为LLM Agent的prompt。4) 工具验证阶段:使用生成的示例验证LLM Agent的工具使用能力,并根据验证结果进一步优化prompt。
关键创新:PLAY2PROMPT的关键创新在于其完全自动化的工具探索和学习过程。与现有方法相比,它无需人工标注数据或手动编写prompt,即可有效地提升LLM Agent的工具使用能力。此外,PLAY2PROMPT还能够自动修正和补充工具文档,使其更易于理解和使用。
关键设计:在工具探索阶段,论文采用了一种基于策略的输入生成方法,以更有效地探索工具的输入空间。在文档优化阶段,论文使用了一种基于规则和统计的方法,自动修正和补充工具文档。在示例生成阶段,论文使用了一种基于模板的方法,生成高质量的工具使用示例。具体参数设置和损失函数等细节在论文中有详细描述。
🖼️ 关键图片

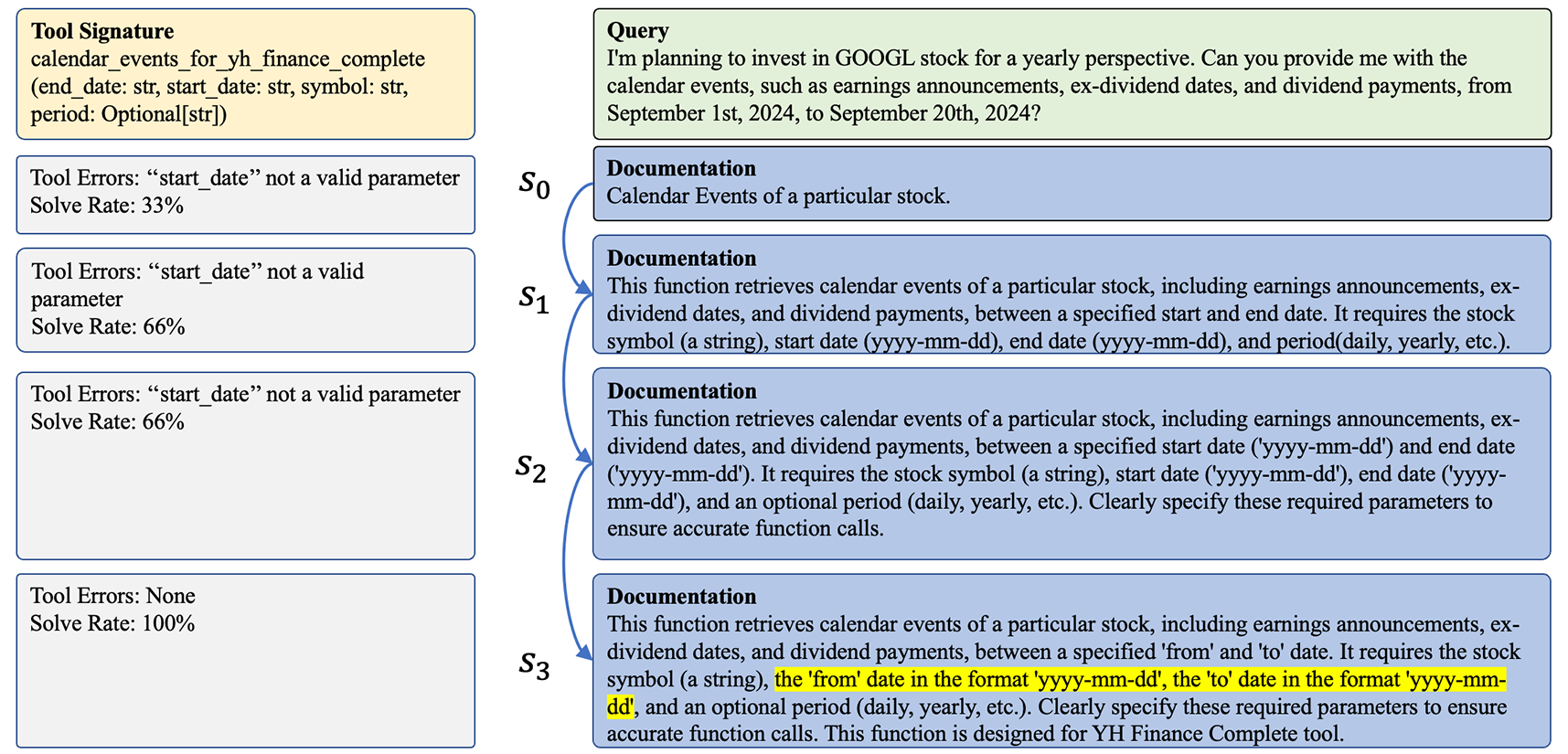

📊 实验亮点
PLAY2PROMPT在多个真实世界任务上进行了评估,实验结果表明,该方法能够显著提高LLM Agent的零样本工具使用性能。例如,在某个任务上,PLAY2PROMPT将LLM Agent的工具使用准确率提高了超过20%。此外,实验还表明,PLAY2PROMPT能够有效地修正和补充工具文档,使其更易于理解和使用。
🎯 应用场景
PLAY2PROMPT可广泛应用于各种需要LLM Agent与外部工具交互的场景,例如智能客服、自动化办公、科学研究等。该方法能够降低LLM Agent集成新工具的成本,提高其在特定领域的应用效果。未来,该研究可以进一步扩展到更复杂的工具和任务,实现更智能、更高效的自动化。
📄 摘要(原文)
Large language models (LLMs) are increasingly integrated with specialized external tools, yet many tasks demand zero-shot tool usage with minimal or noisy documentation. Existing solutions rely on manual rewriting or labeled data for validation, making them inapplicable in true zero-shot settings. To address these challenges, we propose PLAY2PROMPT, an automated framework that systematically "plays" with each tool to explore its input-output behaviors. Through this iterative trial-and-error process, PLAY2PROMPT refines tool documentation and generates usage examples without any labeled data. These examples not only guide LLM inference but also serve as validation to further enhance tool utilization. Extensive experiments on real-world tasks demonstrate that PLAY2PROMPT significantly improves zero-shot tool performance across both open and closed models, offering a scalable and effective solution for domain-specific tool integration.