AccelGen: Heterogeneous SLO-Guaranteed High-Throughput LLM Inference Serving for Diverse Applications
作者: Haiying Shen, Tanmoy Sen
分类: cs.CL
发布日期: 2025-03-17
💡 一句话要点
AccelGen:面向多样化应用,提供异构SLO保障的高吞吐量LLM推理服务系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM推理服务 异构SLO 动态分块 任务优先级排序 多资源感知批处理
📋 核心要点
- 现有LLM推理服务在处理混合长短提示请求时,难以兼顾高吞吐量和异构服务等级目标(SLO)需求。
- AccelGen通过动态分块、迭代级SLO优先级排序和多资源感知批处理,优化GPU和键值缓存利用率,满足异构SLO需求。
- 实验表明,AccelGen在吞吐量、goodput、SLO达成率和响应延迟方面均优于现有方法,性能接近最优的Oracle。
📝 摘要(中文)
本文针对大型语言模型(LLM)推理服务系统中的混合提示场景,该场景支持具有短提示和长提示以及迭代时间异构服务等级目标(SLO)的各种应用。为了提高处理长提示时的吞吐量,之前的研究引入了分块方法,但没有解决异构SLO的问题。为了解决这一局限性,我们提出了AccelGen,这是一个具有异构SLO保证的高吞吐量LLM推理服务系统,适用于各种应用。AccelGen引入了四个核心组件:(1)SLO保证的动态分块,它动态调整块大小,以最大限度地提高GPU计算利用率,同时满足迭代级别的SLO;(2)基于迭代级别SLO的任务优先级排序,它优先处理严格SLO的请求,并将具有相似SLO的请求进行批处理;(3)多资源感知批处理,它选择排队的请求,以最大限度地利用GPU计算资源和键值缓存(KVC)。基于trace驱动的真实实验表明,与最先进的方法相比,AccelGen实现了1.42-11.21倍更高的吞吐量,1.43-13.71倍更高的goodput,37-90%更高的SLO达成率,以及1.61-12.22倍更低的响应延迟。它实现了接近Oracle的性能,Oracle能够最佳地最大化goodput。
🔬 方法详解
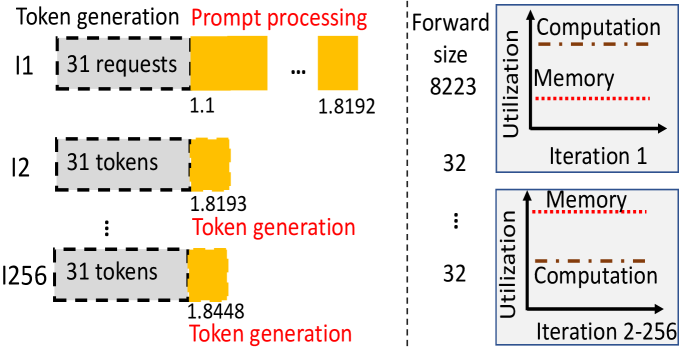
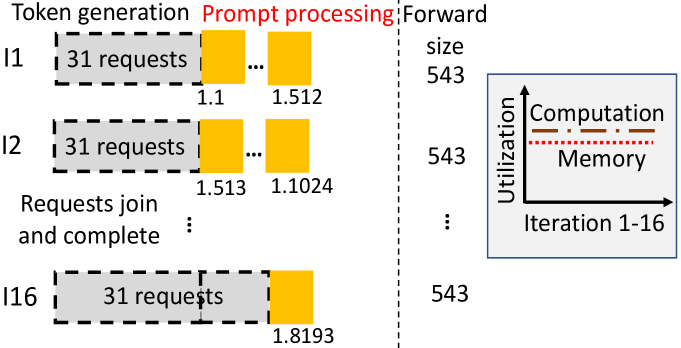
问题定义:论文旨在解决LLM推理服务系统中,同时存在长短提示请求以及不同应用对迭代时间有不同SLO需求时,如何保证高吞吐量并满足异构SLO的问题。现有方法在处理长提示时采用分块策略,但忽略了异构SLO,导致无法有效利用资源并满足所有应用的性能需求。
核心思路:AccelGen的核心思路是动态地调整分块大小,并根据迭代级别的SLO对请求进行优先级排序和批处理,从而在满足不同SLO需求的同时,最大化GPU计算资源和键值缓存的利用率。通过这种方式,系统能够更有效地处理混合提示场景,并为各种应用提供高性能的推理服务。
技术框架:AccelGen包含四个核心组件:SLO保证的动态分块、迭代级别SLO的任务优先级排序、多资源感知批处理以及一个整体的调度框架。动态分块模块根据SLO动态调整chunk大小;优先级排序模块根据SLO紧急程度对请求排序;多资源感知批处理模块同时考虑GPU计算和KVC利用率进行请求批处理。这些模块协同工作,共同优化LLM推理服务的性能。
关键创新:AccelGen的关键创新在于其综合考虑了异构SLO、动态分块和多资源感知批处理。与现有方法相比,AccelGen能够更精细地控制资源分配,从而在满足不同SLO需求的同时,最大化系统吞吐量和资源利用率。动态分块策略能够根据SLO自适应地调整计算负载,而多资源感知批处理则能够充分利用GPU计算和KVC资源,避免资源瓶颈。
关键设计:动态分块策略根据请求的SLO和当前系统的负载情况,动态调整chunk的大小。优先级排序模块使用加权轮询等算法,根据SLO的紧急程度对请求进行排序。多资源感知批处理模块使用启发式算法,选择能够最大化GPU计算和KVC利用率的请求进行批处理。具体的参数设置和算法选择需要根据实际的应用场景和系统配置进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,与现有最先进的方法相比,AccelGen实现了1.42-11.21倍更高的吞吐量,1.43-13.71倍更高的goodput,37-90%更高的SLO达成率,以及1.61-12.22倍更低的响应延迟。AccelGen的性能接近Oracle,表明其资源利用率已经接近最优。
🎯 应用场景
AccelGen适用于各种需要LLM推理服务的场景,例如智能客服、内容生成、代码生成等。特别是在需要同时处理长短文本,并对响应时间有不同要求的应用中,AccelGen能够提供更好的性能和用户体验。该研究有助于推动LLM在更多实际场景中的应用,并提升LLM推理服务的效率和质量。
📄 摘要(原文)
In this paper, we consider a mixed-prompt scenario for a large language model (LLM) inference serving system that supports diverse applications with both short prompts and long prompts and heterogeneous SLOs for iteration time. To improve throughput when handling long prompts, previous research introduces a chunking method, but has not addressed heterogeneous SLOs. To address the limitation, we propose AccelGen, a high-throughput LLM inference serving system with heterogeneous SLO guarantees for diverse applications. AccelGen introduces four core components: (1) SLO-guaranteed dynamic chunking, which dynamically adjusts chunk sizes to maximize GPU compute utilization while meeting iteration-level SLOs; (2) Iteration-level SLO-based task prioritization, which prioritizes tight-SLO requests and batches requests with similar SLOs; (3) Multi-resource-aware batching, which selects queued requests to maximize the utilizations of both GPU compute resource and key-value cache (KVC). Trace-driven real experiments demonstrate that AccelGen achieves 1.42-11.21X higher throughput, 1.43-13.71X higher goodput, 37-90% higher SLO attainment, and 1.61-12.22X lower response latency compared to the state-of-the-art approaches. It achieves performance near the Oracle, which optimally maximizes goodput.