A Multi-Stage Framework with Taxonomy-Guided Reasoning for Occupation Classification Using Large Language Models
作者: Palakorn Achananuparp, Ee-Peng Lim, Yao Lu
分类: cs.CL, cs.AI, cs.SI
发布日期: 2025-03-17 (更新: 2025-10-31)
备注: Accepted to ICWSM'26
💡 一句话要点
提出基于分类体系引导推理的多阶段框架,利用大语言模型进行职业分类
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 职业分类 大型语言模型 分类体系 多阶段框架 推理 检索 重排序
📋 核心要点
- 现有职业分类方法面临数据稀缺和人工标注困难,限制了劳动力市场分析的效率和准确性。
- 论文提出多阶段框架,通过分类体系引导推理,提升大语言模型在职业分类任务中的性能。
- 实验结果表明,该框架在职业和技能分类上表现出色,并能以较低成本媲美GPT-4o等先进模型。
📝 摘要(中文)
职业分类是使用标准化职业分类体系自动标注工作数据,对劳动力市场分析至关重要。然而,数据稀缺和手动标注的挑战阻碍了这项任务。大型语言模型(LLM)凭借其广泛的世界知识和上下文学习能力展现出潜力,但其有效性取决于对职业分类体系的知识,这仍然不清楚。本研究评估了LLM从分类体系中生成精确分类实体的能力,突出了其局限性,特别是对于较小的模型。为了应对这些挑战,我们提出了一个多阶段框架,包括推理、检索和重排序阶段,该框架集成了分类体系引导的推理示例,通过将输出与分类知识对齐来提高性能。在大规模数据集上的评估表明,我们的框架不仅增强了职业和技能分类任务,而且为GPT-4o等前沿模型提供了一种经济高效的替代方案,在保持强大性能的同时显著降低了计算成本。这使其成为跨LLM的职业分类和相关任务的实用且可扩展的解决方案。
🔬 方法详解
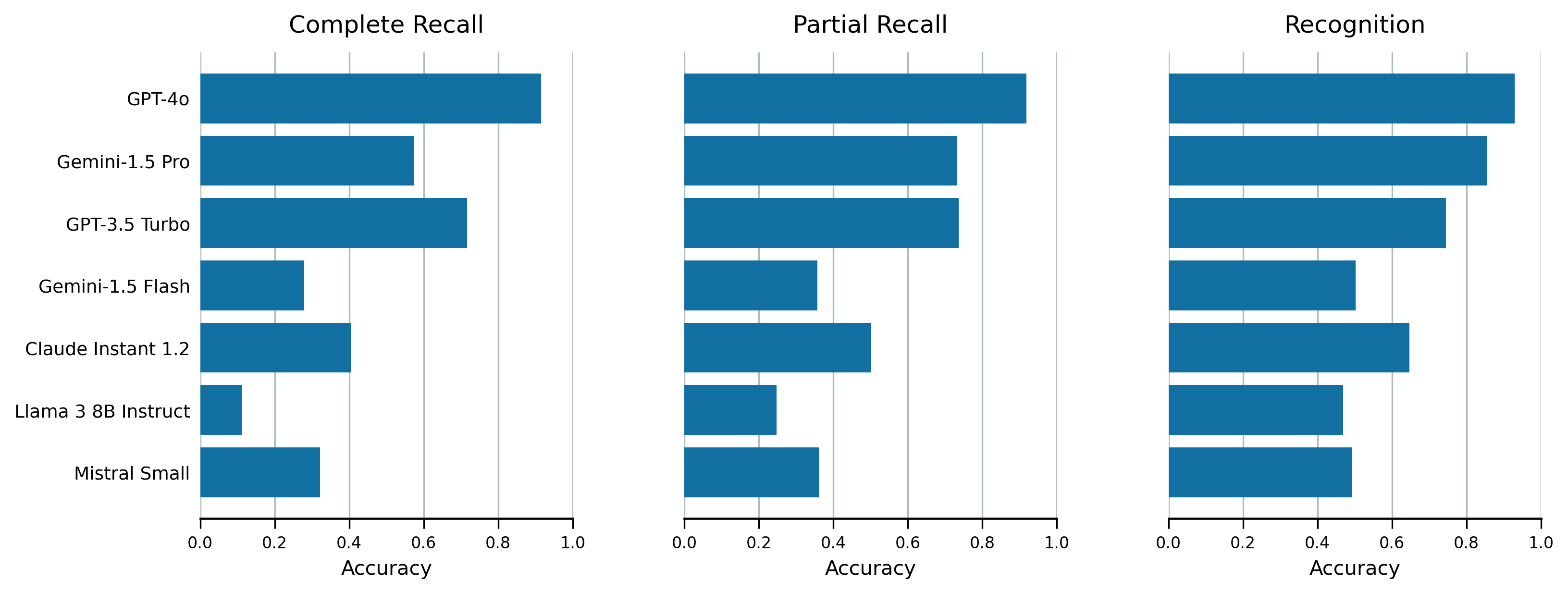
问题定义:论文旨在解决职业分类问题,即如何利用大型语言模型(LLM)自动地将工作数据与标准化的职业分类体系进行匹配。现有方法面临的痛点在于数据稀缺、人工标注成本高昂,以及LLM对特定职业分类体系知识的不足,导致分类精度不高。
核心思路:论文的核心思路是利用一个多阶段框架,通过分类体系引导的推理,增强LLM在职业分类任务中的表现。该框架旨在弥补LLM在职业分类体系知识上的不足,并提高分类的准确性和效率。通过引入分类体系的知识,引导LLM进行更精确的推理和分类。
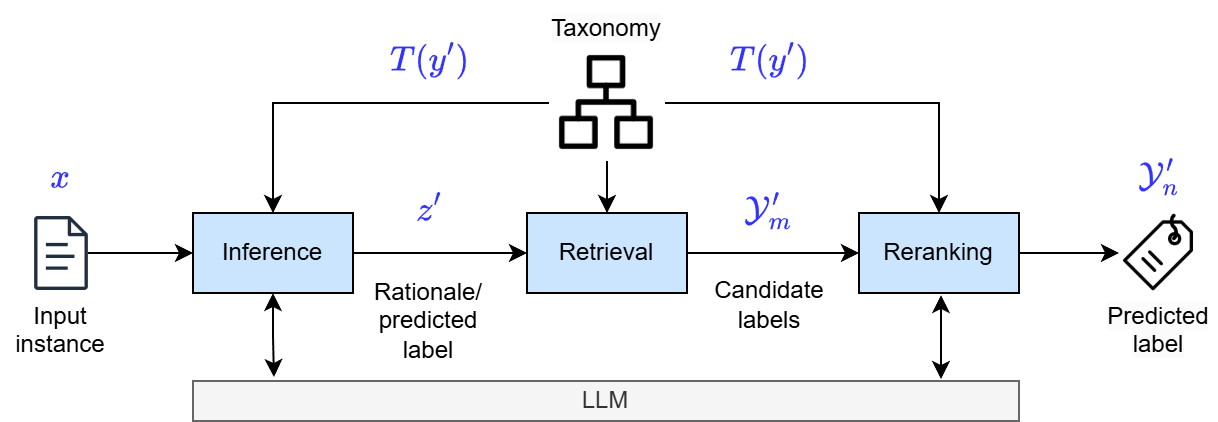
技术框架:该框架包含三个主要阶段:推理阶段、检索阶段和重排序阶段。在推理阶段,LLM基于输入的工作数据生成初步的职业分类结果。在检索阶段,系统从职业分类体系中检索与初步结果相关的条目。在重排序阶段,系统根据分类体系的知识和上下文信息,对检索到的条目进行重排序,选择最合适的职业分类结果。
关键创新:该框架的关键创新在于将分类体系的知识融入到LLM的推理过程中。通过分类体系引导的推理示例,框架能够更好地利用LLM的上下文学习能力,提高分类的准确性。此外,多阶段框架的设计允许系统逐步优化分类结果,从而提高整体性能。
关键设计:论文中关键的设计包括:1) 分类体系引导的推理示例的设计,这些示例用于指导LLM进行更精确的推理;2) 检索阶段的检索策略,用于从分类体系中检索相关的条目;3) 重排序阶段的重排序算法,用于根据分类体系的知识和上下文信息,选择最合适的职业分类结果。具体的参数设置、损失函数和网络结构等技术细节在论文中可能未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该框架在职业和技能分类任务上取得了显著的性能提升,并且能够以较低的计算成本媲美GPT-4o等前沿模型。该框架为使用LLM进行职业分类提供了一种经济高效且可扩展的解决方案,尤其适用于资源有限的场景。
🎯 应用场景
该研究成果可广泛应用于劳动力市场分析、招聘平台、职业规划咨询等领域。通过自动化的职业分类,可以更准确地分析劳动力市场的供需关系,提高招聘效率,为求职者提供更精准的职业建议。未来,该技术有望应用于更广泛的文本分类和知识图谱构建任务。
📄 摘要(原文)
Automatically annotating job data with standardized occupations from taxonomies, known as occupation classification, is crucial for labor market analysis. However, this task is often hindered by data scarcity and the challenges of manual annotations. While large language models (LLMs) hold promise due to their extensive world knowledge and in-context learning capabilities, their effectiveness depends on their knowledge of occupational taxonomies, which remains unclear. In this study, we assess the ability of LLMs to generate precise taxonomic entities from taxonomy, highlighting their limitations, especially for smaller models. To address these challenges, we propose a multi-stage framework consisting of inference, retrieval, and reranking stages, which integrates taxonomy-guided reasoning examples to enhance performance by aligning outputs with taxonomic knowledge. Evaluations on a large-scale dataset show that our framework not only enhances occupation and skill classification tasks, but also provides a cost-effective alternative to frontier models like GPT-4o, significantly reducing computational costs while maintaining strong performance. This makes it a practical and scalable solution for occupation classification and related tasks across LLMs.