TNCSE: Tensor's Norm Constraints for Unsupervised Contrastive Learning of Sentence Embeddings
作者: Tianyu Zong, Bingkang Shi, Hongzhu Yi, Jungang Xu
分类: cs.CL, cs.AI
发布日期: 2025-03-17
💡 一句话要点
提出TNCSE,通过约束张量范数进行无监督对比学习,提升句子嵌入表示
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 句子嵌入 无监督学习 对比学习 张量范数约束 语义文本相似度 自然语言处理 Transformer 集成学习
📋 核心要点
- 现有无监督句子嵌入方法忽略了句子嵌入作为张量的模长信息,仅关注方向,限制了表示能力。
- TNCSE通过约束正样本之间模长的特征,优化无监督对比学习,从而提升句子嵌入的质量。
- 实验表明,TNCSE在语义文本相似性任务和零样本评估中均取得了优于现有方法的结果,达到SOTA。
📝 摘要(中文)
无监督句子嵌入表示已成为自然语言处理领域的研究热点。作为张量,句子嵌入具有两个关键属性:方向和范数。现有工作仅限于约束样本表示的方向,而忽略了其模长的特征。为了解决这个问题,本文提出了一种新的训练目标,通过约束正样本之间模长的特征来优化无监督对比学习的训练。我们将张量范数约束的训练目标与集成学习相结合,提出了一个新的句子嵌入表示框架TNCSE。我们在七个语义文本相似性任务上进行了评估,结果表明TNCSE及其衍生模型是目前最先进的方法。此外,我们进行了广泛的零样本评估,结果表明TNCSE优于其他基线模型。
🔬 方法详解
问题定义:现有无监督句子嵌入方法主要关注句子嵌入向量的方向信息,而忽略了其模长(范数)所蕴含的语义信息。这种忽略导致模型无法充分利用句子嵌入的全部信息,从而限制了其表示能力,尤其是在语义相似度计算等任务中。现有方法的痛点在于缺乏对句子嵌入模长的有效约束,导致学习到的嵌入表示不够鲁棒和准确。
核心思路:本文的核心思路是,句子嵌入的模长也蕴含着重要的语义信息,应该被纳入到无监督对比学习的训练目标中。具体来说,正样本对(例如,同一个句子的不同数据增强版本)的嵌入向量,不仅应该在方向上相似,其模长也应该具有一定的相关性。通过约束正样本对嵌入向量的模长,可以促使模型学习到更全面、更准确的句子表示。
技术框架:TNCSE框架主要包含以下几个阶段:1) 数据增强:对输入句子进行数据增强,生成正样本对。2) 句子编码:使用预训练的Transformer模型(例如BERT)对句子进行编码,得到句子嵌入向量。3) 张量范数约束:计算正样本对嵌入向量的模长,并使用特定的损失函数(例如均方误差)约束它们之间的差异。4) 对比学习:使用对比学习损失函数(例如InfoNCE)约束正样本对嵌入向量在方向上的相似性,同时推开负样本。5) 集成学习:将多个TNCSE模型进行集成,进一步提升模型的鲁棒性和泛化能力。
关键创新:本文最重要的技术创新点在于提出了张量范数约束(Tensor's Norm Constraints)这一概念,并将其应用于无监督对比学习中。与现有方法只关注句子嵌入方向信息不同,TNCSE同时考虑了方向和模长信息,从而能够学习到更具表达力的句子嵌入。此外,将张量范数约束与集成学习相结合,进一步提升了模型的性能。
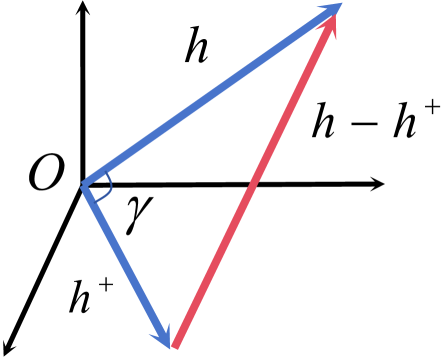
关键设计:在张量范数约束方面,论文使用了均方误差(MSE)作为损失函数,来约束正样本对嵌入向量模长之间的差异。具体来说,对于一个正样本对(x_i, x_i^+),其对应的嵌入向量为(v_i, v_i^+),则范数约束损失为L_norm = || ||v_i|| - ||v_i^+|| ||^2。在对比学习方面,论文使用了InfoNCE损失函数。在集成学习方面,论文采用了简单的平均集成策略,即将多个TNCSE模型输出的嵌入向量进行平均。
🖼️ 关键图片


📊 实验亮点
实验结果表明,TNCSE在七个语义文本相似性(STS)任务上取得了显著的性能提升,达到了当前最先进水平(SOTA)。例如,在STS Benchmark数据集上,TNCSE的Spearman相关系数超过了现有最佳模型。此外,在零样本评估中,TNCSE也优于其他基线模型,证明了其良好的泛化能力。
🎯 应用场景
TNCSE框架学习到的句子嵌入表示可以广泛应用于各种自然语言处理任务中,例如语义文本相似度计算、文本分类、信息检索、问答系统等。该方法尤其适用于缺乏标注数据的场景,可以有效提升模型的性能和泛化能力。未来,可以将TNCSE应用于跨语言句子嵌入学习、多模态句子嵌入学习等更复杂的问题。
📄 摘要(原文)
Unsupervised sentence embedding representation has become a hot research topic in natural language processing. As a tensor, sentence embedding has two critical properties: direction and norm. Existing works have been limited to constraining only the orientation of the samples' representations while ignoring the features of their module lengths. To address this issue, we propose a new training objective that optimizes the training of unsupervised contrastive learning by constraining the module length features between positive samples. We combine the training objective of Tensor's Norm Constraints with ensemble learning to propose a new Sentence Embedding representation framework, TNCSE. We evaluate seven semantic text similarity tasks, and the results show that TNCSE and derived models are the current state-of-the-art approach; in addition, we conduct extensive zero-shot evaluations, and the results show that TNCSE outperforms other baselines.