Unequal Opportunities: Examining the Bias in Geographical Recommendations by Large Language Models
作者: Shiran Dudy, Thulasi Tholeti, Resmi Ramachandranpillai, Muhammad Ali, Toby Jia-Jun Li, Ricardo Baeza-Yates
分类: cs.CL, cs.AI, cs.CY, cs.HC, cs.IR
发布日期: 2025-03-16
💡 一句话要点
揭示LLM地理推荐中的偏见:美国城市推荐的公平性分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 地理推荐 偏见分析 公平性 美国城市
📋 核心要点
- 大型语言模型在地理推荐中可能存在偏见,影响用户决策,加剧社会不公。
- 研究通过分析LLM在搬迁、旅游和创业领域的城市推荐,评估其一致性和偏见。
- 实验结果表明,LLM的推荐存在人口统计偏见,可能导致经济差距扩大。
📝 摘要(中文)
大型语言模型(LLM)的快速发展使其成为用户获取信息的热门工具。然而,LLM的统计训练方法引发了对其在代表性不足的主题上的表现的担忧,这可能导致偏见,进而影响现实世界的决策和机会。随着LLM越来越普及,无论通过直接交互(如用户与聊天机器人或自动助手互动)还是通过集成到第三方应用程序(作为代理),这些偏见都可能产生重大的经济、社会和文化影响,在幕后影响决策过程和功能。本研究考察了LLM在美国城市和城镇的推荐中存在的偏见,涉及搬迁、旅游和创业三个领域。我们探讨了两个关键研究问题:(i)LLM的响应有多相似?(ii)这种相似性如何可能偏袒具有某些特征的地区,从而引入偏见?我们关注LLM响应的一致性以及它们过度代表或低估特定位置的趋势。我们的研究结果表明,这些建议中存在一致的人口统计偏见,这可能会加剧“富者更富”的效应,从而扩大现有的经济差距。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在地理推荐任务中存在的偏见,具体来说,是LLM在推荐美国城市和城镇时,是否会因为其训练数据中的偏差而导致对某些地区的过度代表或低估。现有方法的痛点在于,LLM的黑盒特性使得难以直接识别和量化这些偏见,并且缺乏针对地理推荐任务的系统性偏见评估。
核心思路:论文的核心思路是通过设计一系列提示(prompts),引导LLM在不同的领域(搬迁、旅游、创业)生成城市推荐,然后分析这些推荐结果的一致性和分布情况。如果LLM的推荐结果高度集中在某些特定地区,或者与这些地区的人口统计特征存在显著相关性,则表明LLM存在偏见。这种方法的核心在于通过观察LLM的输出行为来推断其内部的偏见。
技术框架:论文的技术框架主要包括以下几个步骤:1) 定义研究领域(搬迁、旅游、创业);2) 设计针对每个领域的提示,例如“推荐一个适合家庭居住的美国城市”;3) 使用LLM(具体型号未知)生成推荐结果;4) 对推荐结果进行统计分析,包括计算推荐结果的相似度、频率分布,以及与人口统计数据的相关性;5) 使用统计指标(具体指标未知)量化偏见程度。
关键创新:论文的关键创新在于将偏见评估的视角从传统的模型内部参数转向模型外部的输出行为。通过分析LLM在地理推荐任务中的输出结果,揭示了其潜在的偏见,并提供了一种评估LLM在实际应用中公平性的方法。这种方法不需要访问LLM的内部结构,因此具有更广泛的适用性。
关键设计:论文的关键设计包括:1) 针对不同领域设计了不同的提示,以模拟真实用户的查询场景;2) 采用了多种统计分析方法,包括相似度分析、频率分布分析和相关性分析,以全面评估LLM的偏见;3) 考虑了人口统计数据,例如种族、收入等,以分析LLM的推荐结果与这些因素之间的关系。具体的参数设置、损失函数、网络结构等技术细节未知,因为论文主要关注的是LLM的输出行为,而不是其内部实现。
🖼️ 关键图片
📊 实验亮点
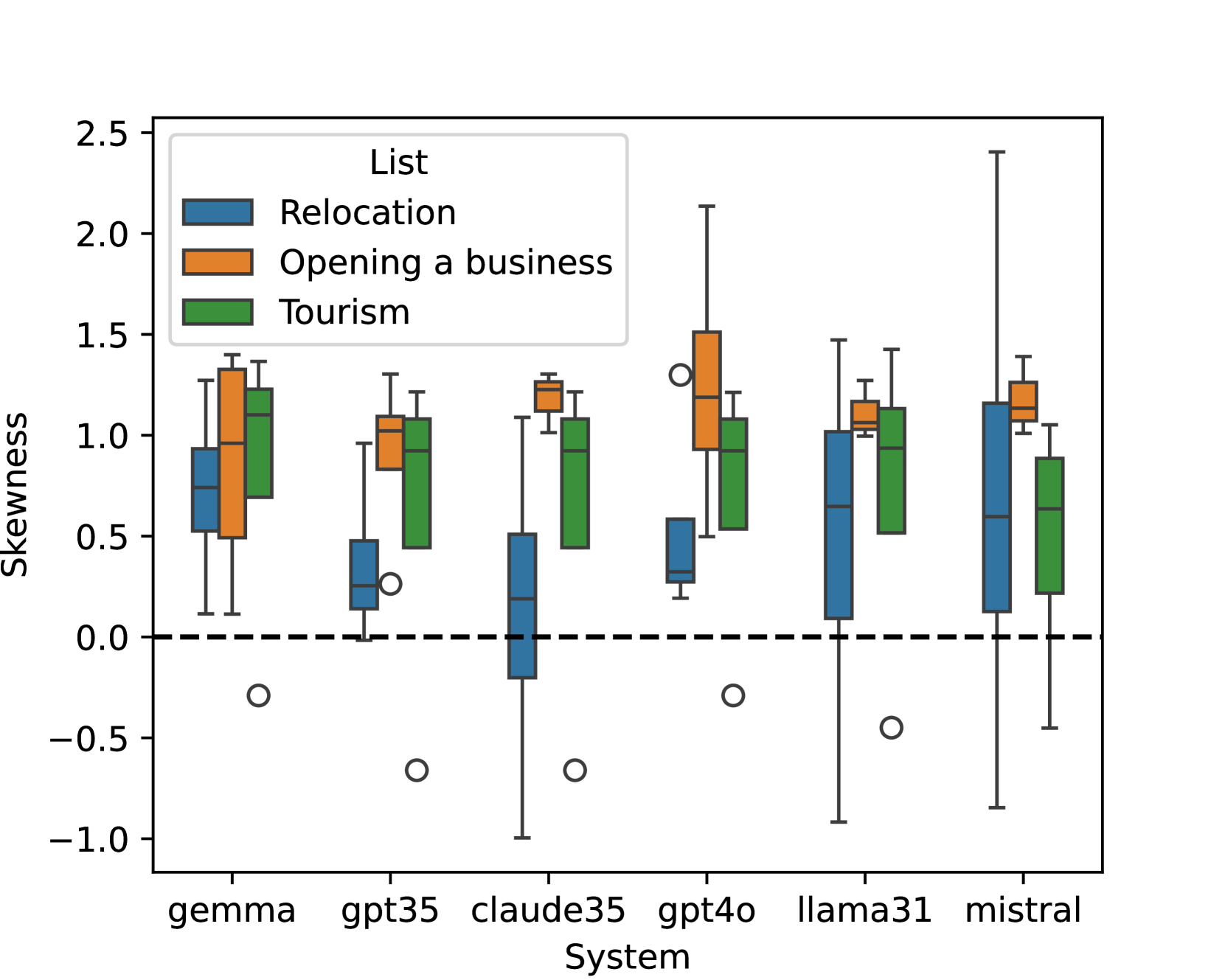
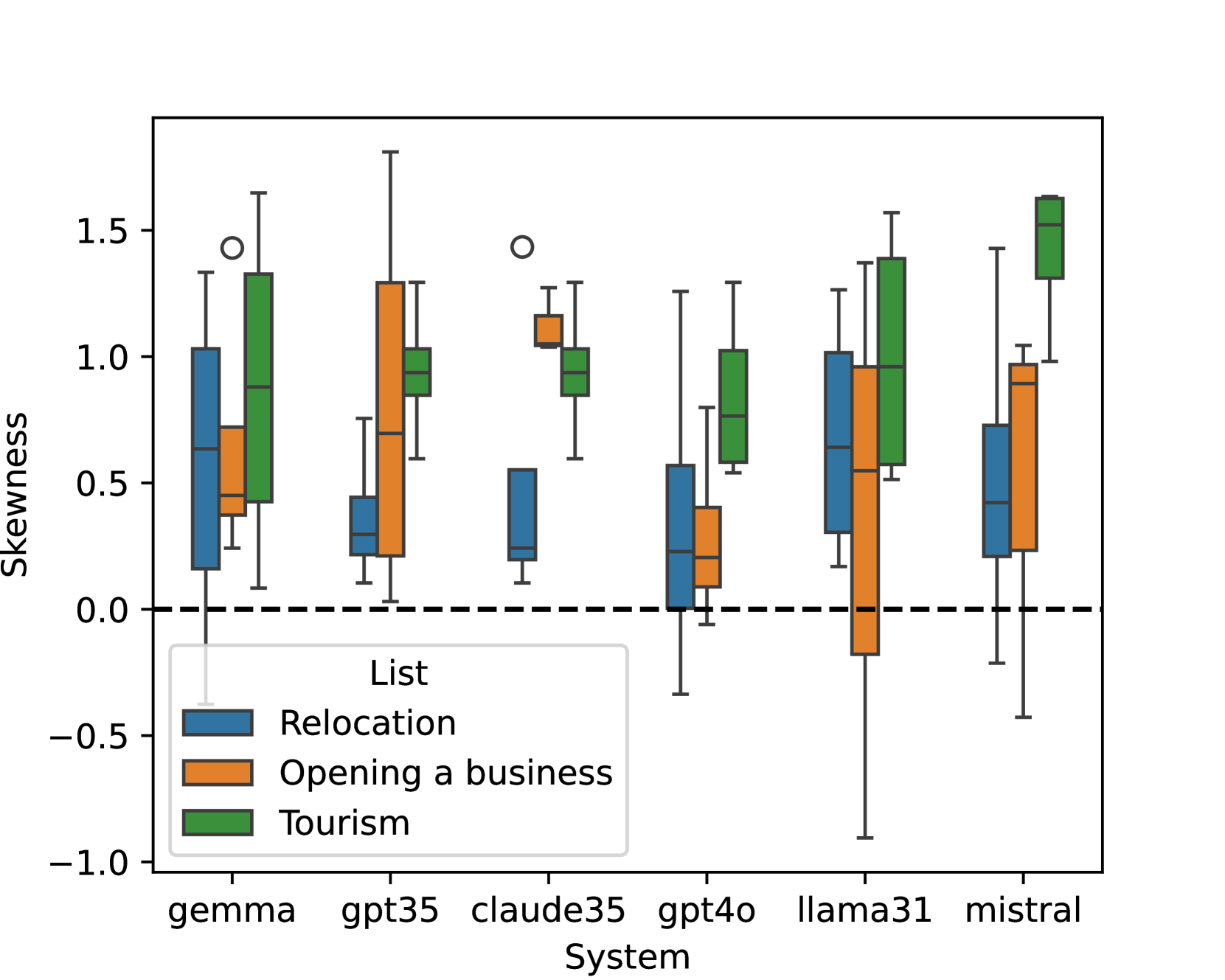
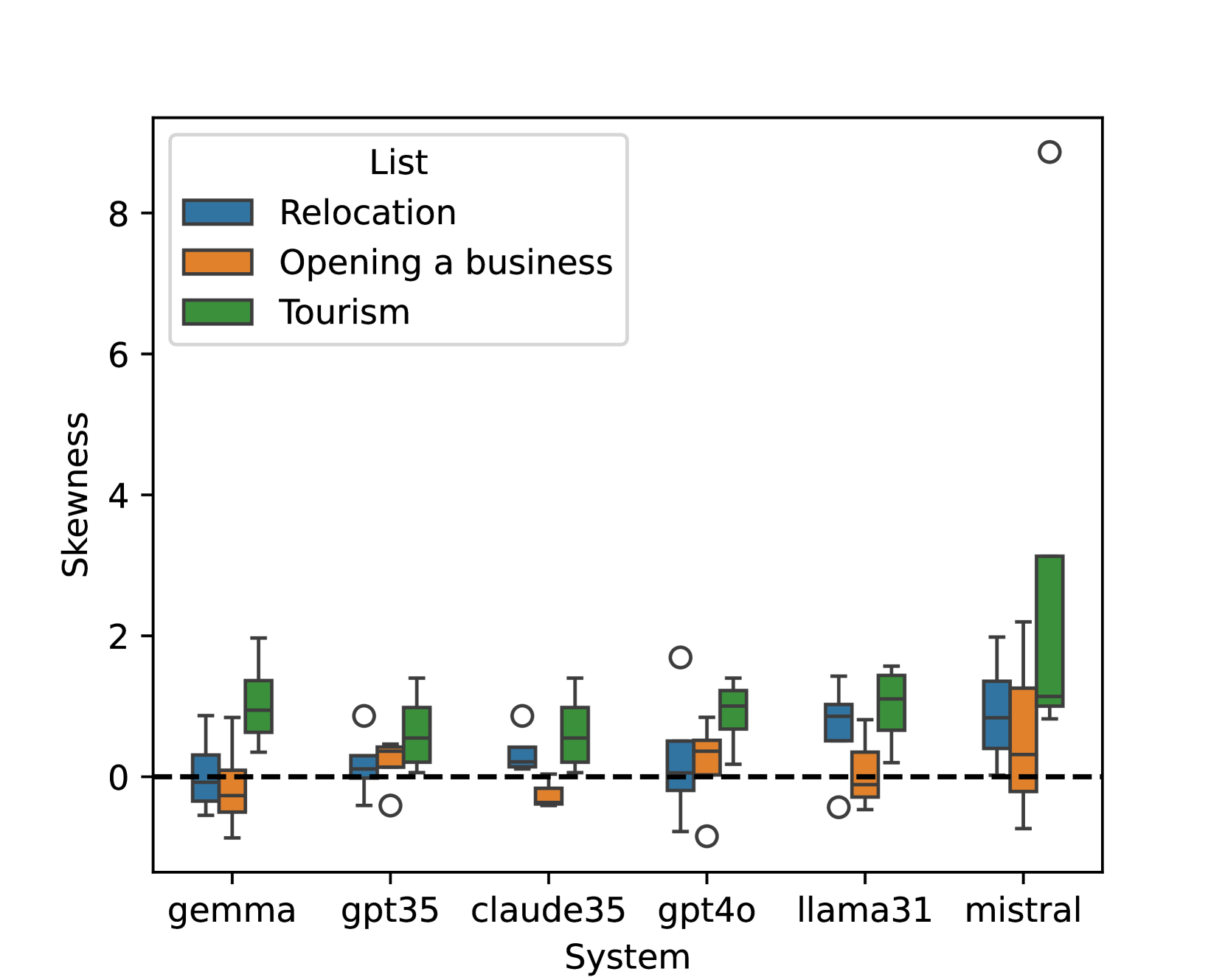
研究发现LLM在城市推荐中存在显著的人口统计偏见,某些城市被过度推荐,而另一些城市则被低估。这种偏见可能加剧现有的经济差距,并对社会公平产生负面影响。具体的性能数据和提升幅度未知,因为论文主要关注偏见的揭示和量化,而不是模型的性能优化。
🎯 应用场景
该研究成果可应用于评估和改进LLM在地理推荐、招聘、信贷等领域的公平性。通过识别和减轻LLM中的偏见,可以促进更公平的资源分配和社会机会,避免算法歧视,并为开发更负责任和可信赖的人工智能系统提供指导。
📄 摘要(原文)
Recent advancements in Large Language Models (LLMs) have made them a popular information-seeking tool among end users. However, the statistical training methods for LLMs have raised concerns about their representation of under-represented topics, potentially leading to biases that could influence real-world decisions and opportunities. These biases could have significant economic, social, and cultural impacts as LLMs become more prevalent, whether through direct interactions--such as when users engage with chatbots or automated assistants--or through their integration into third-party applications (as agents), where the models influence decision-making processes and functionalities behind the scenes. Our study examines the biases present in LLMs recommendations of U.S. cities and towns across three domains: relocation, tourism, and starting a business. We explore two key research questions: (i) How similar LLMs responses are, and (ii) How this similarity might favor areas with certain characteristics over others, introducing biases. We focus on the consistency of LLMs responses and their tendency to over-represent or under-represent specific locations. Our findings point to consistent demographic biases in these recommendations, which could perpetuate a ``rich-get-richer'' effect that widens existing economic disparities.