Towards Hierarchical Multi-Step Reward Models for Enhanced Reasoning in Large Language Models
作者: Teng Wang, Zhangyi Jiang, Zhenqi He, Shenyang Tong, Wenhan Yang, Yanan Zheng, Zeyu Li, Zifan He, Hailei Gong, Zewen Ye, Shengjie Ma, Jianping Zhang
分类: cs.CL, cs.AI
发布日期: 2025-03-16 (更新: 2025-10-26)
💡 一句话要点
提出层级奖励模型(HRM)与层级节点压缩(HNC)策略,提升LLM推理能力并降低数据标注成本。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 奖励模型 层级奖励模型 推理能力 数据增强 蒙特卡洛树搜索 过程奖励模型
📋 核心要点
- 现有过程奖励模型(PRM)存在奖励利用问题,难以准确识别最佳中间步骤,且推理过程标注成本高昂。
- 提出层级奖励模型(HRM),在不同粒度评估推理步骤,擅长评估多步推理连贯性,尤其是在自我反思纠错时。
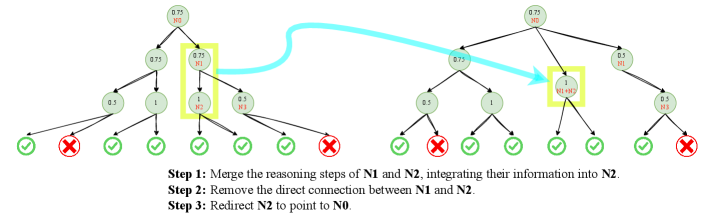
- 引入层级节点压缩(HNC)策略,合并推理步骤,增强训练数据多样性与鲁棒性,降低数据标注成本,提升模型泛化能力。
📝 摘要(中文)
本文提出了一种新的奖励模型方法,即层级奖励模型(HRM),它在细粒度和粗粒度级别评估单个和连续的推理步骤。HRM擅长评估多步推理连贯性,尤其是在有缺陷的步骤后来通过自我反思得到纠正时。为了进一步降低生成训练数据的成本,我们引入了一种轻量级且有效的数据增强策略,称为层级节点压缩(HNC),它将树结构中的两个连续推理步骤合并为一个。通过将HNC应用于MCTS生成的推理轨迹,我们增强了HRM训练数据的多样性和鲁棒性,同时以最小的计算开销引入了可控噪声。在PRM800K数据集上的实验结果表明,HRM与HNC相结合,提供了比PRM更稳定和可靠的评估。此外,在MATH500和GSM8K数据集上的跨域评估证明了HRM在各种推理任务中的强大泛化能力和鲁棒性。
🔬 方法详解
问题定义:现有的大语言模型通过监督微调或强化学习展现出强大的推理能力。然而,过程奖励模型(PRM)容易受到奖励利用(reward hacking)的影响,导致其在识别最佳中间步骤时不可靠。此外,为奖励建模标注推理过程的成本很高,使得大规模收集高质量数据成为一项挑战。
核心思路:本文的核心思路是构建一个层级的奖励模型,从不同粒度评估推理过程中的步骤,从而更准确地评估推理的连贯性和正确性。同时,通过数据增强策略降低数据标注成本,提升模型的泛化能力。这样设计的目的是为了解决PRM的奖励利用问题,并降低训练数据的获取成本。
技术框架:整体框架包含两个主要部分:层级奖励模型(HRM)和层级节点压缩(HNC)。HRM对推理过程中的单个步骤和连续步骤进行细粒度和粗粒度的评估。HNC则是一种数据增强策略,通过合并树结构中的连续推理步骤来增加数据的多样性。训练数据通过蒙特卡洛树搜索(MCTS)生成推理轨迹,然后应用HNC进行数据增强,最后用于训练HRM。
关键创新:最重要的创新点在于提出了层级奖励模型(HRM)和层级节点压缩(HNC)相结合的方法。HRM通过分层评估推理步骤,能够更准确地捕捉推理过程中的细微差别和连贯性,从而避免了PRM的奖励利用问题。HNC则通过一种轻量级的方式增加了训练数据的多样性,降低了数据标注成本。与现有方法相比,该方法在奖励建模的准确性和数据获取的效率上都有显著提升。
关键设计:HRM的关键设计在于其层级结构,包括细粒度和粗粒度的评估。细粒度评估关注单个推理步骤的正确性,而粗粒度评估则关注连续步骤之间的连贯性。HNC的关键设计在于如何选择合并哪些推理步骤,以及如何控制引入的噪声。论文中使用了MCTS生成推理轨迹,并采用一定的策略来选择合并的节点,以保证数据增强的有效性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HRM与HNC相结合在PRM800K数据集上提供了比PRM更稳定和可靠的评估。在MATH500和GSM8K数据集上的跨域评估证明了HRM在各种推理任务中的强大泛化能力和鲁棒性。具体性能数据未知,但结论表明HRM优于PRM。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的场景,例如数学问题求解、代码生成、知识图谱推理等。通过提升大语言模型的推理能力和降低数据标注成本,可以加速这些技术在实际应用中的落地,并推动人工智能技术的发展。
📄 摘要(原文)
Recent studies show that Large Language Models (LLMs) achieve strong reasoning capabilities through supervised fine-tuning or reinforcement learning. However, a key approach, the Process Reward Model (PRM), suffers from reward hacking, making it unreliable in identifying the best intermediate step. In addition, the cost of annotating reasoning processes for reward modeling is high, making large-scale collection of high-quality data challenging. To address this, we propose a novel reward model approach called the Hierarchical Reward Model (HRM), which evaluates both individual and consecutive reasoning steps at both fine-grained and coarse-grained levels. HRM excels at assessing multi-step reasoning coherence, especially when flawed steps are later corrected through self-reflection. To further reduce the cost of generating training data, we introduce a lightweight and effective data augmentation strategy called Hierarchical Node Compression (HNC), which merges two consecutive reasoning steps into one within the tree structure. By applying HNC to MCTS-generated reasoning trajectories, we enhance the diversity and robustness of HRM training data while introducing controlled noise with minimal computational overhead. Empirical results on the PRM800K dataset show that HRM, together with HNC, provides more stable and reliable evaluations than PRM. Furthermore, cross-domain evaluations on the MATH500 and GSM8K datasets demonstrate HRM's strong generalization and robustness across a variety of reasoning tasks.