From Guessing to Asking: An Approach to Resolving the Persona Knowledge Gap in LLMs during Multi-Turn Conversations
作者: Sarvesh Baskar, Tanmay Tulsidas Verelakar, Srinivasan Parthasarathy, Manas Gaur
分类: cs.CL, cs.AI
发布日期: 2025-03-16
备注: 12 pages, 1 Figure, Oral Presentation at NAACL 2025
💡 一句话要点
CPER框架通过动态检测和修正知识差距,提升LLM多轮对话中的个性化和连贯性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多轮对话 大型语言模型 个性化推荐 知识差距 动态反馈
📋 核心要点
- 现有LLM在多轮对话中难以保持连贯性和个性化,主要原因是模型存在“人物知识差距”,即对用户信息的理解不足。
- 论文提出CPER框架,通过动态检测和修正LLM中的人物知识差距,从而提升对话的连贯性和个性化程度。
- 实验结果表明,CPER在电影推荐和心理健康支持对话中,显著优于基线模型,尤其在长对话中表现更佳。
📝 摘要(中文)
大型语言模型(LLM)在多轮对话中面临着确保连贯性并适应用户特定信息的关键挑战。本研究提出了“人物知识差距”的概念,即模型内部理解与连贯、个性化对话所需的知识之间的差异。虽然先前的研究已经认识到这些差距,但用于识别和解决这些差距的计算方法仍未得到充分探索。我们提出了对话偏好启发和推荐(CPER),这是一个新颖的框架,它使用内在不确定性量化和反馈驱动的细化来动态检测和解决人物知识差距。CPER由三个关键模块组成:用于偏好提取的上下文理解模块、用于测量不确定性和细化人物对齐的动态反馈模块,以及用于基于累积的用户上下文调整响应的人物驱动的响应生成模块。我们在两个真实世界的数据集上评估了CPER:用于偏好电影推荐的CCPE-M和用于心理健康支持的ESConv。通过A/B测试,人类评估者在CCPE-M中更喜欢CPER的响应42%,在ESConv中更喜欢27%。定性的人工评估证实,CPER的响应在保持上下文相关性和连贯性方面更受欢迎,尤其是在较长(12+轮)的对话中。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在多轮对话中存在的“人物知识差距”问题。现有方法难以充分理解和利用用户个性化信息,导致对话缺乏连贯性和相关性。模型无法有效追踪和整合用户在对话中表达的偏好和背景知识,从而影响对话质量。
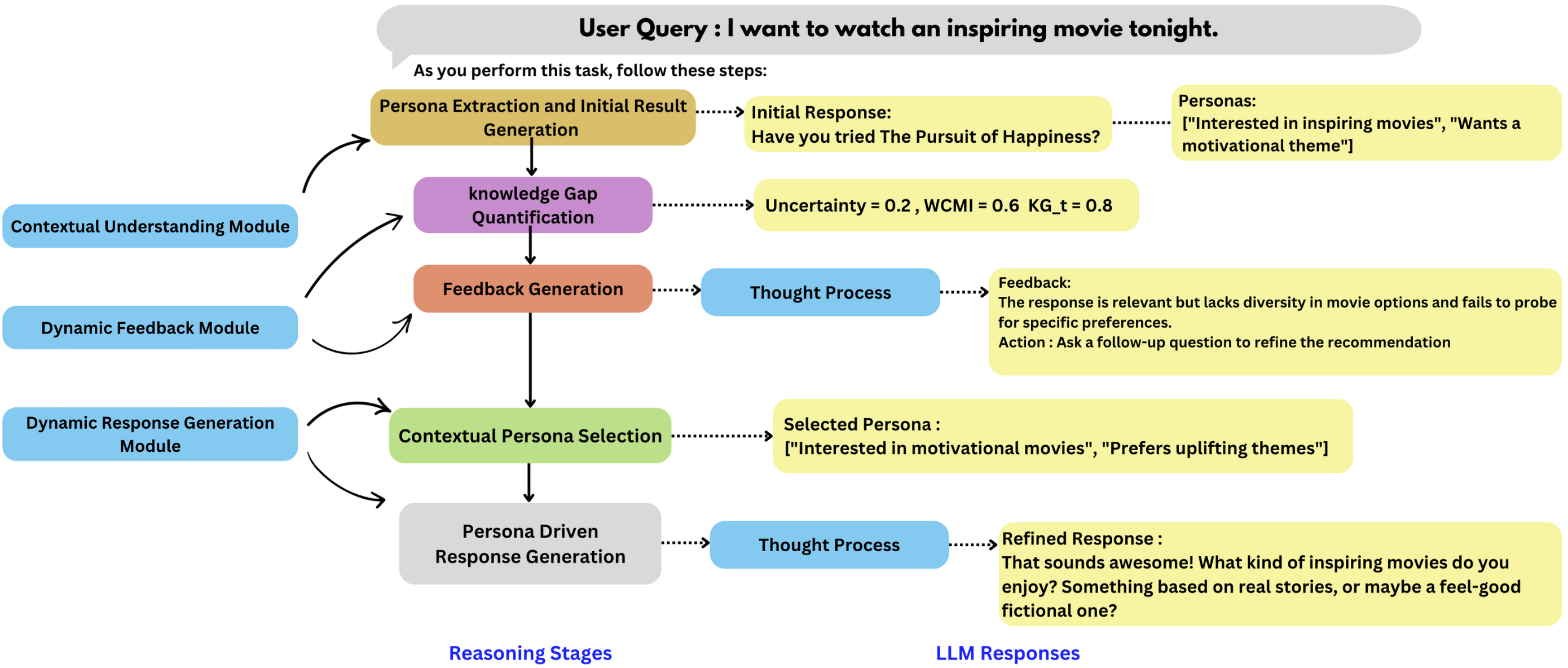
核心思路:CPER的核心思路是通过主动询问和动态反馈来弥补LLM的知识差距。模型不再是被动地猜测用户偏好,而是主动通过提问来获取信息,并根据用户的反馈不断修正自身的人物画像。这种主动学习的方式能够更准确地捕捉用户的真实意图,从而生成更个性化和连贯的回复。
技术框架:CPER框架包含三个主要模块:1) 上下文理解模块:负责从对话历史中提取用户偏好和相关信息。2) 动态反馈模块:用于量化模型对用户偏好的不确定性,并根据用户的反馈(例如,用户对推荐的满意度)来调整人物画像。3) 人物驱动的响应生成模块:基于更新后的人物画像生成回复,力求更贴合用户的需求和偏好。整体流程是,上下文理解模块提取信息,动态反馈模块评估不确定性并更新人物画像,最后响应生成模块生成回复。
关键创新:CPER的关键创新在于其动态反馈机制和主动提问策略。传统的对话系统通常依赖于预定义的规则或静态的人物画像,而CPER能够根据用户的实时反馈进行调整,从而更好地适应用户的变化。主动提问策略则允许模型主动获取缺失的信息,而不是被动地等待用户提供。
关键设计:动态反馈模块使用不确定性量化方法来评估模型对用户偏好的理解程度。具体的不确定性度量方法和反馈机制(例如,用户评分、显式反馈)在论文中可能有所描述,但具体细节未知。人物驱动的响应生成模块可能使用了某种形式的条件生成模型,例如,基于Transformer的模型,以人物画像作为条件来生成回复。损失函数的设计可能包括最大化回复与用户偏好的相关性,并最小化不确定性。
🖼️ 关键图片
📊 实验亮点
实验结果显示,在CCPE-M电影推荐数据集上,人类评估者更喜欢CPER生成的回复的比例比基线模型高42%。在ESConv心理健康支持数据集上,这一比例为27%。这表明CPER在提升对话的连贯性和个性化方面具有显著优势,尤其是在长对话中效果更明显。
🎯 应用场景
CPER框架可应用于各种需要个性化对话的场景,例如智能客服、虚拟助手、推荐系统和教育辅导。通过更准确地理解用户需求和偏好,CPER能够提供更贴心、高效的服务,提升用户体验。未来,该技术有望在医疗健康、金融服务等领域发挥重要作用。
📄 摘要(原文)
In multi-turn dialogues, large language models (LLM) face a critical challenge of ensuring coherence while adapting to user-specific information. This study introduces the persona knowledge gap, the discrepancy between a model's internal understanding and the knowledge required for coherent, personalized conversations. While prior research has recognized these gaps, computational methods for their identification and resolution remain underexplored. We propose Conversation Preference Elicitation and Recommendation (CPER), a novel framework that dynamically detects and resolves persona knowledge gaps using intrinsic uncertainty quantification and feedback-driven refinement. CPER consists of three key modules: a Contextual Understanding Module for preference extraction, a Dynamic Feedback Module for measuring uncertainty and refining persona alignment, and a Persona-Driven Response Generation module for adapting responses based on accumulated user context. We evaluate CPER on two real-world datasets: CCPE-M for preferential movie recommendations and ESConv for mental health support. Using A/B testing, human evaluators preferred CPER's responses 42% more often than baseline models in CCPE-M and 27% more often in ESConv. A qualitative human evaluation confirms that CPER's responses are preferred for maintaining contextual relevance and coherence, particularly in longer (12+ turn) conversations.