Interpretation Gaps in LLM-Assisted Comprehension of Privacy Documents
作者: Rinku Dewri
分类: cs.CL, cs.CY, cs.IR
发布日期: 2025-03-15 (更新: 2025-08-30)
备注: Minor revision
期刊: IEEE Computer, 58:9, pp. 70-79, 2025
💡 一句话要点
揭示LLM辅助理解隐私政策时存在的解释偏差问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 隐私政策 自然语言理解 偏差分析 合规性检查
📋 核心要点
- 现有方法难以准确、完整地解释复杂隐私政策,导致用户难以理解自身数据权利。
- 利用LLM简化隐私政策解释,旨在帮助用户更好地理解数据实践,并实现自动化合规性检查。
- 通过实例分析,揭示了LLM在解释隐私政策时存在的准确性、完整性、清晰度和表示偏差问题。
📝 摘要(中文)
本文探讨了使用大型语言模型(LLM)从复杂的隐私政策中获取简化的数据实践解释时可能出现的偏差。通过具体实例展示了LLM在准确性、完整性、清晰度和表示方面的问题。同时,倡导继续深入研究,以充分发挥LLM在通过个人助理和自动化合规性检查彻底改变隐私管理方面的真正潜力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在理解和解释复杂隐私政策时存在的偏差问题。现有方法,即直接使用LLM进行隐私政策的简化和解释,存在准确性不足、信息不完整、表达不清晰以及表示偏差等痛点,导致用户难以真正理解隐私政策的内容和含义。
核心思路:论文的核心思路是通过实例分析,揭示LLM在解释隐私政策时可能出现的各种偏差类型,从而强调现有方法的局限性。通过具体案例,展示LLM可能错误地解释、遗漏关键信息、使用户产生误解,或者在表示方式上存在偏差。
技术框架:该论文本质上是一个案例研究,没有提出新的技术框架。其研究流程主要包括:1) 选择具有代表性的隐私政策文本;2) 使用LLM对这些文本进行简化和解释;3) 人工分析LLM的输出结果,识别其中存在的偏差;4) 对偏差进行分类,例如准确性偏差、完整性偏差、清晰度偏差和表示偏差。
关键创新:该论文的创新点在于,它通过实证分析揭示了LLM在隐私政策理解和解释方面存在的潜在问题。虽然LLM在自然语言处理方面取得了显著进展,但该研究表明,直接将其应用于复杂文档的理解和解释时,仍然需要谨慎对待,并需要进一步的研究和改进。
关键设计:由于该论文主要是一个案例研究,因此没有涉及具体的参数设置、损失函数或网络结构等技术细节。其关键在于选择合适的隐私政策文本,以及设计合理的分析框架来识别和分类LLM的输出偏差。
🖼️ 关键图片
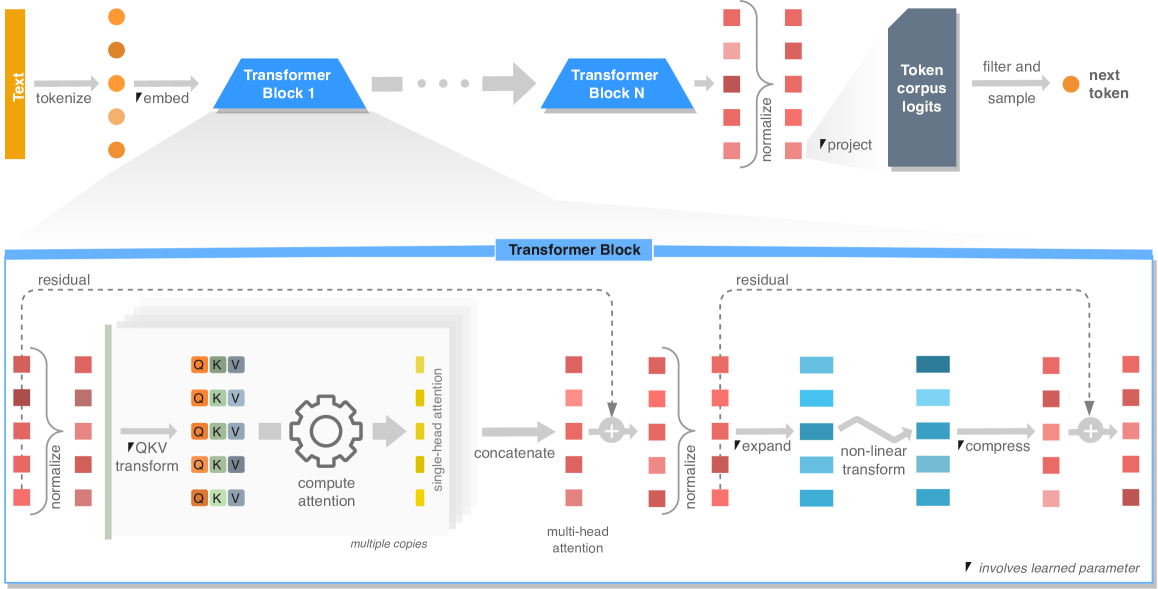
📊 实验亮点
论文通过具体案例揭示了LLM在解释隐私政策时存在的四类偏差:准确性偏差(错误解释)、完整性偏差(遗漏信息)、清晰度偏差(表达模糊)和表示偏差(产生误解)。这些发现强调了当前LLM在处理复杂法律文本时的局限性,并为未来的研究方向提供了指导。
🎯 应用场景
该研究结果可应用于开发更可靠的隐私助手和自动化合规检查工具。通过了解LLM在隐私政策理解方面的局限性,可以设计更有效的提示工程方法,或开发专门针对隐私政策理解的LLM微调技术,从而提升用户对自身数据权利的认知,并促进企业合规。
📄 摘要(原文)
This article explores the gaps that can manifest when using a large language model (LLM) to obtain simplified interpretations of data practices from a complex privacy policy. We exemplify these gaps to showcase issues in accuracy, completeness, clarity and representation, while advocating for continued research to realize an LLM's true potential in revolutionizing privacy management through personal assistants and automated compliance checking.