PLM: Efficient Peripheral Language Models Hardware-Co-Designed for Ubiquitous Computing
作者: Cheng Deng, Luoyang Sun, Jiwen Jiang, Yongcheng Zeng, Xinjian Wu, Wenxin Zhao, Qingfa Xiao, Jiachuan Wang, Haoyang Li, Lei Chen, Lionel M. Ni, Haifeng Zhang, Jun Wang
分类: cs.CL
发布日期: 2025-03-15 (更新: 2025-03-19)
🔗 代码/项目: GITHUB
💡 一句话要点
面向普适计算,提出高效的周边语言模型硬件协同设计PLM
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 边缘计算 语言模型 模型压缩 硬件协同设计 多头注意力 强化学习 边缘智能 资源效率
📋 核心要点
- 现有小型语言模型虽然减小了模型尺寸,但仍沿用大型模型的架构,对边缘设备的存储和带宽造成压力。
- PLM通过协同设计优化模型架构和边缘系统约束,利用多头潜在注意力和平方ReLU激活函数减少内存占用。
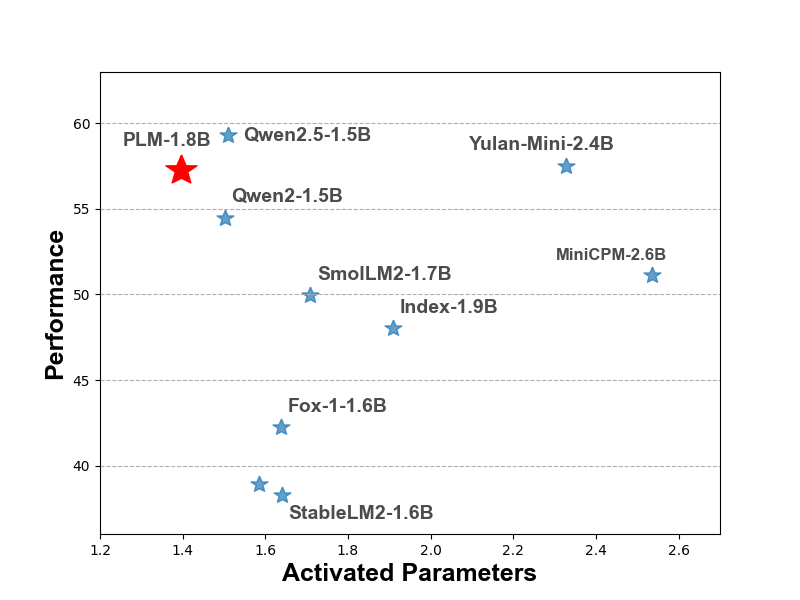
- 实验表明,PLM在保持最低激活参数数量的同时,性能优于现有小型语言模型,并成功部署在多种边缘设备上。
📝 摘要(中文)
随着模型参数的增加,大型语言模型(LLM)的扩展法则不断得到验证,但LLM的推理需求与边缘设备有限的资源之间的内在矛盾,对边缘智能的发展提出了严峻的挑战。最近,涌现出许多小型语言模型,旨在将LLM的能力提炼到更小的模型中。然而,这些模型通常保留了其较大模型的架构原则,仍然对边缘设备的存储和带宽容量造成相当大的压力。本文介绍了一种周边语言模型PLM,通过协同设计过程开发,共同优化模型架构和边缘系统约束。PLM利用多头潜在注意力机制,并采用平方ReLU激活函数来鼓励稀疏性,从而减少推理期间的峰值内存占用。在训练过程中,我们收集并重组开源数据集,实施多阶段训练策略,并实证研究了Warmup-Stable-Decay-Constant (WSDC)学习率调度器。此外,我们通过采用ARIES偏好学习方法,融入了来自人类反馈的强化学习(RLHF)。经过两阶段的SFT过程,该方法在通用任务中产生了2%的性能提升,在GSM8K任务中产生了9%的性能提升,在编码任务中产生了11%的性能提升。除了其新颖的架构外,评估结果表明,PLM在公开数据上训练时,优于现有的小型语言模型,同时保持了最低的激活参数数量。此外,在各种边缘设备(包括消费级GPU、手机和Raspberry Pi)上的部署验证了PLM对周边应用的适用性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在边缘设备上部署时面临的资源限制问题。现有的小型语言模型虽然减小了模型尺寸,但仍然继承了大型模型的架构,导致在存储、带宽和计算资源受限的边缘设备上部署时效率低下。因此,需要一种专门为边缘设备设计的、资源效率更高的语言模型。
核心思路:论文的核心思路是通过模型架构和硬件的协同设计,创建一个资源效率高的周边语言模型(PLM)。通过优化模型结构,减少内存占用和计算复杂度,同时考虑边缘设备的硬件约束,使模型能够高效地在边缘设备上运行。这种协同设计的目标是在保持甚至提高模型性能的同时,显著降低资源消耗。
技术框架:PLM的整体框架包括以下几个主要部分:1) 数据集的收集和重组;2) 模型架构的设计,包括多头潜在注意力机制和平方ReLU激活函数;3) 多阶段训练策略,包括Warmup-Stable-Decay-Constant (WSDC)学习率调度器;4) 通过ARIES偏好学习方法融入来自人类反馈的强化学习(RLHF);5) 在各种边缘设备上进行部署和评估。
关键创新:PLM的关键创新在于其协同设计方法和特定的模型架构。多头潜在注意力机制旨在减少计算复杂度,而平方ReLU激活函数则鼓励模型产生稀疏性,从而降低内存占用。此外,多阶段训练策略和RLHF的结合进一步提升了模型性能。与现有方法相比,PLM更加注重边缘设备的资源约束,通过协同优化模型和硬件,实现了更高的资源效率。
关键设计:PLM的关键设计包括:1) 多头潜在注意力机制的具体实现方式,例如注意力头数、潜在空间的维度等;2) 平方ReLU激活函数的具体形式和参数设置;3) WSDC学习率调度器的参数设置,例如warmup阶段的长度、stable阶段的长度、decay的速率等;4) ARIES偏好学习方法的具体实现细节,例如奖励函数的设计、训练数据的选择等。
🖼️ 关键图片


📊 实验亮点
PLM在多个任务上取得了显著的性能提升。在通用任务中,PLM的性能提升了2%;在GSM8K任务中,性能提升了9%;在编码任务中,性能提升了11%。此外,PLM在保持最低激活参数数量的同时,优于在公开数据上训练的现有小型语言模型。在消费级GPU、手机和Raspberry Pi等边缘设备上的部署验证了PLM的实用性。
🎯 应用场景
PLM适用于各种边缘计算场景,例如智能家居、可穿戴设备、自动驾驶、工业物联网等。它能够在资源受限的设备上实现自然语言处理任务,例如语音识别、文本生成、机器翻译等,从而为用户提供更智能、更便捷的服务。PLM的低资源消耗特性使其能够大规模部署在各种边缘设备上,推动边缘智能的发展。
📄 摘要(原文)
While scaling laws have been continuously validated in large language models (LLMs) with increasing model parameters, the inherent tension between the inference demands of LLMs and the limited resources of edge devices poses a critical challenge to the development of edge intelligence. Recently, numerous small language models have emerged, aiming to distill the capabilities of LLMs into smaller footprints. However, these models often retain the fundamental architectural principles of their larger counterparts, still imposing considerable strain on the storage and bandwidth capacities of edge devices. In this paper, we introduce the PLM, a Peripheral Language Model, developed through a co-design process that jointly optimizes model architecture and edge system constraints. The PLM utilizes a Multi-head Latent Attention mechanism and employs the squared ReLU activation function to encourage sparsity, thereby reducing peak memory footprint during inference. During training, we collect and reorganize open-source datasets, implement a multi-phase training strategy, and empirically investigate the Warmup-Stable-Decay-Constant (WSDC) learning rate scheduler. Additionally, we incorporate Reinforcement Learning from Human Feedback (RLHF) by adopting the ARIES preference learning approach. Following a two-phase SFT process, this method yields performance gains of 2% in general tasks, 9% in the GSM8K task, and 11% in coding tasks. In addition to its novel architecture, evaluation results demonstrate that PLM outperforms existing small language models trained on publicly available data while maintaining the lowest number of activated parameters. Furthermore, deployment across various edge devices, including consumer-grade GPUs, mobile phones, and Raspberry Pis, validates PLM's suitability for peripheral applications. The PLM series models are publicly available at https://github.com/plm-team/PLM.