TLUE: A Tibetan Language Understanding Evaluation Benchmark
作者: Fan Gao, Cheng Huang, Nyima Tashi, Xiangxiang Wang, Thupten Tsering, Ban Ma-bao, Renzeg Duojie, Gadeng Luosang, Rinchen Dongrub, Dorje Tashi, Hao Wang Xiao Feng, Yongbin Yu
分类: cs.CL
发布日期: 2025-03-15 (更新: 2025-10-02)
备注: Accepted by EMNLP Main Conference (Poster)
💡 一句话要点
提出TLUE:首个大规模藏语理解评估基准,用于评估LLM在藏语上的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 藏语理解 低资源语言 评估基准 大型语言模型 多任务学习
📋 核心要点
- 现有LLM在藏语等低资源语言上的评估不足,无法准确衡量其藏语理解能力。
- 构建大规模藏语理解评估基准TLUE,包含多任务理解和安全两个方面,覆盖多个领域。
- 实验结果表明,现有LLM在TLUE上的表现远低于预期,凸显了藏语处理的挑战。
📝 摘要(中文)
近年来,大型语言模型取得了显著进展,但像藏语这样的低资源语言在评估中仍然严重不足。尽管有超过七百万人使用藏语,但在大型语言模型的开发和评估中,藏语在很大程度上被忽视了。为了解决这一差距,我们提出了藏语语言理解评估基准(TLUE),这是第一个用于衡量LLM在藏语能力的大规模基准。TLUE包含两个主要组成部分:一个全面的多任务理解基准,跨越5个领域和67个子领域;以及一个包含7个子领域的安全基准。然后,我们评估了一组不同的最先进的大型语言模型。实验结果表明,大多数大型语言模型的性能低于随机基线,突显了它们在藏语处理方面面临的巨大挑战。TLUE为推进未来藏语理解研究提供了关键基础,并强调了在大型语言模型开发中促进更大包容性的重要性。
🔬 方法详解
问题定义:现有大型语言模型(LLM)在通用语言任务上表现出色,但在低资源语言(如藏语)上的性能评估严重不足。缺乏专门针对藏语的评估基准,导致无法有效衡量和提升LLM在藏语上的理解能力。现有方法无法准确反映LLM在藏语特定领域的表现,阻碍了藏语自然语言处理的发展。
核心思路:论文的核心思路是构建一个大规模、全面的藏语语言理解评估基准(TLUE),以系统地评估LLM在藏语上的能力。通过设计多任务理解和安全基准,覆盖多个领域和子领域,从而更全面地衡量LLM的藏语理解水平。该基准旨在为未来的藏语自然语言处理研究提供基础,并促进LLM在低资源语言上的发展。
技术框架:TLUE基准主要包含两个组成部分:多任务理解基准和安全基准。多任务理解基准涵盖5个领域和67个子领域,旨在评估LLM在不同藏语理解任务上的表现。安全基准包含7个子领域,用于评估LLM在藏语环境下的安全性,例如是否存在有害或不当内容。研究人员使用TLUE对一系列最先进的LLM进行评估,并分析其在不同任务上的表现。
关键创新:TLUE是首个大规模的藏语语言理解评估基准,填补了低资源语言评估领域的空白。它不仅包含多任务理解基准,还考虑了安全因素,从而更全面地评估LLM在藏语环境下的表现。TLUE的构建为未来的藏语自然语言处理研究提供了重要的资源和评估工具。
关键设计:TLUE的多任务理解基准涵盖了广泛的藏语理解任务,包括文本分类、问答、文本生成等。每个任务都包含大量的藏语数据,以确保评估的可靠性和有效性。安全基准的设计考虑了藏语环境下的特殊情况,例如藏传佛教相关的伦理问题。研究人员在构建TLUE时,充分考虑了藏语的语言特点和文化背景,以确保基准的准确性和适用性。
🖼️ 关键图片

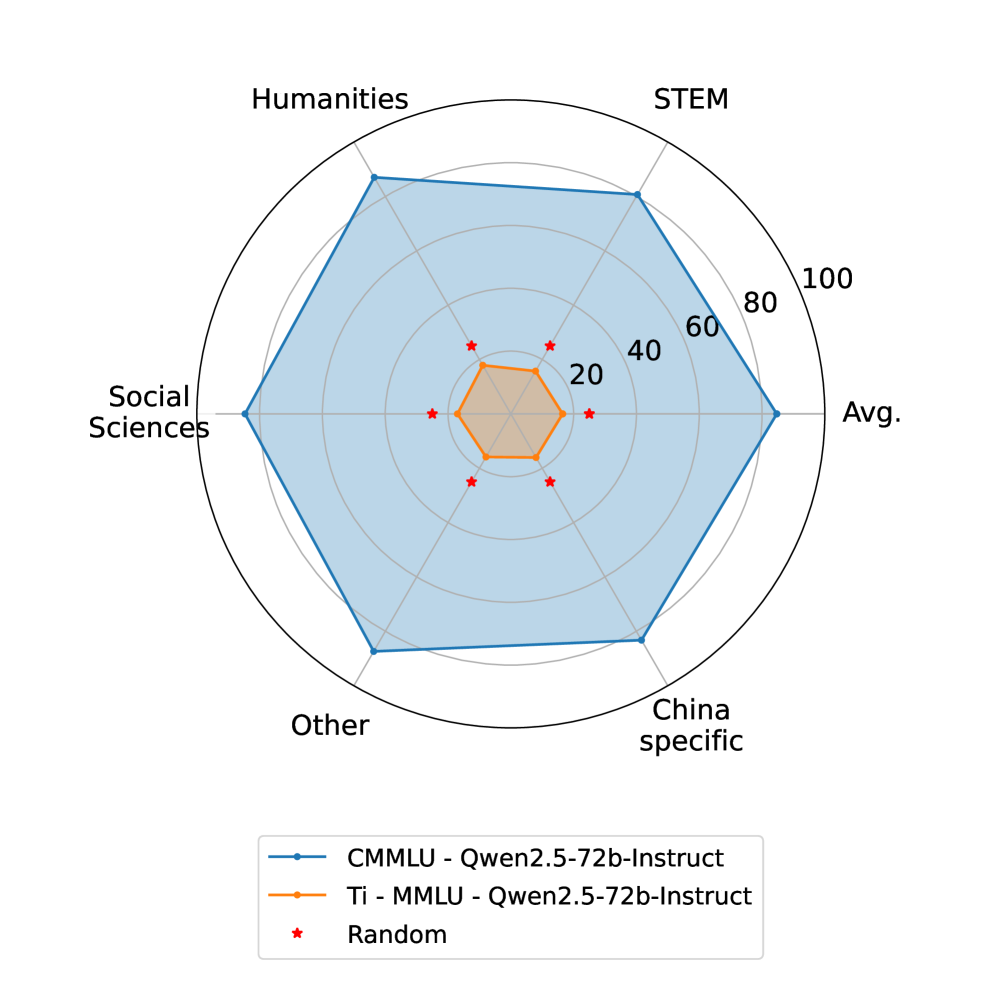
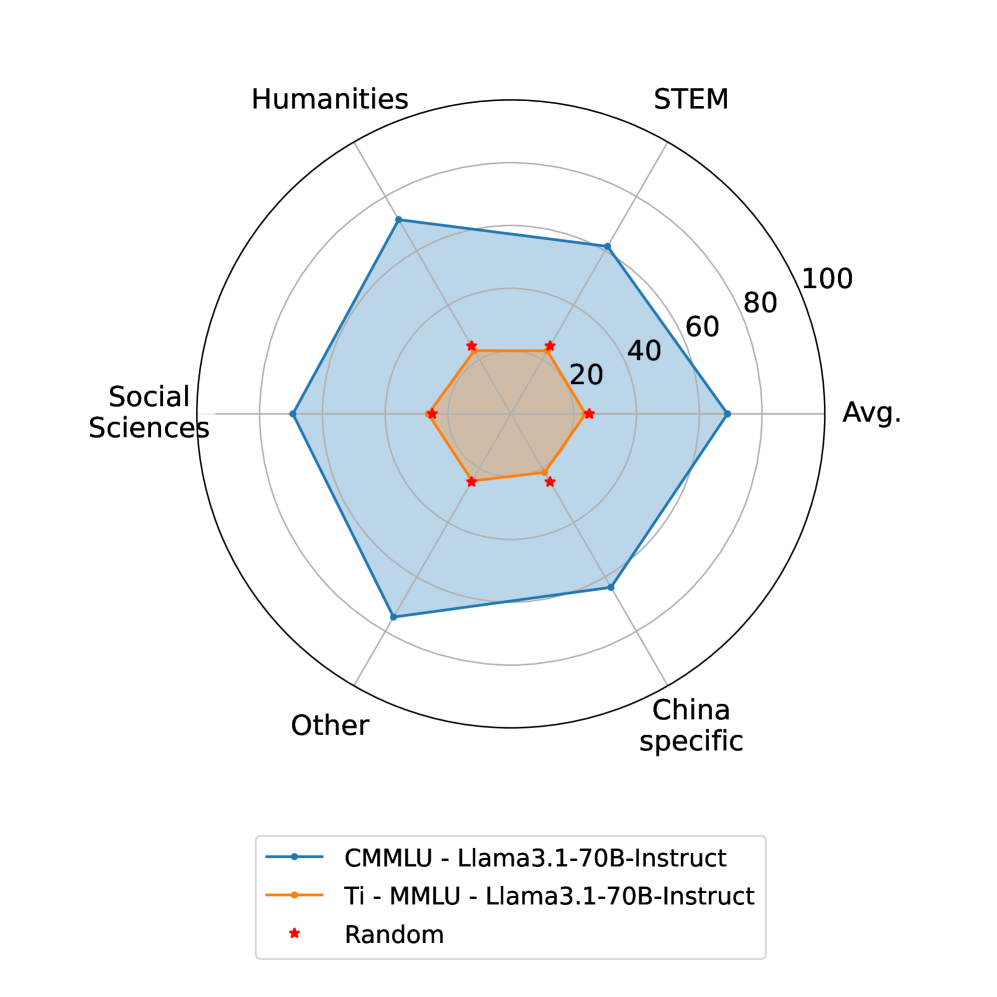
📊 实验亮点
实验结果显示,现有的大型语言模型在TLUE基准上的表现普遍低于随机基线,表明这些模型在藏语理解方面存在显著的不足。这一结果突显了在低资源语言上开发和评估LLM的挑战性,并强调了TLUE基准的重要性。TLUE为未来的藏语自然语言处理研究提供了一个重要的评估平台。
🎯 应用场景
TLUE基准的潜在应用领域包括:藏语机器翻译、藏语信息检索、藏语智能客服、藏语教育等。该研究的实际价值在于促进藏语自然语言处理技术的发展,提高LLM在藏语上的应用能力,并为藏族人民提供更便捷的智能服务。未来,TLUE可以作为评估和改进藏语LLM的重要工具,推动藏语数字化和信息化进程。
📄 摘要(原文)
Large language models have made tremendous progress in recent years, but low-resource languages, like Tibetan, remain significantly underrepresented in their evaluation. Despite Tibetan being spoken by over seven million people, it has largely been neglected in the development and assessment of large language models. To address this gap, we present a \textbf{T}ibetan \textbf{L}anguage \textbf{U}nderstanding \textbf{E}valuation Benchmark, \textbf{TLUE}, the first large-scale benchmark for measuring the proficiency of LLMs in the Tibetan language. \textbf{TLUE} comprises two major components: a comprehensive multi-task understanding benchmark spanning 5 domains and 67 subdomains, and a safety benchmark encompassing 7 subdomains. Then, we evaluate a diverse set of state-of-the-art large language models. Experimental results demonstrate that most large language models perform below the random baseline, highlighting the considerable challenges they face in Tibetan language processing. \textbf{TLUE} provides a crucial foundation for advancing future research in Tibetan language understanding and highlights the importance of promoting greater inclusivity in the development of large language models.