OpeNLGauge: An Explainable Metric for NLG Evaluation with Open-Weights LLMs
作者: Ivan Kartáč, Mateusz Lango, Ondřej Dušek
分类: cs.CL
发布日期: 2025-03-14 (更新: 2025-11-18)
备注: INLG 2025
💡 一句话要点
OpeNLGauge:一种基于开源LLM的、可解释的NLG评估指标。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: NLG评估 大型语言模型 开源 可解释性 错误跨度 自然语言生成 参考无关
📋 核心要点
- 现有基于LLM的NLG评估指标依赖于专有模型,缺乏细粒度的、可解释的反馈。
- OpeNLGauge利用开源LLM,通过错误跨度提供精确解释,实现完全开源且无需参考的评估。
- 实验表明,OpeNLGauge与人类判断具有竞争力,并在特定任务上优于现有模型,同时提供更准确的解释。
📝 摘要(中文)
本文提出了一种完全开源、无需参考的NLG评估指标OpeNLGauge,它能够提供基于错误跨度的精确解释。OpeNLGauge可以作为一个由大型开源LLM组成的两阶段集成模型使用,也可以作为一个小型微调评估模型使用,并且已被证实具有对未见任务、领域和方面的泛化能力。广泛的元评估表明,OpeNLGauge与人类判断具有竞争力的相关性,在某些任务上优于最先进的模型,同时保持完全的可重复性,并提供准确性提高两倍以上的解释。
🔬 方法详解
问题定义:现有基于LLM的NLG评估指标主要依赖于闭源的专有模型,这限制了其可访问性和可重复性。此外,这些指标通常缺乏细粒度的解释性,难以帮助用户理解评估结果并改进NLG系统。因此,需要一种开源、可解释的NLG评估指标。
核心思路:OpeNLGauge的核心思路是利用开源的大型语言模型(LLMs)进行NLG评估,并提供基于错误跨度的解释。通过开源LLM,可以保证评估过程的可访问性和可重复性。通过错误跨度,可以提供细粒度的解释,帮助用户理解评估结果。
技术框架:OpeNLGauge有两种实现方式:一种是两阶段集成模型,由多个大型开源LLM组成;另一种是小型微调评估模型。两阶段集成模型首先使用一个LLM识别错误跨度,然后使用另一个LLM基于错误跨度进行评估。小型微调评估模型则直接进行评估和解释。两种实现方式都旨在提供准确且可解释的评估结果。
关键创新:OpeNLGauge的关键创新在于其完全开源、无需参考,并且能够提供基于错误跨度的解释。与现有方法相比,OpeNLGauge避免了对专有模型的依赖,提高了可访问性和可重复性。同时,OpeNLGauge提供的解释更加细粒度,有助于用户理解评估结果。
关键设计:OpeNLGauge使用了开源的LLMs,例如未知具体模型。在两阶段集成模型中,第一阶段的LLM用于识别错误跨度,可以使用序列标注模型或生成模型。第二阶段的LLM基于错误跨度进行评估,可以使用回归模型或排序模型。小型微调评估模型则直接进行评估和解释,可以使用序列到序列模型或分类模型。具体的损失函数和网络结构取决于所使用的LLM和任务类型。
🖼️ 关键图片

📊 实验亮点
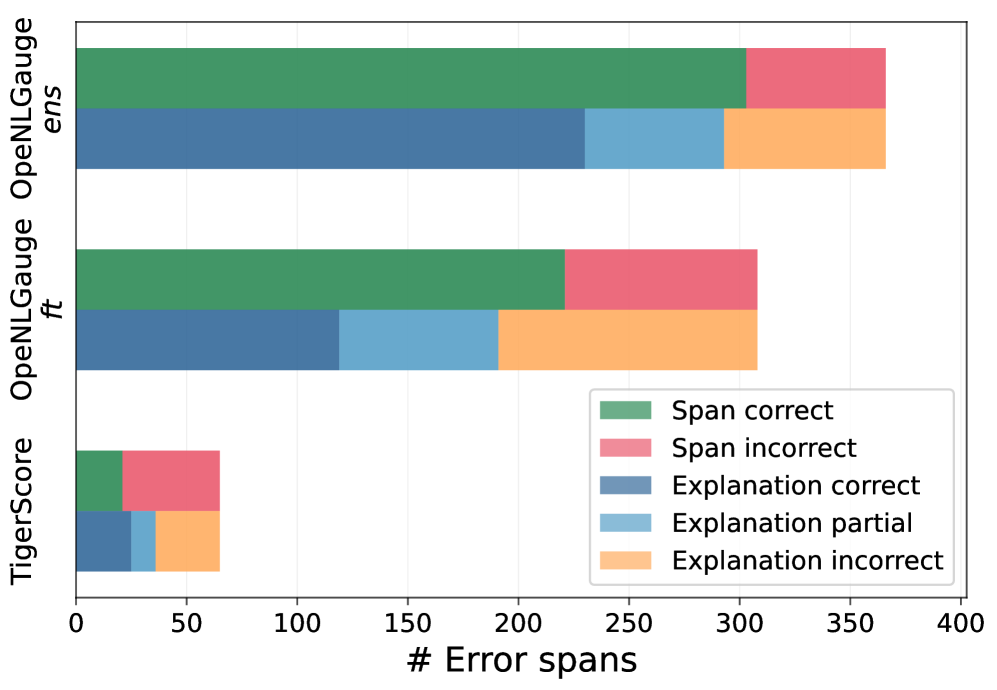
OpeNLGauge在多个NLG评估任务上进行了评估,结果表明其与人类判断具有竞争力的相关性,在某些任务上优于最先进的模型。此外,OpeNLGauge提供的解释比现有方法准确两倍以上。这些结果表明OpeNLGauge是一种有效的NLG评估指标。
🎯 应用场景
OpeNLGauge可应用于各种自然语言生成任务的评估,例如机器翻译、文本摘要、对话生成等。它可以帮助研究人员和开发者快速评估NLG系统的性能,并提供可解释的反馈,从而改进NLG系统。由于其开源特性,OpeNLGauge可以被广泛应用于学术研究和工业界。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated great potential as evaluators of NLG systems, allowing for high-quality, reference-free, and multi-aspect assessments. However, existing LLM-based metrics suffer from two major drawbacks: reliance on proprietary models to generate training data or perform evaluations, and a lack of fine-grained, explanatory feedback. In this paper, we introduce OpeNLGauge, a fully open-source, reference-free NLG evaluation metric that provides accurate explanations based on error spans. OpeNLGauge is available as a two-stage ensemble of larger open-weight LLMs, or as a small fine-tuned evaluation model, with confirmed generalizability to unseen tasks, domains and aspects. Our extensive meta-evaluation shows that OpeNLGauge achieves competitive correlation with human judgments, outperforming state-of-the-art models on certain tasks while maintaining full reproducibility and providing explanations more than twice as accurate.