Bridging the LLM Accessibility Divide? Performance, Fairness, and Cost of Closed versus Open LLMs for Automated Essay Scoring
作者: Kezia Oketch, John P. Lalor, Yi Yang, Ahmed Abbasi
分类: cs.CL
发布日期: 2025-03-14
💡 一句话要点
对比闭源与开源LLM在自动作文评分中的表现、公平性和成本,揭示开源模型的潜力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自动作文评分 开源模型 公平性 成本效益 少样本学习 教育应用
📋 核心要点
- 现有闭源LLM虽然性能优异,但在可用性、成本和透明度方面存在局限性,阻碍了其广泛应用。
- 该研究对比了闭源、开源和开放LLM在自动作文评分任务中的表现,旨在评估开源LLM是否能弥补可访问性差距。
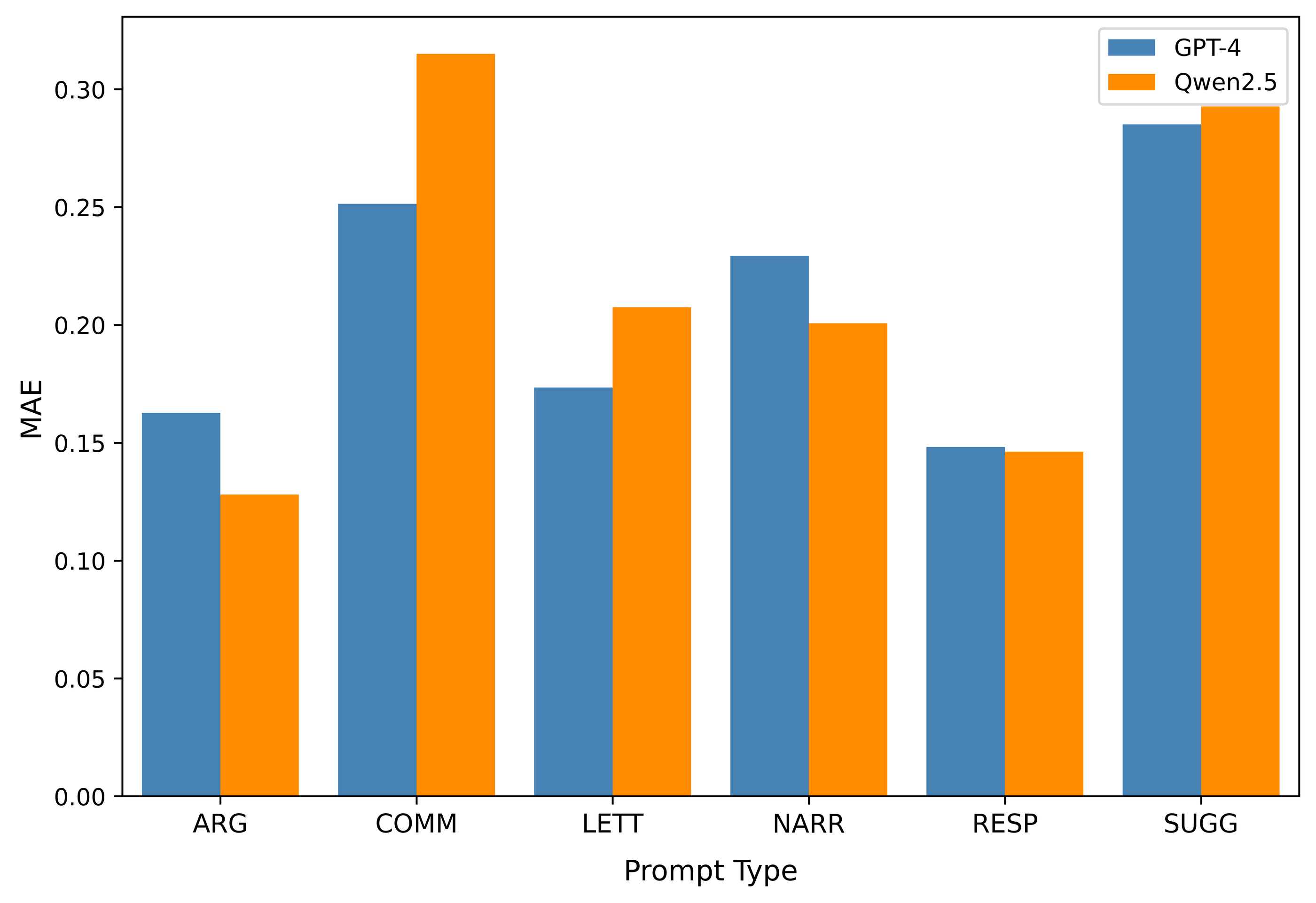
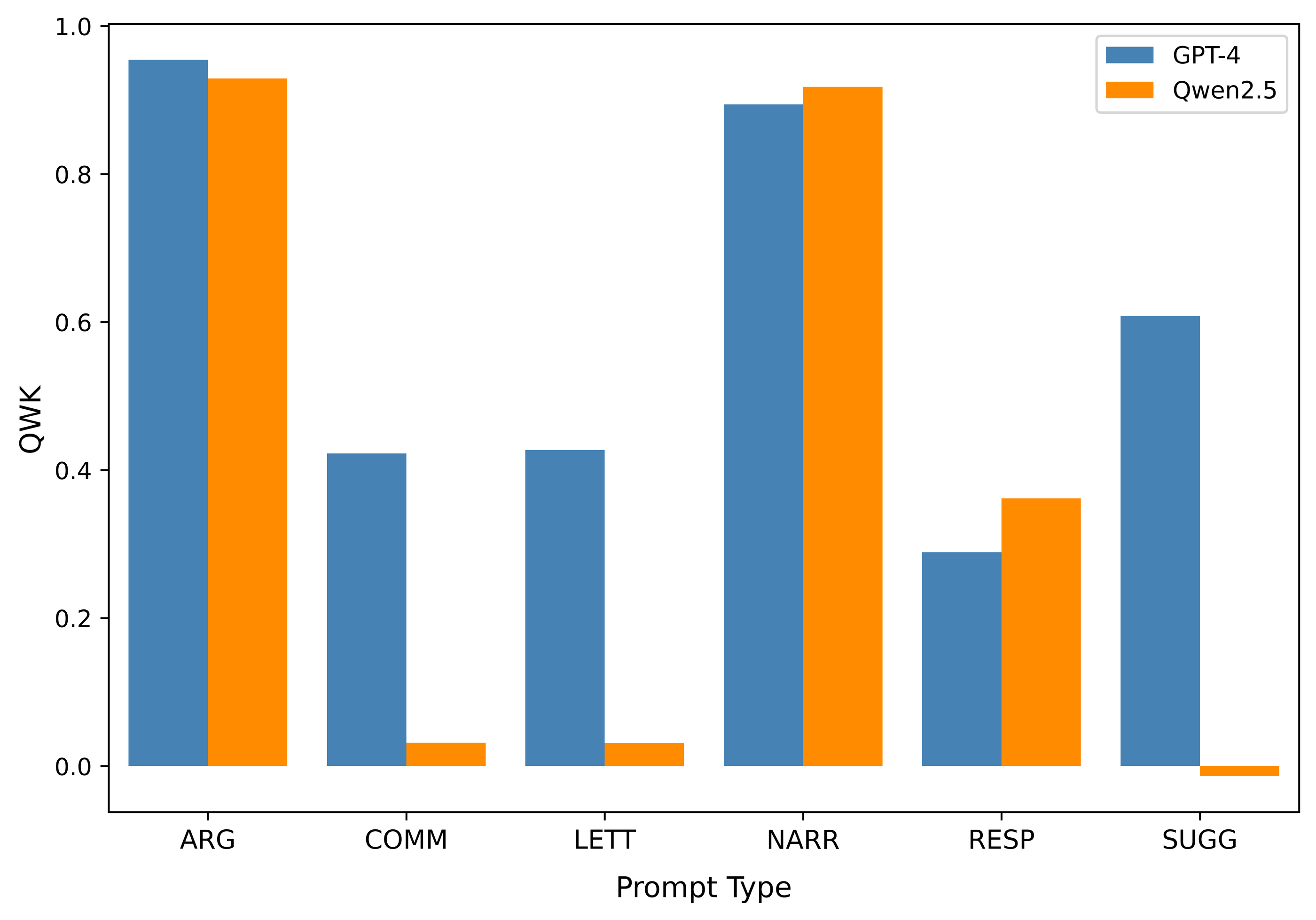
- 实验表明,在作文评估和生成任务中,部分开源LLM的性能、公平性和成本效益可与闭源LLM相媲美。
📝 摘要(中文)
闭源大型语言模型(LLM),如GPT-4,在多项NLP任务中取得了领先成果,并成为NLP和机器学习驱动解决方案的核心。闭源LLM的性能和广泛应用引发了关于其在可用性、成本和透明度方面的可访问性的讨论。本研究对九个领先的LLM(包括闭源、开源和开放LLM生态系统)在与自动作文评分相关的文本评估和生成任务中进行了严格的比较分析。研究结果表明,对于基于少样本学习的人工作文评估,Llama 3和Qwen2.5等开放LLM在预测性能方面与GPT-4相当,并且在考虑年龄或种族相关的公平性时,差异影响得分没有显著差异。此外,Llama 3提供了显著的成本优势,成本效益是GPT-4的37倍。对于生成任务,我们发现顶级开放LLM生成的文章在语义组成/嵌入和ML评估分数方面与闭源LLM相当。我们的研究结果挑战了闭源LLM的主导地位,并突出了开放LLM的民主化潜力,表明它们可以在保持竞争性能和公平性的同时,有效地弥合可访问性差距。
🔬 方法详解
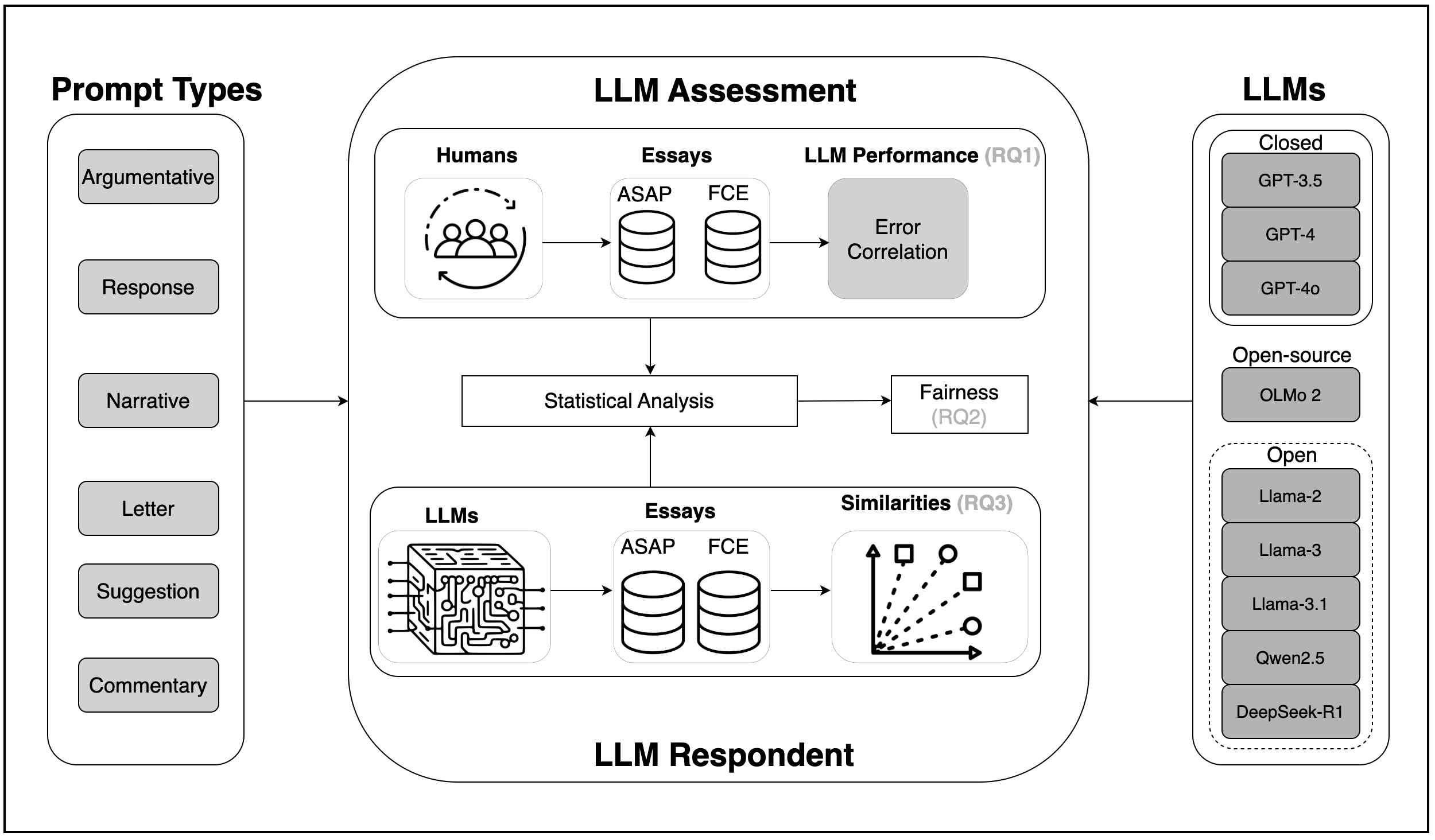
问题定义:论文旨在解决闭源LLM在自动作文评分应用中存在的成本高昂、可访问性差的问题。现有方法依赖于闭源LLM,使得相关技术和应用难以普及,尤其是在资源有限的教育场景中。
核心思路:论文的核心思路是通过对比分析闭源和开源LLM在自动作文评分任务中的表现,验证开源LLM是否能够在保证性能和公平性的前提下,提供更经济、更易于访问的替代方案。通过实证研究,揭示开源LLM的潜力,打破闭源LLM的垄断。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择代表性的闭源、开源和开放LLM;2) 构建自动作文评分相关的文本评估和生成任务;3) 使用少样本学习方法评估LLM在作文评估任务中的预测性能和公平性;4) 评估LLM生成的作文在语义组成和ML评估分数方面的表现;5) 对比不同LLM的成本效益。
关键创新:该研究的关键创新在于系统性地对比了闭源和开源LLM在自动作文评分这一特定应用场景下的性能、公平性和成本,并量化了开源LLM的优势。以往的研究可能侧重于通用NLP任务,而本研究聚焦于教育领域的具体应用,更具针对性。
关键设计:在实验设计方面,论文采用了少样本学习方法,以模拟实际应用中数据有限的场景。同时,使用了多种指标来评估LLM的性能,包括预测准确率、公平性指标(如差异影响得分)和成本效益。此外,还对LLM生成的作文进行了语义分析和ML评估,以全面评估其质量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Llama 3和Qwen2.5等开源LLM在作文评估任务中,预测性能与GPT-4相当,且在公平性方面没有显著差异。更重要的是,Llama 3的成本效益是GPT-4的37倍,这突显了开源LLM在降低成本方面的巨大潜力。
🎯 应用场景
该研究成果可应用于教育领域,为自动作文评分系统提供更经济、更易于访问的解决方案。开源LLM的应用可以降低教育机构的运营成本,并促进教育资源的公平分配。此外,该研究也为其他NLP任务中开源LLM的应用提供了参考。
📄 摘要(原文)
Closed large language models (LLMs) such as GPT-4 have set state-of-the-art results across a number of NLP tasks and have become central to NLP and machine learning (ML)-driven solutions. Closed LLMs' performance and wide adoption has sparked considerable debate about their accessibility in terms of availability, cost, and transparency. In this study, we perform a rigorous comparative analysis of nine leading LLMs, spanning closed, open, and open-source LLM ecosystems, across text assessment and generation tasks related to automated essay scoring. Our findings reveal that for few-shot learning-based assessment of human generated essays, open LLMs such as Llama 3 and Qwen2.5 perform comparably to GPT-4 in terms of predictive performance, with no significant differences in disparate impact scores when considering age- or race-related fairness. Moreover, Llama 3 offers a substantial cost advantage, being up to 37 times more cost-efficient than GPT-4. For generative tasks, we find that essays generated by top open LLMs are comparable to closed LLMs in terms of their semantic composition/embeddings and ML assessed scores. Our findings challenge the dominance of closed LLMs and highlight the democratizing potential of open LLMs, suggesting they can effectively bridge accessibility divides while maintaining competitive performance and fairness.