AIstorian lets AI be a historian: A KG-powered multi-agent system for accurate biography generation
作者: Fengyu Li, Yilin Li, Junhao Zhu, Lu Chen, Yanfei Zhang, Jia Zhou, Hui Zu, Jingwen Zhao, Yunjun Gao
分类: cs.CL, cs.AI
发布日期: 2025-03-14
🔗 代码/项目: GITHUB
💡 一句话要点
AIstorian:基于知识图谱的多Agent系统,用于生成准确的历史人物传记
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱 多Agent系统 传记生成 检索增强生成 反幻觉 历史研究 风格迁移
📋 核心要点
- 现有大型语言模型在生成历史人物传记时,难以保证文体一致性、事实准确性,且难以处理碎片化信息。
- AIstorian通过知识图谱增强的检索、多Agent协同的事实性校验和风格迁移微调,提升传记生成质量。
- 实验表明,AIstorian在事实准确性上提升了3.8倍,幻觉率降低了47.6%,显著优于现有方法。
📝 摘要(中文)
华为致力于探索人工智能在历史研究中的应用。传记生成作为一种特殊的抽象摘要形式,在历史研究中起着关键作用,但也面临着现有大型语言模型(LLMs)难以解决的独特挑战。这些挑战包括保持与历史写作规范的文体一致性、确保事实准确性以及处理跨多个文档的碎片化信息。我们提出了AIstorian,一种新颖的端到端Agent系统,其特点是基于知识图谱(KG)的检索增强生成(RAG)和反幻觉多Agent。具体来说,AIstorian引入了一种基于上下文学习的分块策略和基于KG的索引,用于准确高效的参考检索。同时,AIstorian协调多个Agent进行即时幻觉检测和错误类型感知校正。此外,为了教会LLM特定的语言风格,我们基于一种结合数据增强增强的监督微调与文体偏好优化的两步训练方法来微调LLM。在真实的历史进士数据集上的大量实验表明,与现有基线相比,AIstorian在事实准确性方面实现了3.8倍的提升,幻觉率降低了47.6%。数据和代码可在https://github.com/ZJU-DAILY/AIstorian获取。
🔬 方法详解
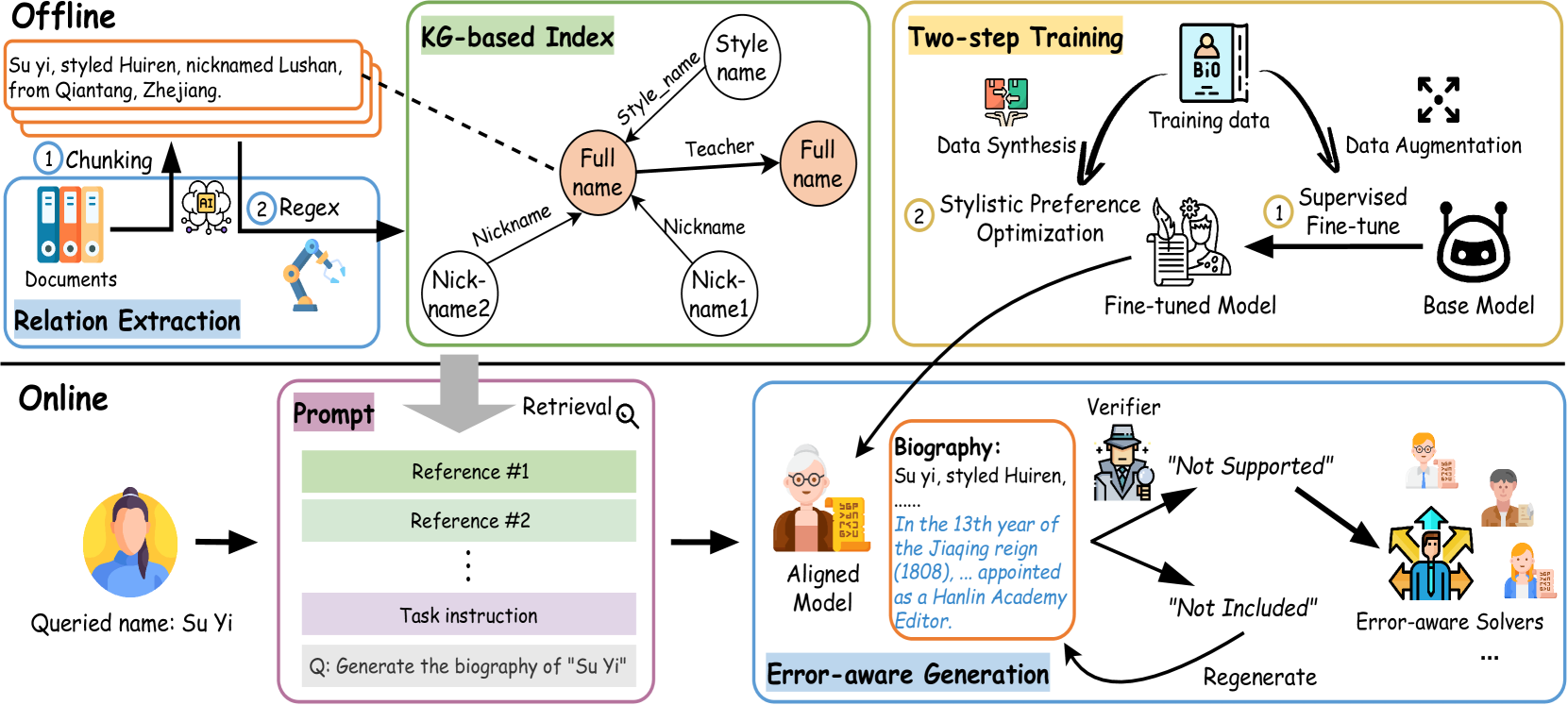
问题定义:论文旨在解决历史人物传记自动生成的问题。现有的大型语言模型在处理该任务时,面临着三个主要的痛点:一是难以保持历史写作的文体风格;二是容易产生事实性错误(幻觉);三是难以有效地整合来自多个文档的碎片化信息。这些问题导致生成的传记质量不高,难以满足历史研究的需求。
核心思路:论文的核心思路是构建一个基于知识图谱(KG)的多Agent系统,利用KG进行精确的知识检索,并通过多个Agent协同工作,进行幻觉检测和错误纠正,同时采用风格迁移技术,使生成的传记更符合历史写作的规范。这种设计旨在提高传记的事实准确性和文体质量。
技术框架:AIstorian的整体架构是一个端到端的Agent系统,主要包含以下几个模块:1) 基于上下文学习的分块策略,用于将输入文档分割成更小的语义单元;2) 基于知识图谱的索引,用于高效地检索相关的历史知识;3) 多Agent协同模块,包含幻觉检测Agent和错误类型感知校正Agent,用于检测和纠正生成内容中的错误;4) 风格迁移模块,通过两步训练方法,使LLM学习历史写作的风格。整个流程是:输入文档经过分块后,通过KG索引检索相关知识,然后由LLM生成传记初稿,再由多Agent模块进行事实性校验和纠正,最后通过风格迁移模块进行润色。
关键创新:该论文的关键创新点在于:1) 提出了一个基于知识图谱的多Agent系统,用于解决历史人物传记生成中的事实性错误问题;2) 引入了一种基于上下文学习的分块策略,提高了知识检索的准确性;3) 设计了一种错误类型感知的校正Agent,能够根据不同的错误类型进行针对性的纠正;4) 提出了一种两步训练方法,用于使LLM学习历史写作的风格。
关键设计:在分块策略中,使用了基于上下文学习的方法来确定最佳的分块大小。在知识图谱索引中,使用了预训练的知识图谱嵌入模型来表示实体和关系。在多Agent模块中,幻觉检测Agent使用了基于规则和基于模型的两种方法,错误类型感知校正Agent使用了基于生成的方法,根据不同的错误类型生成相应的修正语句。在风格迁移模块中,第一步使用数据增强增强的监督微调,第二步使用风格偏好优化,损失函数包括内容损失和风格损失。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AIstorian在真实的历史进士数据集上取得了显著的性能提升。与现有基线相比,AIstorian在事实准确性方面实现了3.8倍的提升,幻觉率降低了47.6%。这些数据表明,AIstorian能够有效地提高历史人物传记的生成质量,减少事实性错误,使其更符合历史研究的需求。
🎯 应用场景
AIstorian可应用于历史研究、教育和文化传承等领域。它可以帮助历史研究者快速生成人物传记,提高研究效率。在教育领域,可以作为辅助教学工具,帮助学生更好地了解历史人物。在文化传承方面,可以用于生成各种历史人物的传记,促进历史文化的传播和推广。未来,该技术还可以扩展到其他领域的文本生成任务,例如新闻报道、小说创作等。
📄 摘要(原文)
Huawei has always been committed to exploring the AI application in historical research. Biography generation, as a specialized form of abstractive summarization, plays a crucial role in historical research but faces unique challenges that existing large language models (LLMs) struggle to address. These challenges include maintaining stylistic adherence to historical writing conventions, ensuring factual fidelity, and handling fragmented information across multiple documents. We present AIstorian, a novel end-to-end agentic system featured with a knowledge graph (KG)-powered retrieval-augmented generation (RAG) and anti-hallucination multi-agents. Specifically, AIstorian introduces an in-context learning based chunking strategy and a KG-based index for accurate and efficient reference retrieval. Meanwhile, AIstorian orchestrates multi-agents to conduct on-the-fly hallucination detection and error-type-aware correction. Additionally, to teach LLMs a certain language style, we finetune LLMs based on a two-step training approach combining data augmentation-enhanced supervised fine-tuning with stylistic preference optimization. Extensive experiments on a real-life historical Jinshi dataset demonstrate that AIstorian achieves a 3.8x improvement in factual accuracy and a 47.6% reduction in hallucination rate compared to existing baselines. The data and code are available at: https://github.com/ZJU-DAILY/AIstorian.