Are formal and functional linguistic mechanisms dissociated in language models?
作者: Michael Hanna, Yonatan Belinkov, Sandro Pezzelle
分类: cs.CL
发布日期: 2025-03-14 (更新: 2025-08-28)
备注: To appear in Computational Linguistics. Pre-MIT Press publication version. 40 pages, 14 figures, 3 tables. Code available at https://github.com/hannamw/formal-functional-dissociation
💡 一句话要点
研究揭示:大型语言模型中形式语言和功能语言机制并非完全分离且缺乏统一的形式语言网络。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 形式语言 功能语言 电路发现 机制分析
📋 核心要点
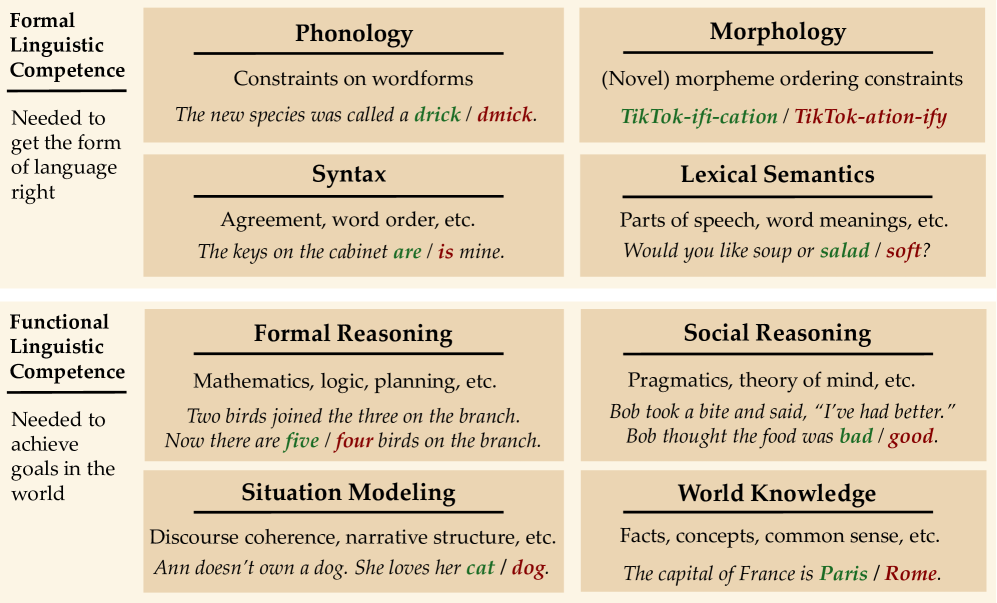
- 现有大型语言模型在形式语言任务上表现出色,但在功能语言任务上存在不足,需要探索其内部机制。
- 该研究通过寻找和比较负责不同任务的“电路”,分析LLM中形式和功能语言机制的定位情况。
- 实验结果表明,形式和功能任务的电路重叠较少,但形式语言任务之间也缺乏统一的网络结构。
📝 摘要(中文)
大型语言模型(LLM)的能力日益增强,但这些能力分布不均:它们擅长形式语言任务,如生成流畅、符合语法的文本,但在推理和一致的事实检索等功能语言任务方面表现较差。受神经科学的启发,最近的研究表明,为了在形式和功能语言任务上都取得成功,LLM应该为每种任务使用不同的机制;这种定位可以是内置的,也可以通过训练自发产生。本文旨在探究:当前模型,在功能语言能力快速提升的同时,是否表现出形式和功能语言机制的明显定位?通过寻找和比较负责各种形式和功能任务的“电路”或最小计算子图来回答这个问题。比较了5个LLM在10个不同任务上的表现,发现形式和功能任务的电路之间确实几乎没有重叠,但形式语言任务之间也几乎没有重叠,这与人脑的情况不同。因此,一个统一的、与功能任务电路不同的单一形式语言网络仍然难以捉摸。然而,在跨任务忠实度(一个电路解决另一个任务的能力)方面,观察到形式和功能机制之间存在分离,这表明形式任务之间可能存在共享机制。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在处理形式语言(如语法和流畅性)和功能语言(如推理和事实检索)时,是否使用了不同的内部机制。现有研究表明LLM在两种任务上的表现存在差异,但缺乏对其内部机制差异的深入理解。现有方法难以有效区分和定位LLM中负责不同语言功能的计算子图。
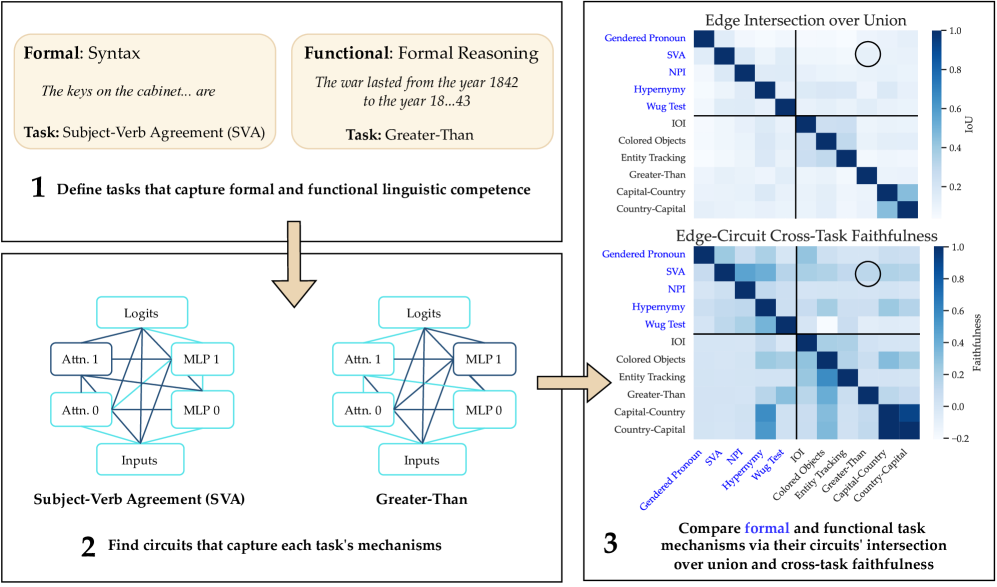
核心思路:论文的核心思路是通过识别和比较LLM中执行不同形式和功能语言任务的最小计算子图,即“电路”,来分析这些任务是否由不同的机制处理。如果形式和功能语言任务由不同的机制处理,那么它们对应的电路应该具有较小的重叠。通过分析电路的重叠程度和跨任务的泛化能力,可以推断LLM中是否存在针对特定语言功能的模块化结构。
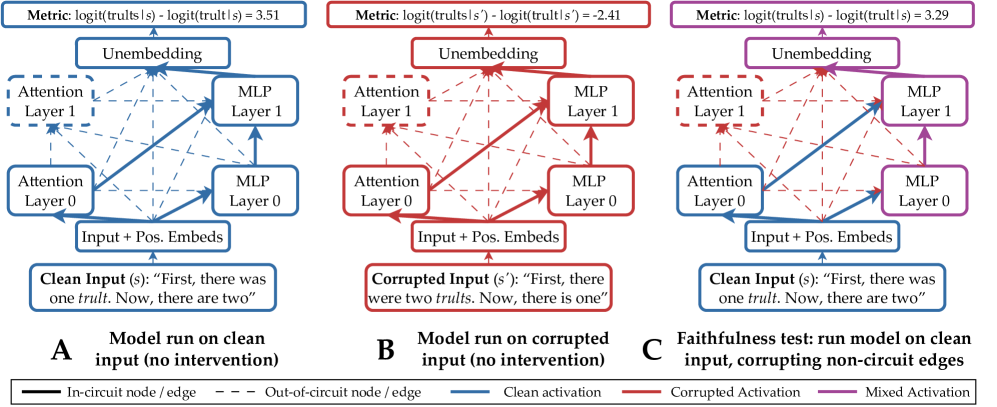
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择具有代表性的LLM和形式/功能语言任务;2) 使用电路发现技术,识别每个任务对应的最小计算子图;3) 计算不同任务电路之间的重叠程度,评估它们之间的相似性;4) 通过跨任务忠实度测试,评估一个任务的电路解决另一个任务的能力;5) 分析实验结果,推断LLM中是否存在针对形式和功能语言任务的独立机制。
关键创新:该研究的关键创新在于将电路发现技术应用于分析LLM中的语言机制,并首次系统地比较了形式和功能语言任务的电路。通过这种方法,研究人员能够更深入地了解LLM如何处理不同类型的语言任务,并揭示其内部机制的模块化程度。此外,该研究还提出了跨任务忠实度作为评估电路泛化能力的指标。
关键设计:研究选择了5个LLM和10个不同的形式/功能语言任务。电路发现技术使用了现有的算法,例如因果追踪。电路重叠程度的计算使用了Jaccard指数。跨任务忠实度通过评估一个任务的电路在另一个任务上的性能来衡量。具体参数设置和损失函数取决于所使用的电路发现算法和LLM的架构。
🖼️ 关键图片
📊 实验亮点
研究发现,形式语言任务和功能语言任务的电路之间重叠较少,表明LLM在处理这两种任务时使用了不同的机制。然而,形式语言任务之间也缺乏明显的统一网络结构,这与人脑的组织方式不同。在跨任务忠实度方面,观察到形式和功能机制之间存在分离,暗示形式任务之间可能存在共享机制。这些发现为理解LLM的内部工作机制提供了新的视角。
🎯 应用场景
该研究的成果可应用于改进大型语言模型的设计,使其在形式和功能语言任务上都能表现出色。通过理解LLM内部机制的模块化程度,可以开发更有效的训练方法和架构,从而提高LLM的推理能力和事实检索能力。此外,该研究还可以帮助我们更好地理解人类语言处理的神经机制。
📄 摘要(原文)
Although large language models (LLMs) are increasingly capable, these capabilities are unevenly distributed: they excel at formal linguistic tasks, such as producing fluent, grammatical text, but struggle more with functional linguistic tasks like reasoning and consistent fact retrieval. Inspired by neuroscience, recent work suggests that to succeed on both formal and functional linguistic tasks, LLMs should use different mechanisms for each; such localization could either be built-in or emerge spontaneously through training. In this paper, we ask: do current models, with fast-improving functional linguistic abilities, exhibit distinct localization of formal and functional linguistic mechanisms? We answer this by finding and comparing the "circuits", or minimal computational subgraphs, responsible for various formal and functional tasks. Comparing 5 LLMs across 10 distinct tasks, we find that while there is indeed little overlap between circuits for formal and functional tasks, there is also little overlap between formal linguistic tasks, as exists in the human brain. Thus, a single formal linguistic network, unified and distinct from functional task circuits, remains elusive. However, in terms of cross-task faithfulness - the ability of one circuit to solve another's task - we observe a separation between formal and functional mechanisms, suggesting that shared mechanisms between formal tasks may exist.