HyperDAS: Towards Automating Mechanistic Interpretability with Hypernetworks
作者: Jiuding Sun, Jing Huang, Sidharth Baskaran, Karel D'Oosterlinck, Christopher Potts, Michael Sklar, Atticus Geiger
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-13 (更新: 2025-04-25)
备注: ICLR 2025
💡 一句话要点
HyperDAS:利用超网络自动实现机制可解释性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机制可解释性 超网络 Transformer 概念解耦 分布式对齐搜索
📋 核心要点
- 现有分布式对齐搜索(DAS)方法在寻找概念特征时需要进行暴力搜索,计算成本高昂。
- HyperDAS利用Transformer超网络自动定位概念相关的token位置,并构建相应的残差流向量特征。
- 实验表明,HyperDAS在Llama3-8B上,RAVEL基准测试中,概念解耦性能达到SOTA。
📝 摘要(中文)
机制可解释性在识别神经网络特征(例如,隐藏激活空间中的方向)方面取得了显著进展,这些特征可以调节概念(例如,一个人的出生年份)并实现可预测的操作。分布式对齐搜索(DAS)利用来自反事实数据的监督来学习隐藏状态中的概念特征,但DAS假设我们可以负担得起对潜在特征位置进行暴力搜索。为了解决这个问题,我们提出了HyperDAS,这是一种基于Transformer的超网络架构,它可以:(1)自动定位残差流中实现概念的token位置;(2)为该概念构建这些残差流向量的特征。在使用Llama3-8B的实验中,HyperDAS在RAVEL基准测试中实现了最先进的性能,用于解开隐藏状态中的概念。此外,我们回顾了我们所做的设计决策,以减轻HyperDAS(像所有强大的可解释性方法一样)可能将新信息注入目标模型而不是忠实地解释它的担忧。
🔬 方法详解
问题定义:论文旨在解决机制可解释性中,如何高效地定位神经网络中与特定概念相关的特征的问题。现有方法,如分布式对齐搜索(DAS),需要对所有可能的特征位置进行暴力搜索,计算成本巨大,难以应用于大型模型。因此,如何自动且高效地找到这些关键特征位置是本研究要解决的核心问题。
核心思路:论文的核心思路是利用超网络(Hypernetwork)来预测目标模型中概念相关的特征位置和特征向量。超网络接收输入(例如,提示词),并生成目标模型中特定层和token位置的权重,这些权重用于构建与目标概念相关的特征。通过这种方式,避免了对所有位置进行搜索,从而提高了效率。
技术框架:HyperDAS的整体架构包含以下几个主要模块:1) 输入编码器:将输入提示词编码成向量表示。2) 超网络:一个Transformer网络,接收编码后的提示词,并预测目标模型中每个token位置的权重。3) 特征构建器:使用超网络预测的权重,对目标模型中相应位置的残差流向量进行加权组合,从而构建概念特征。4) 损失函数:使用反事实数据进行监督,训练超网络,使其能够准确地定位和构建概念特征。
关键创新:HyperDAS的关键创新在于使用超网络自动定位概念相关的token位置,并构建相应的特征。与传统的暴力搜索方法相比,HyperDAS能够显著提高效率,并能够应用于更大的模型。此外,论文还特别关注了如何避免超网络将新信息注入到目标模型中,从而保证解释的忠实性。
关键设计:HyperDAS的关键设计包括:1) 使用Transformer作为超网络,以捕捉输入提示词和目标模型内部状态之间的复杂关系。2) 使用反事实数据作为监督信号,训练超网络,使其能够准确地定位和构建概念特征。3) 设计了特定的损失函数,以鼓励超网络学习到稀疏的权重,从而提高特征的可解释性。4) 采用了多种技术手段,例如权重衰减和dropout,以防止超网络过拟合,并保证解释的忠实性。
🖼️ 关键图片

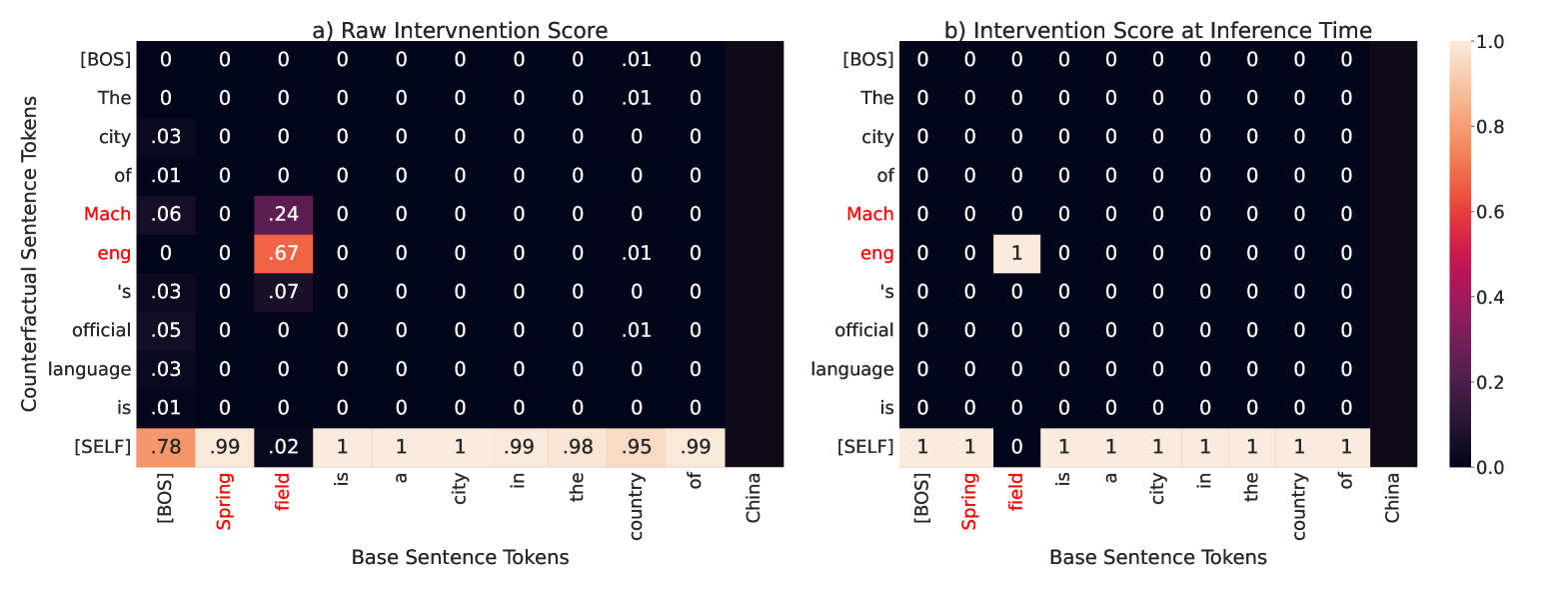

📊 实验亮点
HyperDAS在RAVEL基准测试中,针对Llama3-8B模型,实现了最先进的概念解耦性能。实验结果表明,HyperDAS能够有效地定位和构建与特定概念相关的特征,并且优于现有的分布式对齐搜索(DAS)方法。这证明了HyperDAS在自动化机制可解释性方面的有效性。
🎯 应用场景
HyperDAS可应用于各种需要理解和控制大型语言模型的场景,例如:1) 提升模型的可解释性和可控性,方便用户理解模型的决策过程。2) 安全性应用,例如识别和消除模型中的有害偏见。3) 模型编辑,通过修改模型内部的特定概念特征,实现对模型行为的精确控制。4) 知识发现,帮助研究人员发现模型内部蕴含的知识。
📄 摘要(原文)
Mechanistic interpretability has made great strides in identifying neural network features (e.g., directions in hidden activation space) that mediate concepts(e.g., the birth year of a person) and enable predictable manipulation. Distributed alignment search (DAS) leverages supervision from counterfactual data to learn concept features within hidden states, but DAS assumes we can afford to conduct a brute force search over potential feature locations. To address this, we present HyperDAS, a transformer-based hypernetwork architecture that (1) automatically locates the token-positions of the residual stream that a concept is realized in and (2) constructs features of those residual stream vectors for the concept. In experiments with Llama3-8B, HyperDAS achieves state-of-the-art performance on the RAVEL benchmark for disentangling concepts in hidden states. In addition, we review the design decisions we made to mitigate the concern that HyperDAS (like all powerful interpretabilty methods) might inject new information into the target model rather than faithfully interpreting it.