ZSMerge: Zero-Shot KV Cache Compression for Memory-Efficient Long-Context LLMs
作者: Xin Liu, Xudong Wang, Pei Liu, Guoming Tang
分类: cs.CL, cs.AI
发布日期: 2025-03-13 (更新: 2025-10-05)
🔗 代码/项目: GITHUB
💡 一句话要点
ZSMerge:面向长文本LLM的零样本KV缓存压缩,提升内存效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存压缩 长文本处理 大型语言模型 零样本学习 内存效率
📋 核心要点
- 长文本处理中,LLM的KV缓存线性增长和注意力机制的二次复杂度是主要瓶颈,现有方法常因token剪枝或特征合并导致信息不可逆损失或需昂贵的重训练。
- ZSMerge通过细粒度内存分配、残差合并机制和零样本自适应机制,实现了高效的KV缓存压缩,无需重新训练即可兼容多种LLM架构。
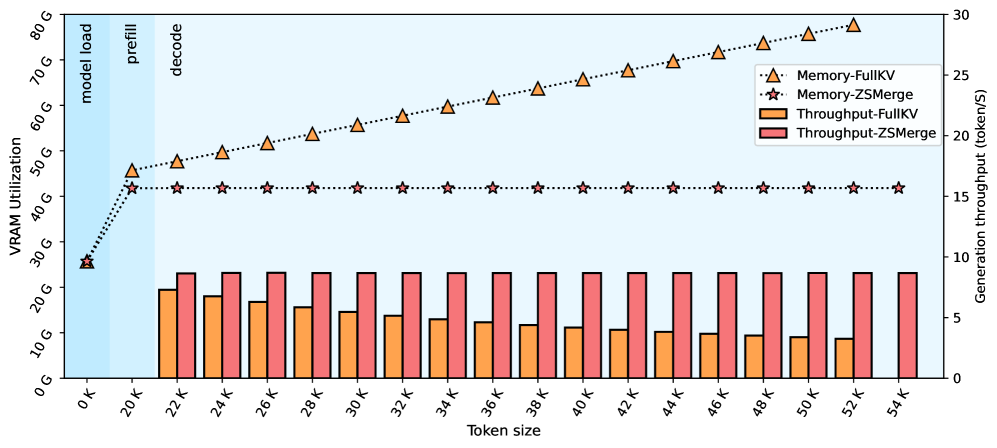
- 实验表明,ZSMerge在LLaMA2-7B上实现了20:1的KV缓存压缩率,同时保持了相当的生成质量,并在54k-token上下文中实现了三倍的吞吐量提升。
📝 摘要(中文)
针对长文本处理中大型语言模型(LLM)的键值(KV)缓存内存线性增长和注意力机制的二次计算复杂度带来的瓶颈,本文提出了ZSMerge,一个动态KV缓存压缩框架,旨在实现高效的缓存管理。该框架包含三个关键操作:(1)由head级别粒度的多维token重要性指标指导的细粒度内存分配;(2)通过补偿注意力评分来保留关键上下文的残差合并机制;(3)与各种LLM架构兼容且无需重新训练的零样本自适应机制。ZSMerge显著提高了内存效率和推理速度,同时在LLM上性能下降可忽略不计。应用于LLaMA2-7B时,它展示了20:1的键值缓存保留压缩率(将内存占用减少到基线的5%),同时保持了相当的生成质量,并在极端的54k-token上下文中实现了三倍的吞吐量提升,消除了内存不足的故障。
🔬 方法详解
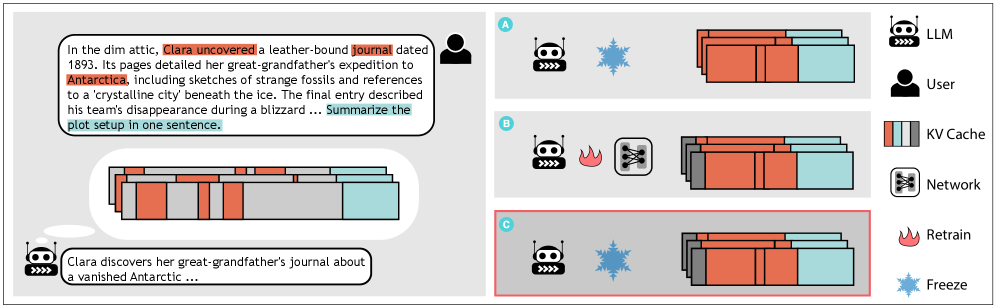
问题定义:论文旨在解决长文本LLM推理过程中KV缓存占用内存过大的问题。现有方法,如token剪枝或特征合并,要么造成不可逆的信息损失,要么需要针对特定模型进行昂贵的重新训练,通用性和效率都存在不足。
核心思路:ZSMerge的核心思路是在保证模型性能的前提下,动态地压缩KV缓存。它通过细粒度的token重要性评估,优先保留重要的上下文信息,并采用残差合并机制来补偿压缩带来的信息损失,同时设计零样本自适应机制,使其能够直接应用于不同的LLM架构,无需重新训练。
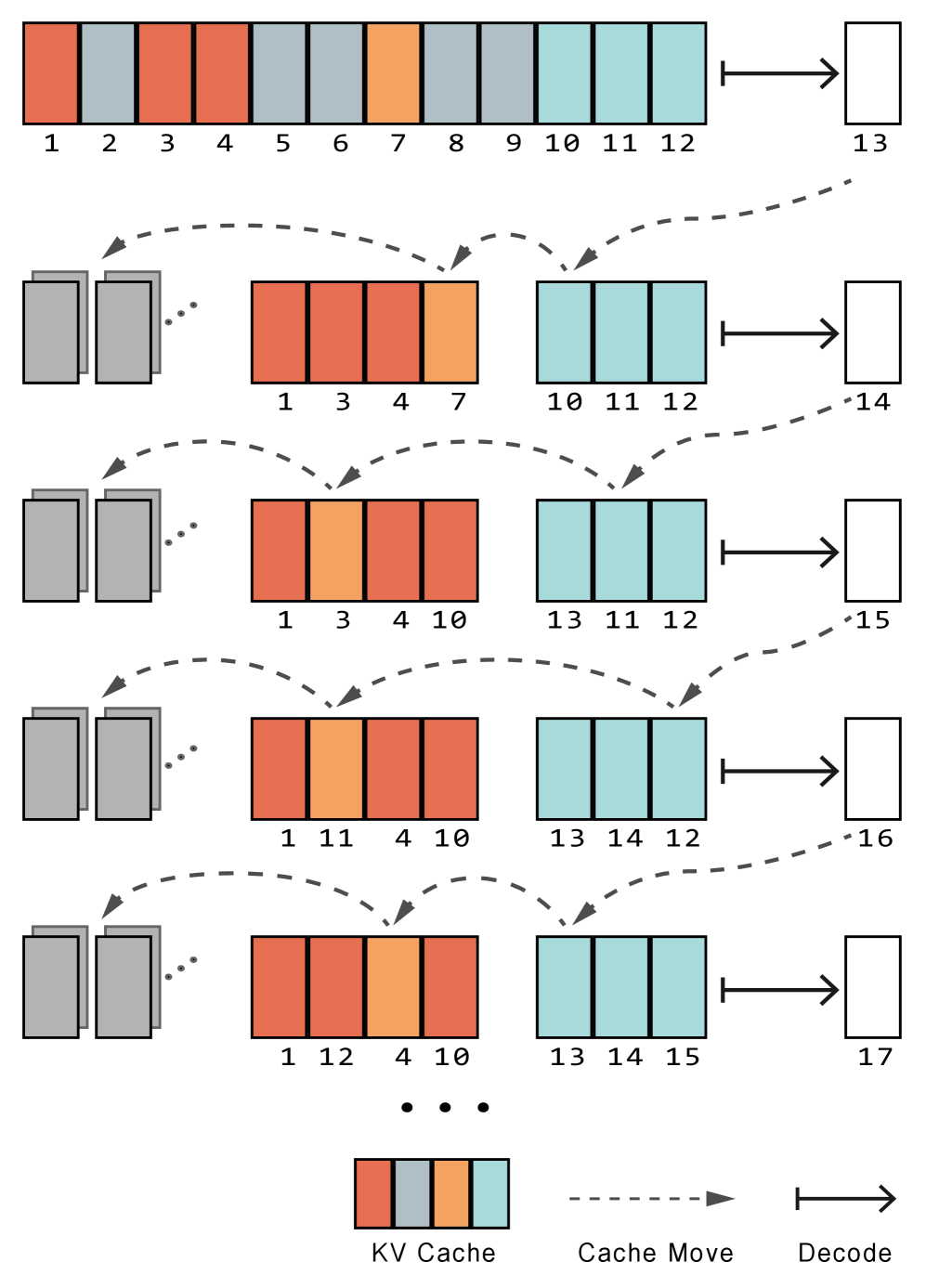
技术框架:ZSMerge框架包含三个主要模块:1) 细粒度内存分配:根据多维token重要性指标,在head级别进行细粒度的内存分配,优先保留重要性高的token。2) 残差合并机制:通过补偿注意力评分来保留关键上下文,减少信息损失。3) 零样本自适应机制:无需重新训练即可兼容不同的LLM架构。整体流程是,首先对输入token进行重要性评估,然后根据重要性进行KV缓存的压缩和合并,最后通过残差补偿来提高性能。
关键创新:ZSMerge的关键创新在于其动态的KV缓存压缩策略和零样本自适应能力。与静态压缩方法不同,ZSMerge能够根据token的重要性动态调整压缩比例,从而更好地保留关键信息。此外,零样本自适应机制使其能够直接应用于不同的LLM,无需针对特定模型进行训练,大大提高了通用性和效率。
关键设计:ZSMerge的关键设计包括:1) 多维token重要性指标:论文定义了多个维度来评估token的重要性,例如注意力权重、梯度等。2) 残差合并的补偿机制:通过调整注意力评分来补偿合并操作带来的信息损失。3) 零样本自适应的实现方式:具体实现细节未知,但强调了其与不同LLM架构的兼容性。
🖼️ 关键图片
📊 实验亮点
ZSMerge在LLaMA2-7B上实现了显著的性能提升。实验结果表明,ZSMerge能够实现20:1的KV缓存压缩率,将内存占用降低到基线的5%,同时保持了与原始模型相当的生成质量。在处理54k-token的极端长文本时,ZSMerge实现了三倍的吞吐量提升,并成功避免了内存溢出错误。
🎯 应用场景
ZSMerge可应用于各种需要处理长文本的场景,例如长篇文档摘要、长对话生成、代码生成等。通过降低内存需求,ZSMerge使得在资源受限的设备上运行大型语言模型成为可能,并可以显著提高长文本处理的效率。该技术还有助于降低云计算成本,并推动LLM在更多实际场景中的应用。
📄 摘要(原文)
The linear growth of key-value (KV) cache memory and quadratic computational in attention mechanisms complexity pose significant bottlenecks for large language models (LLMs) in long-context processing. While existing KV cache optimization methods address these challenges through token pruning or feature merging, they often incur irreversible information loss or require costly parameter retraining. To this end, we propose ZSMerge, a dynamic KV cache compression framework designed for efficient cache management, featuring three key operations: (1) fine-grained memory allocation guided by multi-dimensional token importance metrics at head-level granularity, (2) a residual merging mechanism that preserves critical context through compensated attention scoring, and (3) a zero-shot adaptation mechanism compatible with diverse LLM architectures without requiring retraining. ZSMerge significantly enhances memory efficiency and inference speed with negligible performance degradation across LLMs. When applied to LLaMA2-7B, it demonstrates a 20:1 compression ratio for key-value cache retention (reducing memory footprint to 5\% of baseline) while sustaining comparable generation quality, coupled with triple throughput gains at extreme 54k-token contexts that eliminate out-of-memory failures. The code is available at https://github.com/SusCom-Lab/ZSMerge.