Cognitive-Mental-LLM: Evaluating Reasoning in Large Language Models for Mental Health Prediction via Online Text
作者: Avinash Patil, Amardeep Kour Gedhu
分类: cs.CL, cs.AI
发布日期: 2025-03-13 (更新: 2026-01-07)
备注: 8 pages, 4 Figures, 3 tables
💡 一句话要点
利用思维链LLM提升在线文本心理健康预测的推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心理健康预测 大型语言模型 思维链 文本分类 推理增强 提示工程 自然语言处理
📋 核心要点
- 现有心理健康预测方法缺乏可解释性和鲁棒性,难以应对复杂情况。
- 论文提出利用思维链(CoT)等推理技术增强LLM,提升心理健康文本分类的准确性。
- 实验表明,推理增强的LLM在特定数据集上优于传统方法和微调模型,但数据集差异带来挑战。
📝 摘要(中文)
大型语言模型(LLMs)在预测在线文本中的心理健康结果方面展现出潜力,但传统的分类方法通常缺乏可解释性和鲁棒性。本研究评估了结构化推理技术——思维链(CoT)、自洽性(SC-CoT)和思维树(ToT),以提高来自Reddit的多个心理健康数据集的分类准确性。我们分析了推理驱动的提示策略,包括零样本CoT和少样本CoT,使用关键性能指标,如平衡准确率、F1分数和灵敏度/特异性。研究结果表明,推理增强技术优于直接预测,尤其是在复杂情况下。与零样本非CoT提示等基线,以及微调的预训练Transformer(如BERT和Mental-RoBerta)和微调的开源LLM(如Mental Alpaca和Mental-Flan-T5)相比,推理驱动的LLM在Dreaddit(比M-LLM高+0.52%,比BERT高+0.82%)和SDCNL(比M-LLM高+4.67%,比BERT高+2.17%)等数据集上产生了显著的收益。然而,在抑郁严重程度和CSSRS预测中,性能下降表明存在数据集特定的限制,这可能是由于我们使用了更广泛的测试集。在提示策略中,少样本CoT始终优于其他策略,这加强了推理驱动的LLM的有效性。尽管如此,数据集的可变性突出了模型可靠性和可解释性方面的挑战。本研究为心理健康文本分类提供了一个基于推理的LLM技术的综合基准,并深入了解了它们在可扩展临床应用中的潜力,同时确定了未来改进的关键挑战。
🔬 方法详解
问题定义:论文旨在解决利用大型语言模型(LLMs)从在线文本中预测心理健康状况时,传统分类方法缺乏可解释性和鲁棒性的问题。现有方法,如直接分类或微调的预训练模型,在处理复杂推理场景时表现不佳,难以提供清晰的决策过程。
核心思路:论文的核心思路是利用思维链(Chain-of-Thought, CoT)、自洽性(Self-Consistency, SC-CoT)和思维树(Tree-of-Thought, ToT)等结构化推理技术,引导LLM进行逐步推理,从而提高心理健康文本分类的准确性和可解释性。通过模拟人类的思考过程,使LLM能够更好地理解文本中的细微差别和上下文信息。
技术框架:整体框架包括数据预处理、提示工程和模型评估三个主要阶段。首先,对来自Reddit等平台的心理健康相关文本数据进行清洗和标注。然后,设计不同的提示策略,包括零样本CoT和少样本CoT,引导LLM进行推理。最后,使用平衡准确率、F1分数、灵敏度和特异性等指标评估模型的性能。
关键创新:论文的关键创新在于系统性地评估了多种推理增强技术在心理健康文本分类中的效果,并与传统方法和微调模型进行了对比。通过引入结构化推理,LLM能够更好地理解文本的深层含义,从而提高分类准确性和可解释性。此外,论文还探讨了不同提示策略对模型性能的影响,为实际应用提供了指导。
关键设计:关键设计包括:1) 提示工程:设计有效的提示语,引导LLM进行逐步推理,例如,在少样本CoT中,提供几个带有推理过程的示例;2) 模型选择:选择合适的LLM作为基础模型,例如,使用Mental Alpaca和Mental-Flan-T5等针对心理健康领域微调的开源LLM;3) 评估指标:使用平衡准确率、F1分数等综合指标评估模型的性能,避免单一指标带来的偏差。
🖼️ 关键图片
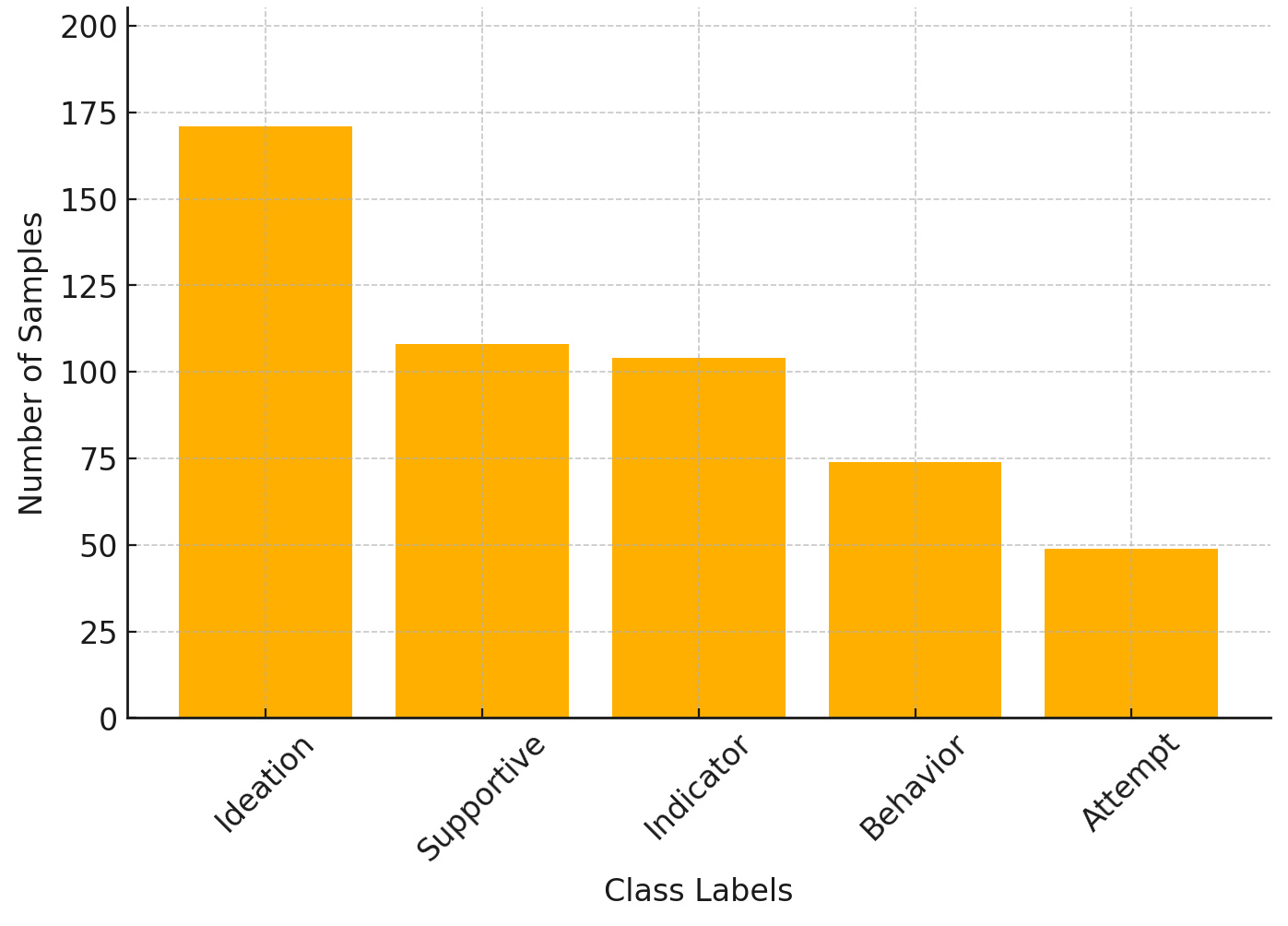
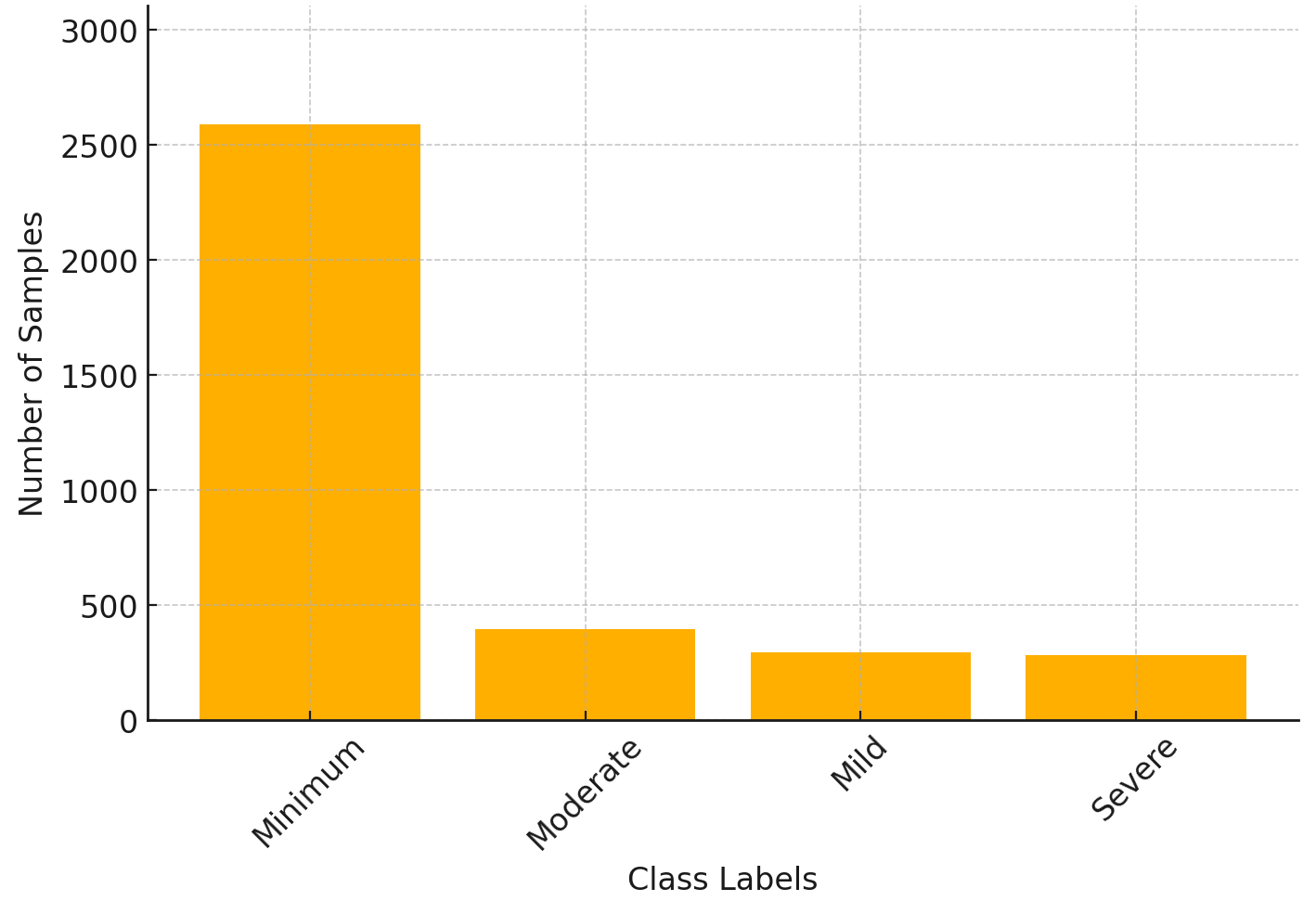
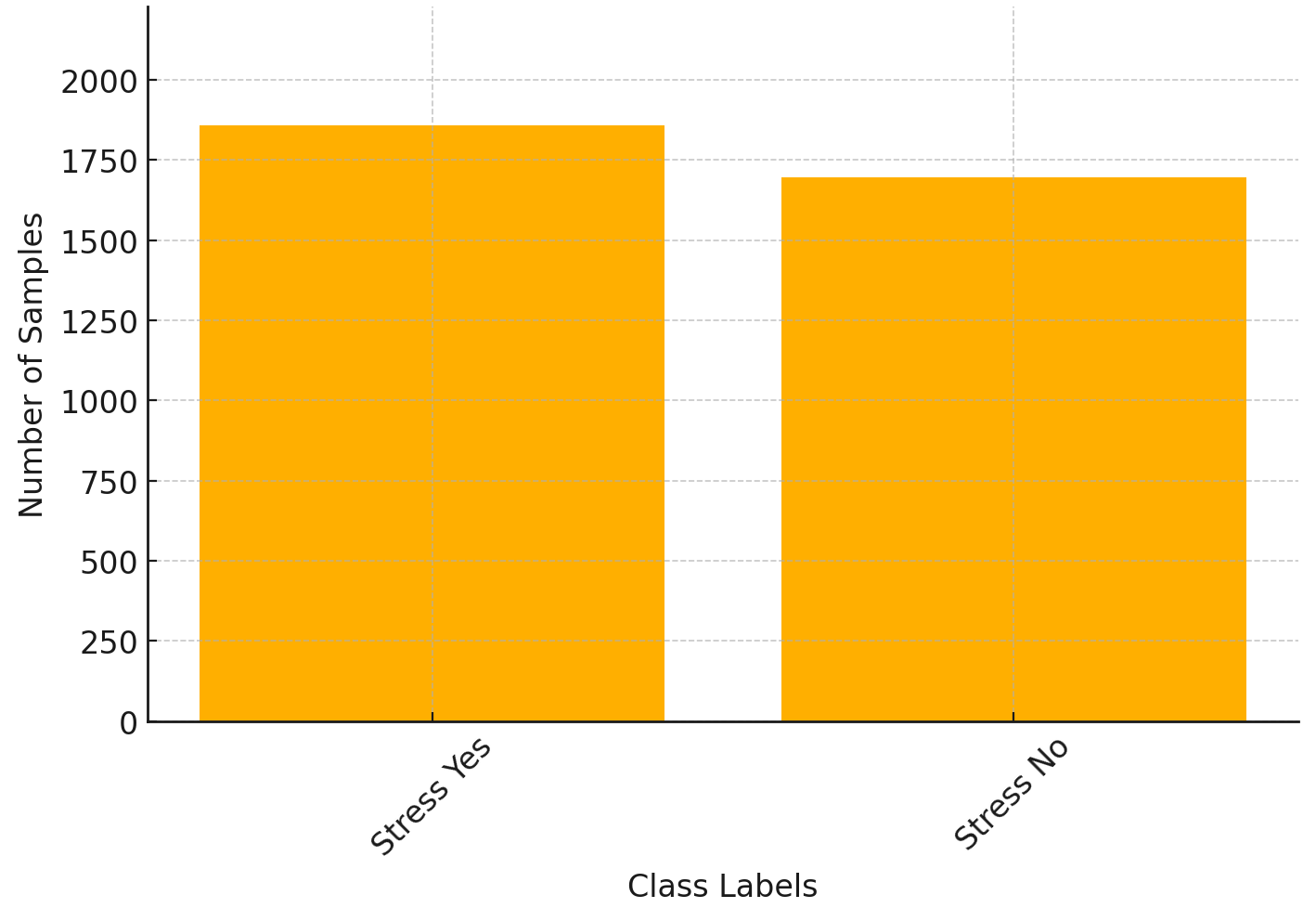
📊 实验亮点
实验结果表明,推理增强的LLM在Dreaddit和SDCNL数据集上优于传统方法和微调模型。例如,在Dreaddit数据集上,推理驱动的LLM比M-LLM高+0.52%,比BERT高+0.82%;在SDCNL数据集上,推理驱动的LLM比M-LLM高+4.67%,比BERT高+2.17%。少样本CoT策略始终优于其他策略,验证了推理驱动LLM的有效性。
🎯 应用场景
该研究成果可应用于在线心理健康筛查、风险评估和个性化干预等领域。通过分析社交媒体文本,可以及早发现潜在的心理健康问题,并为患者提供及时的支持和帮助。此外,该技术还可以用于评估心理健康干预措施的效果,为临床实践提供数据支持。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated potential in predicting mental health outcomes from online text, yet traditional classification methods often lack interpretability and robustness. This study evaluates structured reasoning techniques-Chain-of-Thought (CoT), Self-Consistency (SC-CoT), and Tree-of-Thought (ToT)-to improve classification accuracy across multiple mental health datasets sourced from Reddit. We analyze reasoning-driven prompting strategies, including Zero-shot CoT and Few-shot CoT, using key performance metrics such as Balanced Accuracy, F1 score, and Sensitivity/Specificity. Our findings indicate that reasoning-enhanced techniques improve classification performance over direct prediction, particularly in complex cases. Compared to baselines such as Zero Shot non-CoT Prompting, and fine-tuned pre-trained transformers such as BERT and Mental-RoBerta, and fine-tuned Open Source LLMs such as Mental Alpaca and Mental-Flan-T5, reasoning-driven LLMs yield notable gains on datasets like Dreaddit (+0.52\% over M-LLM, +0.82\% over BERT) and SDCNL (+4.67\% over M-LLM, +2.17\% over BERT). However, performance declines in Depression Severity, and CSSRS predictions suggest dataset-specific limitations, likely due to our using a more extensive test set. Among prompting strategies, Few-shot CoT consistently outperforms others, reinforcing the effectiveness of reasoning-driven LLMs. Nonetheless, dataset variability highlights challenges in model reliability and interpretability. This study provides a comprehensive benchmark of reasoning-based LLM techniques for mental health text classification. It offers insights into their potential for scalable clinical applications while identifying key challenges for future improvements.